
另类数据:投资中的怪咖

指数基金一般是小白投资理财的首选,可是,你是否知道指数基金背后的构造逻辑呢?
都说投资时不懂不要投,相信当我们了解了其背后的构造逻辑后,能够更好地选择基金产品,也能更安心地赚钱!
本文就带大家来了解一下构造指数基金背后的因子及构造因子的另类数据。
以下内容节选自《因子投资:方法与实践》一书!

自20世纪80年代末以来,业界开始把学术界的研究成果很好地落地,形成了许多风格因子指数,比如价值和成长因子。
1992年,先锋推出了第一支价值指数基金和第一支成长指数基金。这些指数基金一经推出便受到了追捧。人们把它们视作主动型价值投资的低成本替代品。
鉴于价值因子取得的巨大成功,业界也开始把关注的重点转移到学术界发现的其他因子,并构造出了一系列基金产品,造福了普通投资者。
对于主动型管理人来说,因子投资早已成为投资工具箱中的重要选择。
在实际围绕某个因子构建投资组合时,必须要考虑可投资性的约束,成功的因子投资需要注重从理论到实践的每一个细节。对于普通投资者来说,了解每个因子背后的原因,选择适合自己风险偏好的因子,以及使用合适的金融工具交易这些因子就成为重中之重。
但是,随着那些早已家喻户晓的因子被越来越多的人使用,很多因子的预期收益逐年降低(比如价值因子)。
面对这种局面,人们开始从尚未被过度使用的数据源中寻找构造因子的灵感,这些数据源就是另类数据。
然而,另类数据是否像想象中的一样好使呢?
美国时间2018年10月25日,困境中的特斯拉股票取得9.14% 的大涨,只因为在前一个交易日盘后发布的2018财年三季度财报大超华尔街预期。
财报显示,特斯拉的爆款车型Model 3的产量在过去一个季度较之前几乎翻番,这无疑给投资人注入了一剂强心针,也引得市场一片狂欢。
面对Model 3产量的大增和股票大涨反映出的市场信心,最高兴的人当属特斯拉的掌门人埃隆·马斯克。然而,除了马斯克,同样高兴的恐怕还有另外一群人,他们就是另类数据公司Thasos以及它的很多对冲基金客户。因为在特斯拉发布三季度财报之前,这群人大概早就凭借着信息优势预判到了这一点并提前布局。Thasos是怎么做到的?
他们在一张在线地图上环绕特斯拉位于美国加利福尼亚州Fremont 占地370英亩的工厂创建了一个数字围栏,以隔离从特斯拉工厂范围内发出的智能手机的位置信号。Thasos租赁了通过智能手机APP收集到的数万亿个地理坐标的数据库,并使用电脑程序密切监测从特斯拉工厂中发出的手机信号。利用手机信号量,他们发现从2018年6月到10月,特斯拉工厂夜间轮班时间增加了30%,因此推断特斯拉的产能得到了极大的提高。Thasos将这个数据分享给了它的一些对冲基金客户。毫无疑问,这一数据发挥了巨大的作用。它是将另类数据应用于二级市场投资的一个经典案例。
其实,另类数据并非什么新鲜概念。
在几十年前,当人们仅通过量价数据进行交易的时候,财务报表数据就是另类数据;当财务数据被广泛使用后,分析师一致预期就是另类数据;当分析师一致预期家喻户晓之后,网络舆情数据就成了另类数据;当人们对网络舆情不再陌生之后,非结构化的文本数据就变成了另类数据……
随着通过已有数据源构建因子并进行交易变得越来越“拥挤”,获得的超额收益越来越少,人们自然而然地将视线和希望转向新的另类数据上,希望通过独门数据源挖出新的 “阿尔法因子”。
这种迫切的需求也让另类数据在近几年得到了飞速的发展。
来自AlternativeData. org的数据显示,另类数据提供商的数量在最近五年出现了激增。每当人们接触到新的数据源的时候,通常的反应都是“两眼发光”。
诚然,在市场变得更加有效的今天,新的数据源无疑是尚未被过度使用的“净土”,充满了潜在的机会。
但是,另类数据真的像人们想象的那样前景一片光明吗?是否任意一个新的数据源都能拿过来加工出一个靠谱的因子?另类数据能否成为二级市场的“银色子弹”?
面对这些问题,海外业界不乏争议之声,有多少人支持就有多少人反对。
下面就来探讨关于另类数据的5点思考。
1. 技术和数据需匹配
关于另类数据的第一点思考是新的数据类型需要相应的分析技术。
当仅有价格和交易量数据的时候,传统的技术分析就能发挥很大的作用。然而,这些技术分析对结构化的会计报表数据却难有作为。为此,相应的分析手段也应运而生,比如多因子模型,而寻找因子本身可以算是一种模式识别。如今,如果想要分析非结构化文本数据以及更一般的多媒体数据,则需要更高级的技术,如自然语言处理和广义人工智能。
下图展示了不同数据类型和分析技术之间的对应关系。随着另类数据的发展,数据类型越来越复杂,这就要求使用者具备相应的分析技术,否则将无法发挥数据的优势。这对管理人和投资者都提出了更高的要求。
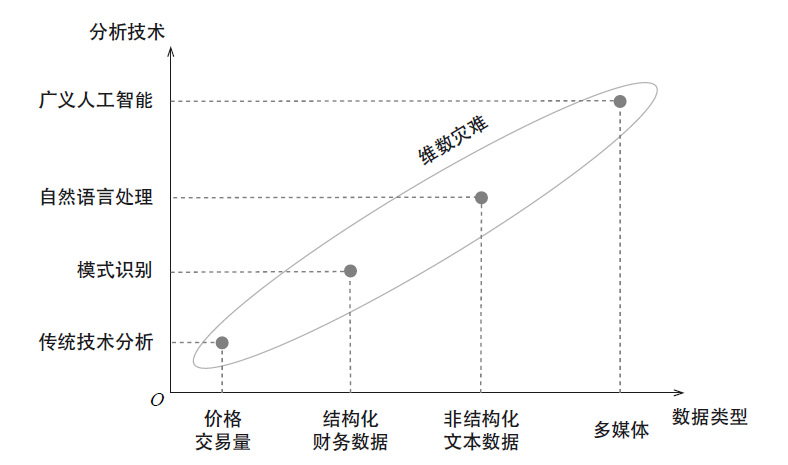
随着另类数据量的爆发,另一个需要面对的问题则是维数灾难。
以预测股票收益率为例,另类数据代表着不同的自变量。由于股票的样本数据就那么多,随着自变量的增加,股票样本数据在这些变量构成的空间内将会越来越稀疏。参数的激增使得预测模型存在更高的过拟合风险,且预测的偏差和方差都会变大。
此外,在使用不同另类数据构建因子时应注意避免多重假设检验问题。当使用大量不同另类数据集构建的因子分析同样的股票数据时,总会出现仅仅因为运气就十分显著的因子。这就要求人们从统计手段上要尽可能排除这种“幸运因子”,此外在金融业务上也需要真正理解另类数据和未来预期收益率之间的逻辑。这便引出了对另类数据的第二点思考——使用另类数据需要很强的专业知识。
2. 需要专业知识
全新的数据是一把“双刃剑”。
一方面,因为还没有人用过,所以它不存在“拥挤”的问题;另一方面,如果使用者不具备该数据分析所要求的专业知识,那很可能不知道从何处下手。在人们的想象中,另类数据也许是这样的:有令人兴奋的“故事”,而且是已经被数据供应商处理好的结构化数据,能够直接拿来当成因子去预测资产收益率。然而在现实中,另类数据更像是在一个没人去过的地方发现了一座山。而这座山里有没有矿、从哪里开始挖、到底能挖出什么,更多的要看使用者自己的本事。
在海外业界,实力充沛的大型资产管理公司具备足够的人才储备,往往自己进行数据分析。此外,另类数据供应商也会推出一些听上去十分有希望的应用场景来推销数据。除了买方、卖方,市场上也涌现出了第三方研究机构,投资者会委托他们进行另类数据的研究。
对于另类数据的使用者来说,使用供应商或者第三方提供的加工后的数据无疑是最方便的。但这种做法存在的问题是,这些应用场景会被卖给很多不同的使用者。这会增加另类数据的拥挤度,降低其在未来获取收益的能力。
因此,对于使用者来说,掌握专业知识包括另类数据的产生、背后的业务流程、金融学的含义等无疑至关重要。唯有此,才能掌握研究的主动权,并更有可能挖出“独门”的收益率预测变量。
在这方面,Lee针对美股,使用专利数据创造性地构建了科技关联度指标,获得了其他常见因子无法解释的超额收益。这个想法需要对专利数据背后代表的业务逻辑,以及公司之间的关联有深刻的认识。如果没有这种专业知识,只是把专利数据拿来简单地统计哪个公司专利多、哪个公司专利少,恐怕难以持续获得可观的超额收益。
3. 数据是否无偏
关于另类数据的第三点思考是,数据的生成(采集)过程是否无偏,能否很好地代表总体。
为了说明这一点,不妨来看一个例子。
Green使用Glassdoor.com数据研究了员工评价与股票收益率之间的关系。Glassdoor.com提供了员工对公司的综合评价和五个标准化评价指标,包括职业机会、薪酬福利、工作/生活平衡度、高层管理、企业文化与价值,所有评价皆为1至5星。
为了研究员工评价和股票收益率的关系,Green依据员工评价变化高低将股票分为三组,并通过最高组和最低组之差构建了该因子。理论上,员工评价变高,意味着经济环境及公司前景很可能在变好,在其他条件相同的情况下,公司应有更好的表现,因此预期收益率更高。实证结果支持了他们的猜想。无论等权重还是市值加权,该因子都能够获得显著的超额收益。此外,高、低评价变化组合的主要特征基本一致,动量也非常接近,而员工评价变化平均相差超过1星,这意味着其他常见因子无法解释公司评价。这一点也进一步被Fama–MacBeth 回归结果所验证:无论单变量回归,还是控制不同的公司特征,员工评价变化都有显著的超额收益。
虽然上述发现十分有趣,但Glassdoor.com 的数据是否合理仍然存疑:员工评价数据是否无偏呢?是否是可信的?事实上,该网站的数据存在以下一些潜在问题。
(1) 没有员工认证系统。这意味着任何人可以在任何时间对任何公司进行评价,而没有机制来保证这个人确实是或曾是该公司的员工。
(2) 人们更容易在对雇主不满时发表(负面)评价。
(3) 人们往往过度夸大感受。Glassdoor.com上有很多1星和5星的评价。
(4) 评分体系本身并无科学依据。Glassdoor.com并没有明确说明每个星级到底代表什么。评分者可根据主观感受任意地选择1星到5星。工资不错?5星!餐厅免费?5星!免费健身房?5星!……5星可以代表任何事,但显然不是所有的5 星和股票收益率的关系都是一致的。人们不知道每个5 星背后到底意味着什么。
(5) 有些雇主有奖励机制,鼓励员工提交5星评价。曾经有一个公司大概有1.5星左右,后来管理层发话,如果员工仅发布经管理层审批后通过的留言,那么将得到250美元的奖励。这个公司后来的评分上升至4.2星。
这些问题说明,Glassdoor.com 的数据的无偏性令人担忧。
除此之外,对该数据的另一个猜想是涉及公司的行业分布是否均匀?比如,互联网或者科技公司的员工更容易也更愿意参与网上评价,而传统制造业企业的员工则没那么热衷于此事。如果行业分布不均,那么相关研究结果将会由于没有控制行业影响而大打折扣。
4. 历史样本数据较短
对于大多数另类数据来说,一个不得不面对的问题是数据长度往往很短。
通常来说,另类数据集的历史数据长度一般是5年以内(2到3年很常见),5年以上就是很长的了。历史数据太短会加剧多重假设检验问题造成的影响,造成拟合度提高。
Bailey和Lopez de Prado研究发现,数据长度越短则越容易出现过拟合。
举个例子,假设数据无法预测收益率。该研究发现,如果数据的长度仅有2年,则仅需要通过7个检验就能发现一个夏普比率为1.0的策略;而如果将数据的长度增加到5年,达到同样的效果则需要45个检验。因此,数据长度越短,越容易出现过拟合。在这个时候,如果没有对另类数据背后逻辑的认知,则难以辨别找到的因子是否真的有效。
5. 检验增量贡献
关于另类数据的最后一点思考是检验其对预测收益率是否有增量贡献。
例如Liew和Budavari使用推特情绪数据,在Fama–French五因子基础上加入了第六个因子,并指出该因子能在五因子之外解释个股收益率的时序波动。
人们之所以使用另类数据,是希望它们能够提供传统数据源无法解释的超额收益。如果绕了一大圈后发现,另类数据背后的收益率驱动和已有因子相同,那么它就没有提供额外的价值。在投资中,多样化被认为是唯一的“免费的午餐”,同样的道理对数据也成立。只有当另类数据和现有数据尽可能不相关,它才有可能捕捉到其他收益源之外的收益,并提高投资组合的风险调整后收益。
以上就是对另类数据的五点思考。
最后,简单总结一下另类数据的四大主流数据来源,包括网络抓取、情绪、卫星数据以及消费数据。
在传统因子变得越来越拥挤的今天,另类数据的出现无疑为因子投资注入了新的活力。
我们应该客观地认识另类数据的特点,使用科学的分析方法,并抱有正确的预期,或许另类数据在因子投资中或大有可为。据来自AlternativeData.org 的统计数据显示,海外买方在购买另类数据上的支出在最近几年逐年增长,说明业界对另类数据越来越重视。我们也有理由对另类数据的未来充满希望。
▼
想要了解更多关于因子投资方面的内容,可阅读《因子投资:方法与实践》一书。

▊《因子投资:方法与实践》
石川,刘洋溢,连祥斌 著
因子投资中文版首著!
一本真正可操作、可上手的因子投资手册
独立、可复制、高质量的实证分析
本书在统一视角下,体系化地介绍了因子投资中的重要研究方法,并针对中国A 股市场给出了独立的、可复制的、高质量的因子实证分析结果,是一本真正可操作、可上手的因子投资手册。
本书主要内容包括:因子投资基础、因子投资方法论、主流因子解读、多因子模型、异象研究、因子研究现状和因子投资实践。书中还以附录的形式对理解资产价格的研究脉络进行了梳理。本书的写作既注重学术文献的严谨,也注重普通读者的阅读体验。书中虽然涉及必要的数学公式,但是会深入浅出、抽丝剥茧地解释统计方法,并把重点放在实证分析上,同时也会对因子投资的实务进行解读。
(扫码了解本书详情)
如果喜欢本文 欢迎 在看丨留言丨分享至朋友圈 三连 热文推荐
▼点击阅读原文,获取本书详情~