
Flink 解读 | Apache Flink 1.16 功能解读
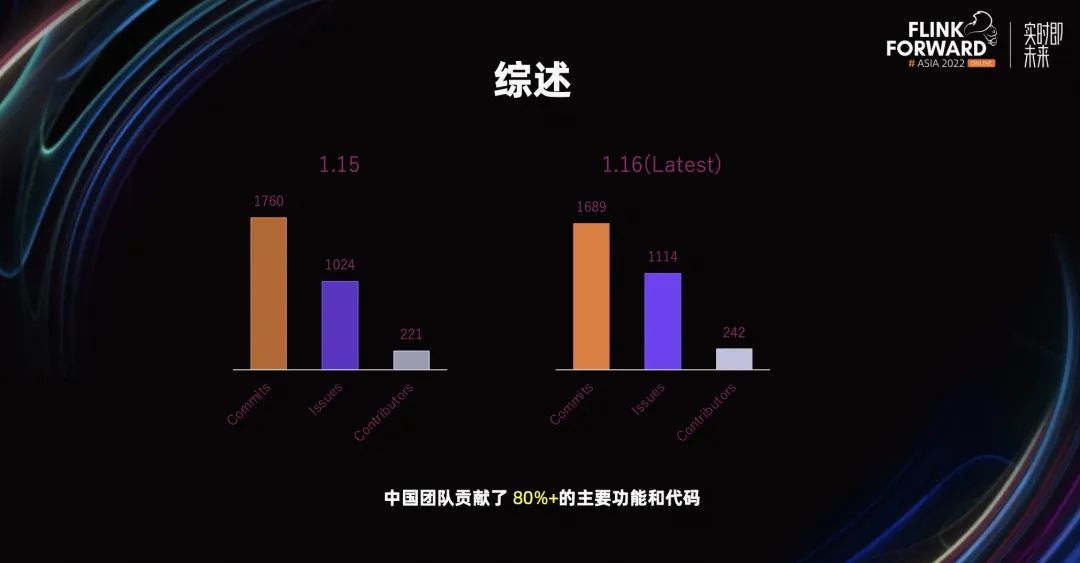
综述
持续领先的流处理
更稳定易用高性能的批处理
蓬勃发展的生态
综述

持续领先的流处理




我们在 Flink 1.16 中,对维表部分的增强。
1. 我们引入了一种缓存机制,提升了维表的查询性能。
2. 我们引入了一种异步查询机制,提升了整个吞吐。
3. 我们引入一种重试机制,主要为了解决维表查询时,遇到的外部系统更新过慢,导致结果不正确,以及稳定性问题。
通过上述改进,我们的维表查询能力得到了极大提升。


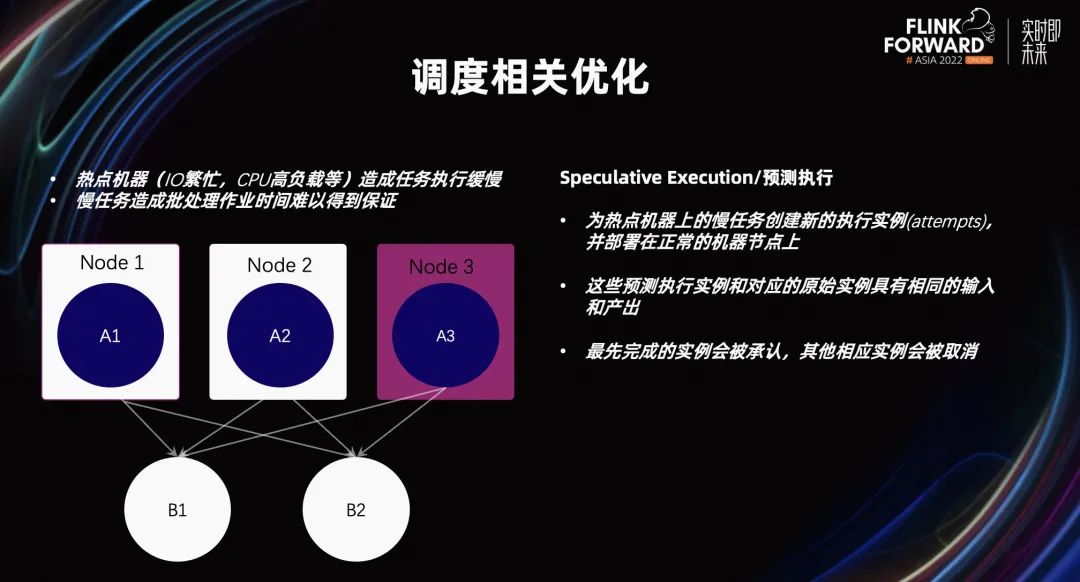
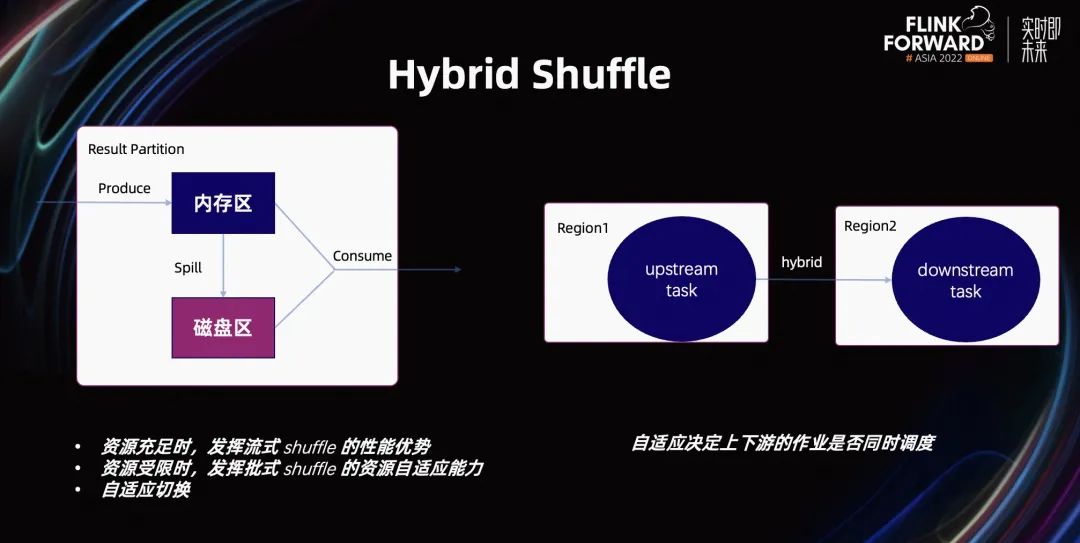
更稳定易用高性能的批处理
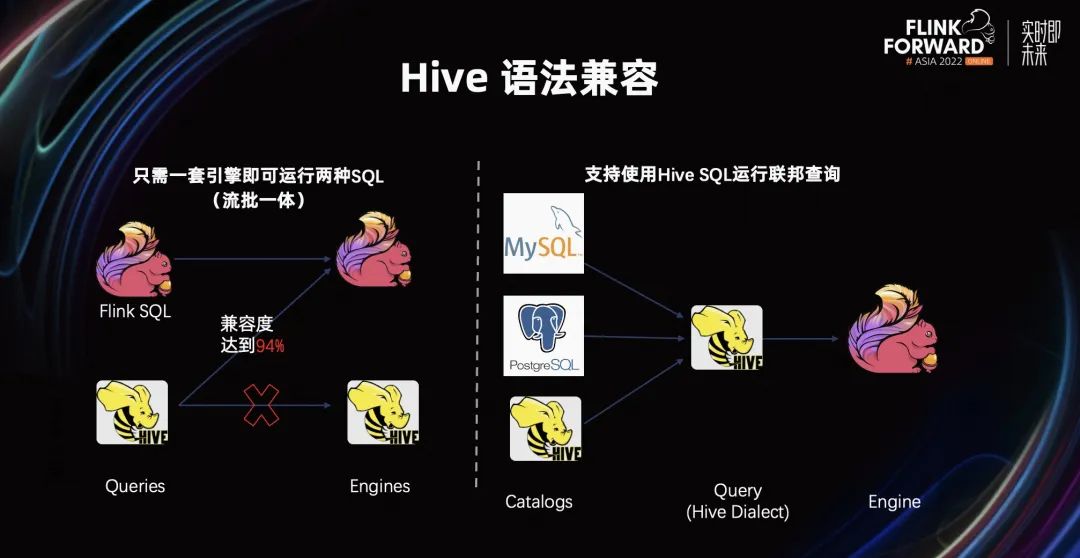
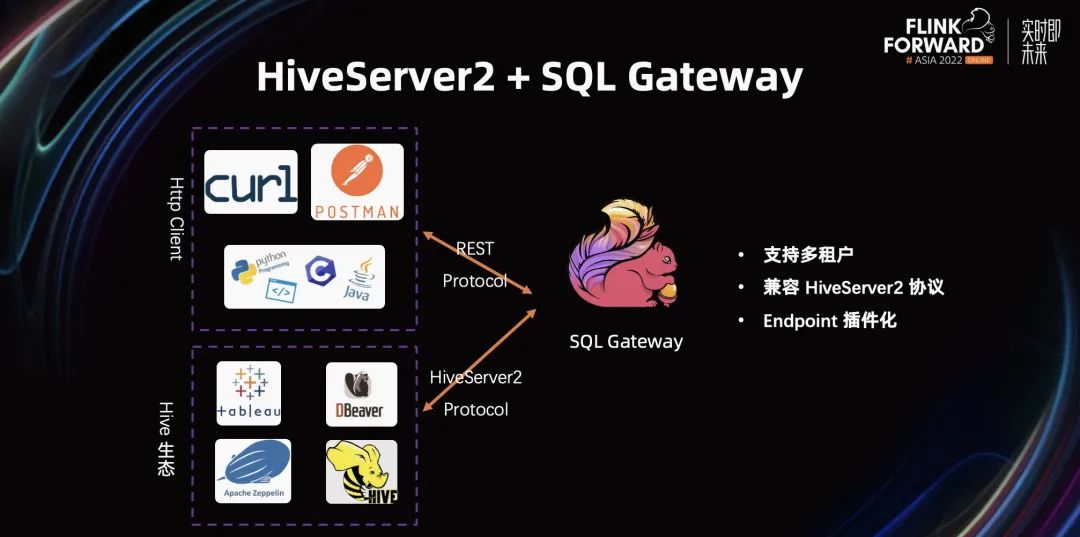





蓬勃发展的生态




往期精选





 点击「阅读原文」,查看原文视频&演讲 PPT
点击「阅读原文」,查看原文视频&演讲 PPT评论