
机器学习之 AWS DeepRacer 初体验 (1)
机器学习这门科学所关注的问题是:计算机程序如何随着经验积累自动提高性能。近年来,机器学习被成功地应用于很多领域,从检测信用卡交易欺诈的数据挖掘程序,到获取用户阅读兴趣的信息过滤系统,再到能在高速公路上自动行驶的汽车。
—— 美·Tom M. Mitchell 著《机器学习》 CIP 数据核字(2002)第 077094 号
先炫耀一下
看起来,机器学习应用于自动驾驶,至少也有 20 多年历史了。但是直到上周五,我才有幸第一次零距离参与了一把。


上周五有幸参加了亚马逊云科技的“机器学习及自动驾驶体验日”活动,并且所在小组 Alpha Car 在比赛中竟以微弱优势拿了冠军。


还领到一张很有逼格的奖状:

感恩
职业程序员用自己的时间来练习。老板的职责不包括避免你的技术落伍,也不包括为你打造一份好看的履历。医生练习手术不需要病人付钱,球员练习绕桩(通常)不需要球迷付钱,乐手练习音阶也不需要乐迷付钱。所以老板没有义务为程序员的练习来买单。
—— 【美】Robert C. Martin 《代码整洁之道:程序员的职业素养》
Bob 大叔在强调程序员的专业素养时指出,保持自己的学习跟上时代节奏,是自己的责任,而且应该在业余时间完成,而不应该占用雇主的时间,也不应该期待雇主支付相关的费用。
虽然如此,仍然有雇主会在工作日给员工提供培训的机会,甚至花费大量金钱。对这样的雇主,我心存感激!

AWS DeepRacer 简介
官网:https://aws.amazon.com/cn/deepracer/?nc2=type_a
使用 AWS DeepRacer,可以在云上进行自动驾驶赛车训练,随后既可以参加线上虚拟赛车,也可以将训练好的赛车模型导出为压缩文件,上传至真正的 AWS DeepRacer 赛车上,在真实跑道上进行比赛。
它号称各种技能水平的开发人员都可以通过其基于云的 3D 赛车模拟器亲身体验机器学习,我实际体验下来,发现 AWS 真的做到了!最大的感受是,DeepRacer 整个系统解耦做得相当漂亮,多数步骤都使用界面引导,唯一需要写代码的部分,就是奖励函数,采用 Python 编码,相当简单,的确对于开发菜鸟,也能使用!
你可以参加免费的在线培训:https://www.aws.training/Details/eLearning?id=32143,学完也可以拿一个很有逼格的结业证书,像这样:

机器学习问题的标准描述
首先看一下机器学习的严格定义:对于某类任务 T 和性能度量 P,如果一个计算机程序在 T 上以 P 衡量的性能随着经验 E 而自我完善,那么我们成这个计算机程序在从经验 E 中学习。
比如对于 AWS 的 DeepRacer 中的计时赛,就是这样一个机器人驾驶学习问题:
任务 T:通过视觉传感器在赛车道上行驶
性能标准 P:无差错行驶指定圈数所花费的时间(时间越短越好,行驶过程中不能出轨道)
训练经验 E:使用模型中配置好的驾驶指令在 AWS DeepRacer 提供的 3D 赛车赛道上进行驾驶
简而言之,机器学习就是“通过经验提高性能的某类程序”。
机器学习的一般套路
通过使用 AWS DeepRacer,你可以毫不费力地亲身体验到机器学习的一般套路,而且生动,令人难忘。
选择训练经验
这是机器学习系统面临的第一个设计问题,在 AWS DeepRacer 中,预设计了各种赛道,你只需要点击选择就好。

具体地说,AWS DeepRacer 采用的强化学习方法,赛道信息在其中被称为环境,也就是轨道。轨道中定义了赛车可以走动的地方,以及被允许的状态。赛车在轨道中探索并搜集数据,这些被搜集的数据就被用作底层神经网络的训练经验。
选择目标函数
这是机器学习系统面临的第二个设计选择,它需要决定要学习的知识的确切类型以及执行程序怎样使用这些知识。对于赛车问题,由于只要不出轨道,前进方向正确,都是被允许的驾驶方式,最终的程序只要并且必须学会从所有的驾驶方式中选择最快速跑完指定圈数的驾驶策略。很明显,要学习的信息类型就是一个程序或者函数,该函数以赛车在轨道中所处的状态作为输入,并且从所有被允许的驾驶策略中产生某个驾驶行为作为输出。即 V: State -> Result。如前面所介绍的,这个函数被体现为奖励函数,是唯一需要写点代码的部分。
这个函数写起来虽然简单,但却是产生好的结果的关键所在。根据我的体验,这个函数并不是越复杂越好,相信也没有人能预先写出最佳的奖励函数,一定是各种摸索,最终找到一个最好的,而且在未来被更好的奖励函数打败也是很正常的。
具体来说,对于任意的赛车状态,奖励函数的准确值应该是多少呢?最简单的做法是不管什么状态,总是给予奖励。这显然不会产生好的结果;也许你会想到,应该奖励行进在轨道中间,离中线不要太远的驾驶行为。要写出自己想要的奖励函数,需要先了解一下 AWS DeepRacer 都提供了哪些赛车状态参数、可以产生哪些具体的驾驶行为以及奖励函数在 AWS DeepRacer 中的具体体现形式。
如前所述,在 AWS DeepRacer 中,奖励函数是一段 Python 代码,它可以读取描述当前状态的参数,并返回一个奖励数值。参数描述了赛车状态的不同方面,比如位置、在轨道中的朝向、速度、转角等等。
所谓状态,就是赛车所在的环境在指定时刻的快照,即赛车的前置摄像头所捕获的图片。AWS DeepRacer 系统可以为奖励函数提供的参数一共有 13 种:
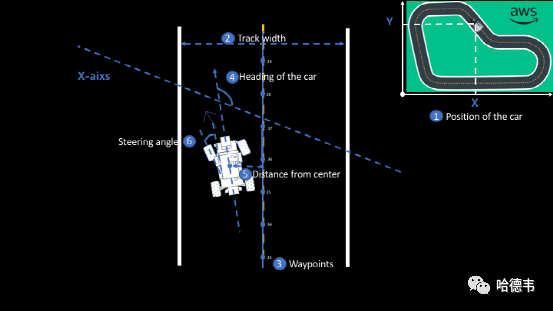
赛车在轨道上的位置
 3.heading
3.heading赛车在轨道上的朝向
 4.waypoints
4.waypoints航路点坐标列表
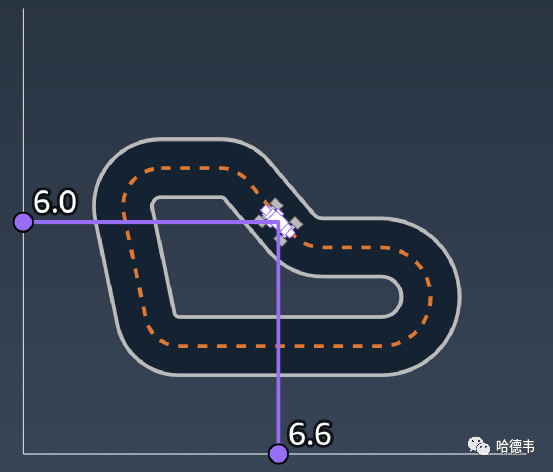
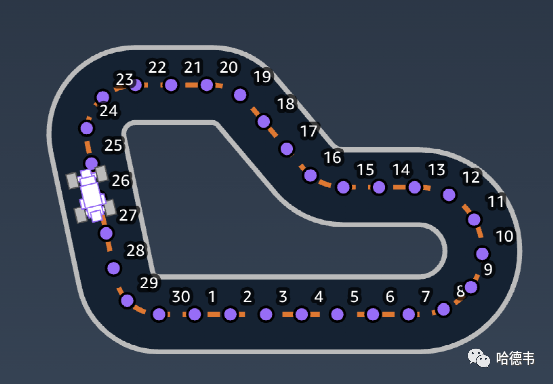 5.closest_waypoints
5.closest_waypoints赛道上离赛车最近的 2 个航路点6.progress
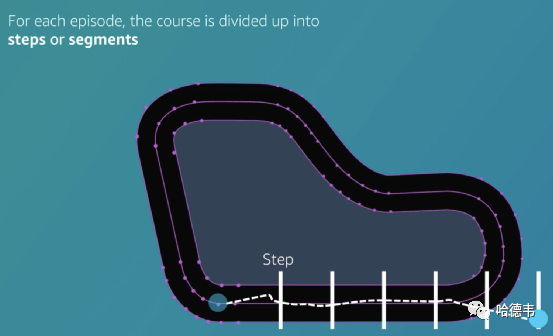
跑完的轨道部分百分比7.steps 完成的步数
 8.track_width
8.track_width 轨道宽度
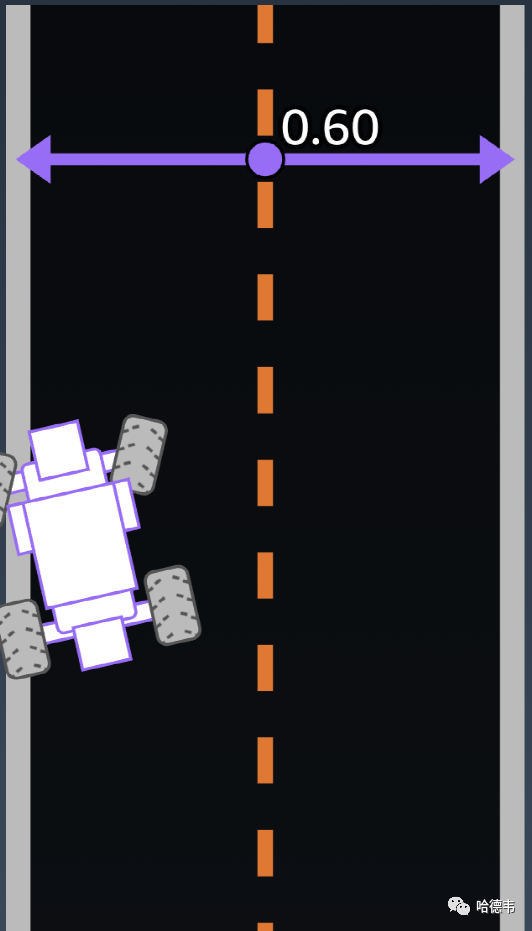 9.distance_from_center
9.distance_from_center 偏离轨道中线的距离
 10.is_left_of_center
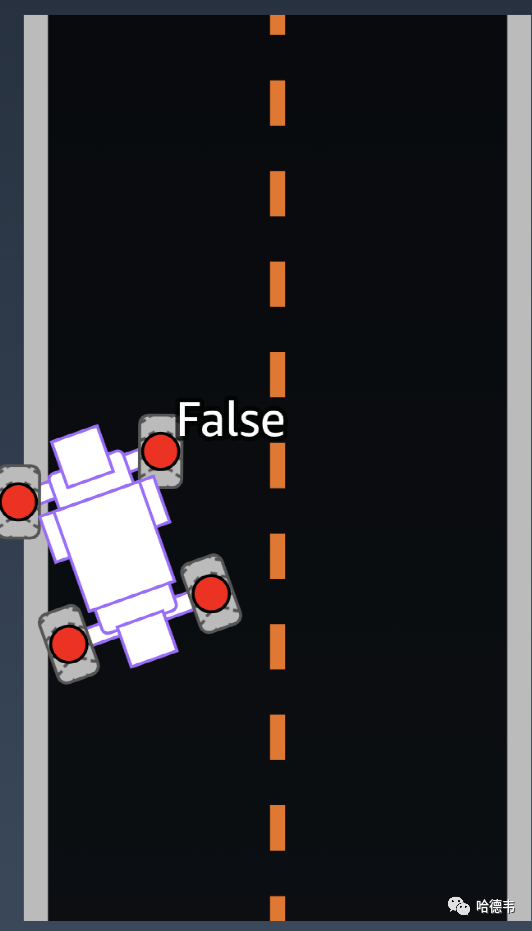
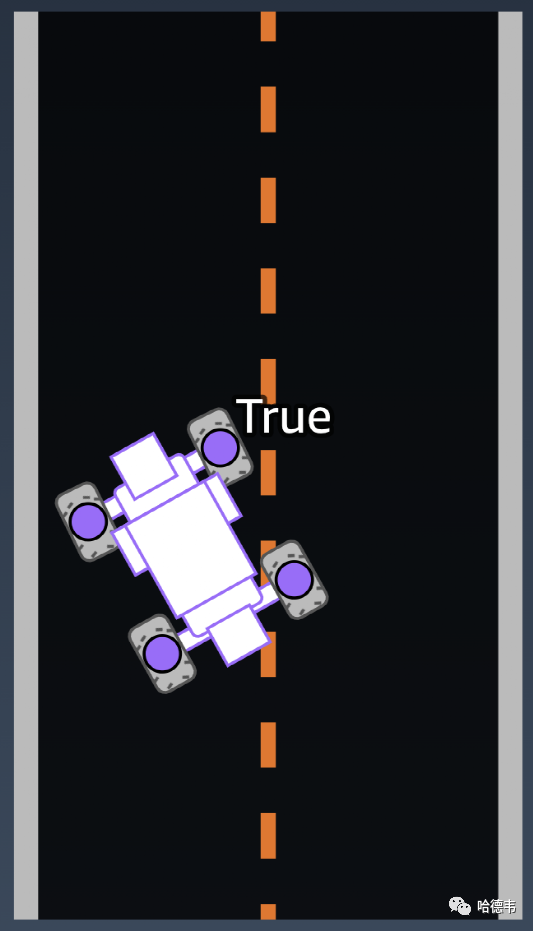
10.is_left_of_center 赛车是否在中线左边?11.all_wheels_on_track
赛车是否完全处于轨道界内?
 12.speed
12.speed 赛车车速
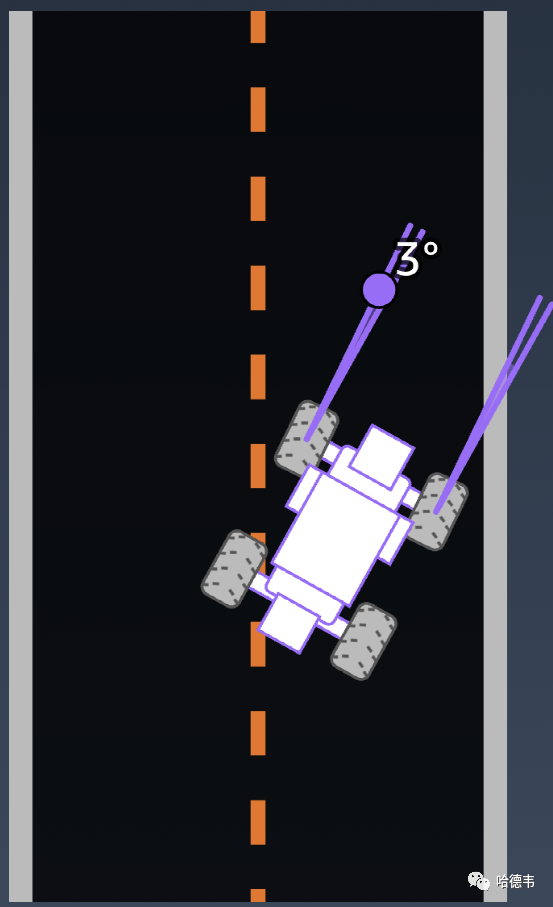
 13.steering_angle
13.steering_angle 前轮方向盘转角
如前所述,你可以根本就不使用这些参数,全部情况下都给予奖励。或者利用全部的参数,但是并不一定就有好的结果。我在实验时,选择了对靠中线,以及不出界的情况给予奖励,奖励函数代码如下:
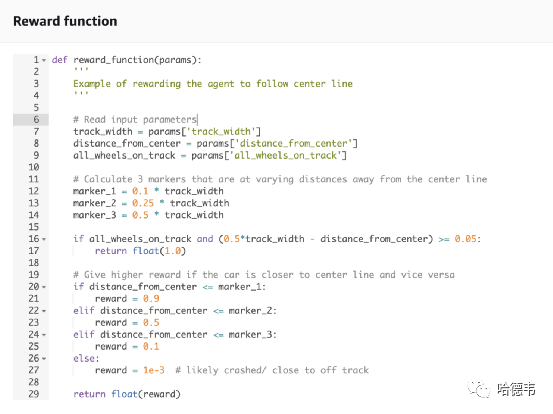
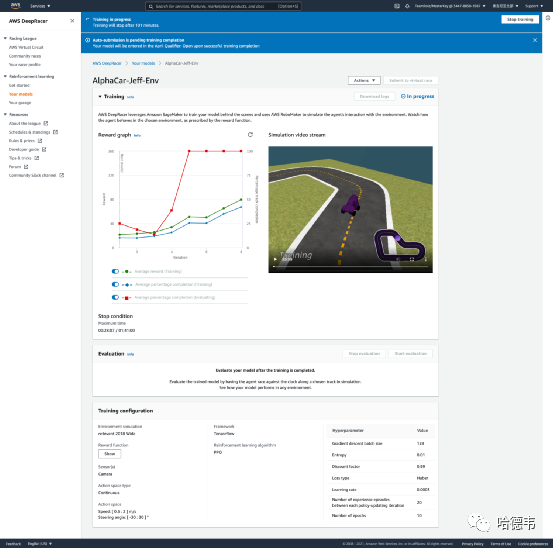
编辑完奖励函数,就可以开始训练了,训练过程中可以查看过程详情:
选择目标函数的表示
前面一步的目标函数是形如 V:State -> Result 的形式,即从当前状态可以映射称一个结果(好或者坏)。这是一个理想的函数,实际上只能得到 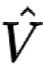 ,一个 V 的估计。学习的过程就是尽量较少估计值 和理想值 V 的误差的过程。
,一个 V 的估计。学习的过程就是尽量较少估计值 和理想值 V 的误差的过程。
这个具体的表示不用关心,只需要知道底层是一个 CNN 网络就行,具体表示可以理解为一个加权平均函数。也就是说,AWS DeepRacer 使用了一个 CNN 网络,然后通过类似加权平均这样的计算,努力使得这个结果值,和奖励函数的返回值接近。
权重就是学习过程所要调整的数值,而参数除了上面介绍的 13 个状态参数外(模型之内),还有超参数(模型之外)。超参数是人工调整的,而模型参数则是学习过程自动调整的。所以机器学习,实际上是人机共同学习。机器学习负责模型参数的调整,有各种算法,但是归根结底是一种试错改进法。同样,需要人工调整的超参数,也是人通过试错调整的方式,慢慢改进得到的较好的值。
选择函数逼近算法
这个算法的根本目的在于逐步减小目标函数估计值和理想值的误差,关键在于更新权值的策略。大致做法是从任意指定的初始权值开始,使用目标函数的具体表示计算出 ,然后计算 V 和 的误差。注意这个 V 是奖励函数的返回值,因此实际奖励和实际模型拟合出的结果的误差就能指导学习过程去调整权重。
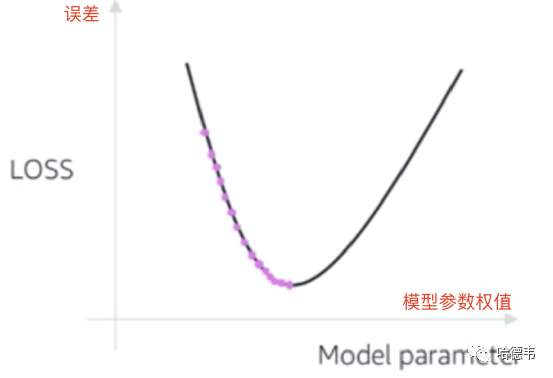
AWS DeepRacer 支持两种算法,默认选项是 Huber 算法,你也可以改成均方差算法。他们的区别是均方差算法带来的权值改动会使得误差波动更大,因此收敛性会逊于 Huber。

最终设计
任何机器学习系统,最终会包含如下几个核心模块:
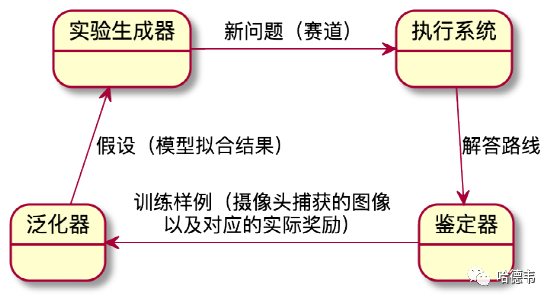
AWS DeepRacer 采用了机器学习中的强化学习方法,这是区别于有监督学习和无监督学习之外的,第三种机器学习类型,其设计如下:
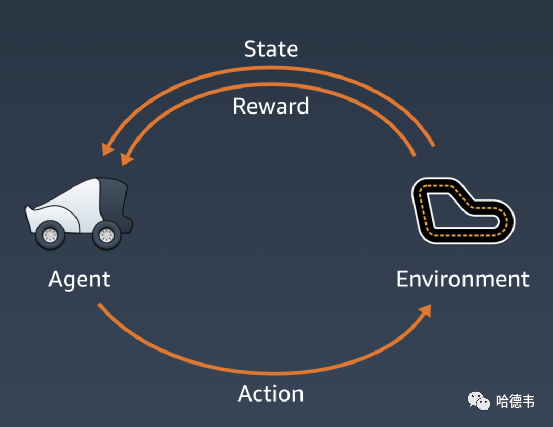
其中环境对应实验生成器,奖励环节对应鉴定器,代理人对应执行系统。代理人在指定环境中探索通过执行能够带来奖励的动作并且避免带来惩罚的动作来学习需要完成的任务。
总结
机器学习分成三种类型:有监督学习、无监督学习以及强化学习。AWS DeepRacer 是一个设计得非常棒的系统,将非常复杂的机器学习课程,呈现得无比简单。它构建在已有的 AWS 资源上,比如环境、模型等静态数据存储在 S3 上,而训练过程中的动态数据存储在 Redis 中,并不断更新。各个组件解耦做得相当漂亮,用户只需要在奖励函数这部分写一点点代码,其他都通过友好的界面引导完成,这真的是名副其实的机器学习低代码平台!尽管 AWS DeepRacer 采用的强化学习,但是可以完整地体验到机器学习中的一般套路。
彩蛋
(只要是)我不能创造的,我就(还)没有理解。
—— 物理学家费曼
AWS DeepRacer 非常棒,但是要使用它,由于会使用到存储和计算,因此会产生费用。作为程序员,如果想要自己实现它,工程量又实在太大太大了。但是,凭一己之力,实现一个机器学习版的井字棋游戏,还是完全可能的。而且虽然不一定采用强化学习,但只要是机器学习,套路都是一样的。你可以先去 https://tictactoe.js.org 体验一下,然后按照本文介绍的套路自己撸一个。如果碰到困难可以参考它的源码:https://github.com/Jeff-Tian/tic-tac-toe-ai,以及图文逐步指导: