
Flink SQL on Zeppelin - 打造自己的可视化Flink SQL开发平台
点击上方蓝色字体,选择“设为星标”
回复”资源“获取更多资源

我们在之前的文章中详细介绍过Zepplin的来龙去脉,很多大厂基于Flink开发了自己的SQL开发平台。更多的公司可能需要选择一种低成本接入,尽量复用开源的解决方案答案快速支撑业务发展。那么本文就介绍基于Zepplin开发自己的Flink SQL平台。本文是蘑菇街实时计算负责人狄杰发表在网络上的作品,小编进行了整理。小编之前也写过Flink对接Zeppelin的方案和引用。本文提炼出来一个完整的Flink SQL对接Zeppelin的方案,希望对读者有帮助。本文未经过原作者允许禁止转载。
环境准备
目前开发Flink的方式有很多,一般来说都是开发同学写JAVA/SCALA/PYTHON项目,然后提交到集群上运行。这种做法较为灵活,因为你在代码里面可以写任务东西,什么维表JOIN、参数调优,都能很轻松的搞定。但是对开发同学的要求较高,有一定的学习成本。比如有些同学擅长JAVA,有些擅长PYTHON,而在我们的项目开发过程中,是不会允许多种语言共存的,一般来说都是选择JAVA作为我们的开发语言,那么,对于擅长PYTHON的同学来说,再从头开始攀爬JAVA这座大山,而且还得短期能够熟练使用,无疑是难上加难。所以,最好的选择是有一种学习成本低,大多数同学都学过、用过的语言,或者说上手很容易的语言。那就是SQL。社区目前也在推进纯Sql的平台,比如Flink自带的sql-client命令行工具,虽说大多数功能都已支持,包括CREATE VIEW这种尚未在代码中支持的语句,但是功能实在单一,且不支持REST方式去提交我们的代码,总不能让每个人都在自己电脑上配上Flink的客户端吧?其他的缺点还有很多,就不一一列举了。就我看来,sql-client目前还只是个大玩具,等大家成熟了,就会抛弃它。ververica目前也推出了一个Sql客户端—Flink SQL Gateway+flink-jdbc-driver,将两者结合使用,也能够很好的构架一个纯Sql的开发平台。缺点也很明显,首先没有可视化界面,也是通过命令行或者自己封装的方式来使用;其次,社区规模小,活跃度低,很多人都不一定知道这个东西。那么,有没有一个有图形化界面、功能完善、社区活跃度高的工具呢?答案就是:Zepplin。想在Zeppelin中使用Flink,需要下载最新的Zeppelin 0.9.0 以及 Flink 1.10版本及以上 。然后我们直接进入到Zepplin的配置过程:如果看到控制台正常输出Zeppelin start [ OK ],那就说明安装完成,否则去zeppelin的log目录下,查看日志,分析启动失败原因。然后打开浏览器,输入服务器地址和端口,默认端口是8080,如果能看到下面的页面,说明正常,否则一样去分析日志。
#1.1解压
tar -zxvf zeppelin-0.9.0-SNAPSHOT.tar.gz
#1.2进入conf目录
cd zeppelin-0.9.0-SNAPSHOT/conf
#1.3修改配置文件名,不然应用无法正确加载到
mv zeppelin-env.sh.template zeppelin-env.sh
#1.4.1修改配置文件
vim zeppelin-env.sh
#1.4.2在编辑器页面,插入两行内容
export JAVA_HOME=这里改成jdk的目录!请勿照抄
export ZEPPELIN_ADDR=这里写要绑定的IP,如果Zeppelin没有装在本机,那就不要写127.0.0.1,否则别的机器无法通过ip+port进行访问
#1.4.3保存并退出。
#2.1因为我打算把Flink跑在Yarn上,加上之后要连接Hive,所以,现在去Flink的目录添加几个Jar包,不打算跑在Yarn的同学可以直接跳到步骤3.1
cd ~/flink/lib
#2.2下载Flink On Yarn的相关Jar包,Jar包版本要和你Flink以及Hadoop版本对应,我的Hadoop版本是2.7.1
wget https://repo1.maven.org/maven2/org/apache/flink/flink-hadoop-compatibility_2.11/1.10.0/flink-hadoop-compatibility_2.11-1.10.0.jar
wget https://repo1.maven.org/maven2/org/apache/flink/flink-shaded-hadoop-2-uber/2.7.5-9.0/flink-shaded-hadoop-2-uber-2.7.5-9.0.jar
#2.3下载Flink 连接 Hive的相关Jar包,我的Hive版本是2.1.1。这里因为Hive版本可能和大家不同,可以参考一下官网的文档,https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/table/hive/#dependencies
wget https://repo1.maven.org/maven2/org/apache/hive/hive-exec/2.1.1/hive-exec-2.1.1.jar
wget https://repo1.maven.org/maven2/org/apache/flink/flink-connector-hive_2.11/1.10.0/flink-connector-hive_2.11-1.10.0.jar
#3.1上面的步骤完成来,来到Zeppelin的bin目录
cd ~/zeppelin-0.9.0-SNAPSHOT/bin
#3.2启动!
./zeppelin-daemon.sh start
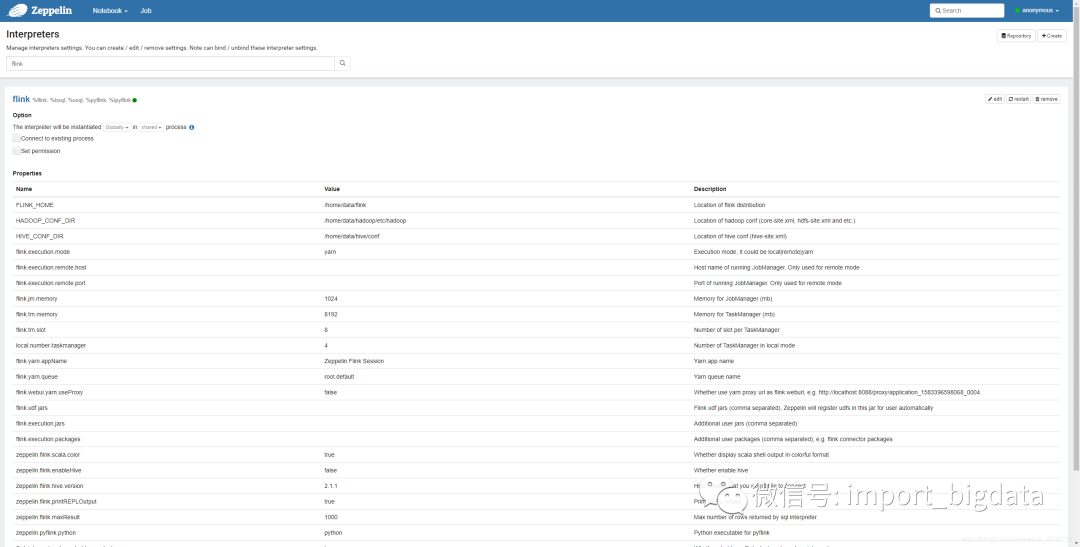
Local 会启动个MiniCluster,适合POC阶段,只需要配置上面两个参数。
Remote 连接一个Standalone集群,除了要配置FLINK_HOME 和 flink.execution.mode以外,还需要配置flink.execution.remote.host和flink.execution.remote.port,具体配置内容可以查看flink-conf.yaml。
Yarn 我们之后要使用的模式,会在Yarn上启动一个Yarn-Session模式的Flink集群。除了要配置FLINK_HOME 和 flink.execution.mode以外,还需要配置HADOOP_CONF_DIR。


提交任务时报错—JAVA版本过低
org.apache.zeppelin.interpreter.InterpreterException: java.io.IOException: Fail to launch interpreter process:出现这个问题的原因是,我们服务器上环境变量JAVA_HOME对应的JAVA版本是1.8.0_72-b15,虽然说我们在上面修改zeppelin-env.sh的时候,已经配置了新的环境变量,但是zeppelin启动Interpreter的时候,没有把环境变量传入导致,之后我会看一下社区有没有修复这个bug,没有的话我就去jira提交一下。修改的方式有两种:
Apache Zeppelin requires either Java 8 update 151 or newer
at org.apache.zeppelin.interpreter.remote.RemoteInterpreter.open(RemoteInterpreter.java:134)
at org.apache.zeppelin.interpreter.remote.RemoteInterpreter.getFormType(RemoteInterpreter.java:298)
at org.apache.zeppelin.notebook.Paragraph.jobRun(Paragraph.java:433)
at org.apache.zeppelin.notebook.Paragraph.jobRun(Paragraph.java:75)
at org.apache.zeppelin.scheduler.Job.run(Job.java:172)
at org.apache.zeppelin.scheduler.AbstractScheduler.runJob(AbstractScheduler.java:130)
at org.apache.zeppelin.scheduler.RemoteScheduler$JobRunner.run(RemoteScheduler.java:159)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$201(ScheduledThreadPoolExecutor.java:180)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:293)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
Caused by: java.io.IOException: Fail to launch interpreter process:
Apache Zeppelin requires either Java 8 update 151 or newer
at org.apache.zeppelin.interpreter.remote.RemoteInterpreterManagedProcess.start(RemoteInterpreterManagedProcess.java:130)
at org.apache.zeppelin.interpreter.ManagedInterpreterGroup.getOrCreateInterpreterProcess(ManagedInterpreterGroup.java:65)
at org.apache.zeppelin.interpreter.remote.RemoteInterpreter.getOrCreateInterpreterProcess(RemoteInterpreter.java:110)
at org.apache.zeppelin.interpreter.remote.RemoteInterpreter.internal_create(RemoteInterpreter.java:163)
at org.apache.zeppelin.interpreter.remote.RemoteInterpreter.open(RemoteInterpreter.java:131)
... 13 more
修改环境变量JAVA_HOME对应的JAVA地址,修改完重启zeppelin。
因为服务器上还有别的应用,不然冒然升级JDK,那么就修改zeppelin/bin目录下的common.sh文件。
提交任务时报错—网络不通
Exception in thread "main" org.apache.zeppelin.shaded.org.apache.thrift.transport.TTransportException: java.net.SocketException: Network is unreachable (connect failed)
at org.apache.zeppelin.shaded.org.apache.thrift.transport.TSocket.open(TSocket.java:226)
at org.apache.zeppelin.interpreter.remote.RemoteInterpreterServer.(RemoteInterpreterServer.java:167)
at org.apache.zeppelin.interpreter.remote.RemoteInterpreterServer.(RemoteInterpreterServer.java:152)
at org.apache.zeppelin.interpreter.remote.RemoteInterpreterServer.main(RemoteInterpreterServer.java:321)
Caused by: java.net.SocketException: Network is unreachable (connect failed)
at java.net.PlainSocketImpl.socketConnect(Native Method)
at java.net.AbstractPlainSocketImpl.doConnect(AbstractPlainSocketImpl.java:350)
at java.net.AbstractPlainSocketImpl.connectToAddress(AbstractPlainSocketImpl.java:206)
at java.net.AbstractPlainSocketImpl.connect(AbstractPlainSocketImpl.java:188)
at java.net.SocksSocketImpl.connect(SocksSocketImpl.java:392)
at java.net.Socket.connect(Socket.java:606)
at org.apache.zeppelin.shaded.org.apache.thrift.transport.TSocket.open(TSocket.java:221)
... 3 more
at org.apache.zeppelin.interpreter.remote.RemoteInterpreter.internal_create(RemoteInterpreter.java:166)
at org.apache.zeppelin.interpreter.remote.RemoteInterpreter.open(RemoteInterpreter.java:131)
... 13 more
维表Join
我们在之前的文章中详细讲解过Flink和维表进行Join的方式。现在带大家看看如何用Zeppelin来实现这个功能。首先,我们先引入我们所需的依赖包,目前大家先跟着我这么写,之后会讲解引入依赖的多种方式和区别。%flink.conf然后我们注册个File System Source,再注册Kafka Sink,之后会将从文件中读取的数据写入到kafka中。注意!大家不要把所有代码写在一个paragraph里面,建议一个paragraph写一段单一功能的语句:
# 这是第一个paragraph,大家不要把所有代码写在一个paragraph里面
# 配置一下依赖包,这种方式会自动下载依赖
flink.execution.packages org.apache.flink:flink-connector-kafka_2.11:1.10.0,org.apache.flink:flink-connector-kafka-base_2.11:1.10.0,org.apache.flink:flink-json:1.10.0,org.apache.flink:flink-jdbc_2.11:1.10.0
# 大家千万注意,如果用的是org.apache.flink:flink-connector-kafka_2.11:1.10.0,org.apache.flink:flink-connector-kafka-base_2.11:1.10.0这2个包,那么kafka 那边的 version请写universal,否则你会发现莫名其妙的错误
# 如果kafka版本低于0.11,请用org.apache.flink:link-connector-kafka-0.11_2.11 替换上面的kafka的包,kafka版本和scala版本也请替换成对应的版本,ddl语句中的version也同样如此
# 下面会用到Mysql,如果大家已经在Flink的lib目录下放了Mysql的驱动包,那么配这么多的包就行
# 否则的话,再加上mysql:mysql-connector-java:5.1.37这个包
%flink.ssql
-- File System Source DDL
DROP TABLE IF EXISTS t1;
CREATE TABLE t1 (
user_id bigint,
item_id bigint,
category_id bigint,
behavior varchar,
ts bigint
) WITH (
'connector.type' = 'filesystem',
'connector.path' = 'hdfs:///test/UserBehavior.csv',
'format.type' = 'csv',
'format.field-delimiter' = ','
)
;
%flink.ssql
-- Kafka Sink DDL
DROP TABLE IF EXISTS t2;
CREATE TABLE t2 (
user_id BIGINT,
item_id BIGINT,
category_id BIGINT,
behavior STRING,
ts BIGINT
) WITH (
'update-mode' = 'append',
'connector.type' = 'kafka',
'connector.version' = 'universal',
'connector.topic' = 'zeppelin_01_test',
'connector.properties.zookeeper.connect' = '127.0.0.1:2181',
'connector.properties.bootstrap.servers' = '127.0.0.1:9092',
'format.type'='json'
)
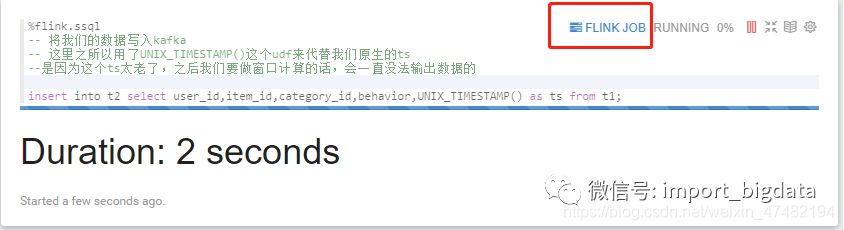
%flink.ssql让我们运行一下看看什么情况:
-- 将我们的数据写入kafka
-- 这里之所以用了UNIX_TIMESTAMP()这个udf来代替我们原生的ts
--是因为这个ts太老了,之后我们要做窗口计算的话,会一直没法输出数据的
insert into t2 select user_id,item_id,category_id,behavior,UNIX_TIMESTAMP() as ts from t1;
%flink.ssql有个要注意的地方是,select语句必须指定type,什么意思呢?type指的是流式数据分析的三种模式:
-- Kafka Source DDL
DROP TABLE IF EXISTS t3;
CREATE TABLE t3(
user_id BIGINT,
item_id BIGINT,
category_id BIGINT,
behavior STRING,
ts BIGINT,
r_t AS TO_TIMESTAMP(FROM_UNIXTIME(ts,'yyyy-MM-dd HH:mm:ss'),'yyyy-MM-dd HH:mm:ss'),-- 计算列,因为ts是bigint,没法作为水印,所以用UDF转成TimeStamp
WATERMARK FOR r_t AS r_t - INTERVAL '5' SECOND -- 指定水印生成方式
)WITH (
'update-mode' = 'append',
'connector.type' = 'kafka',
'connector.version' = 'universal',
'connector.topic' = 'zeppelin_01_test',
'connector.properties.zookeeper.connect' = '127.0.0.1:2181',
'connector.properties.bootstrap.servers' = '127.0.0.1:9092',
'connector.properties.group.id' = 'zeppelin_01_test',
'connector.startup-mode' = 'latest-offset',
'format.type'='json'
)
%flink.ssql(type=update)
select * from t3
single
append
update
%flink.ssql(type=update)Update模式适合多行输出的情况,适合和聚合语句配合一起使用,持续不断的更新数据,配合Zeppelin的可视化控件一起使用,效果更好。瞄一眼输出的内容,没什么问题,那我们开始整合Mysql Dim,先去Mysql库里建个表:
select * from table order by time_column desc limit 10```
-- Mysql 建表语句,注意这是在Mysql执行的!不要在Zeppelin执行
CREATE TABLE `dim_behavior` (
`id` int(10) NOT NULL AUTO_INCREMENT COMMENT '自增主键',
`en_behavior` varchar(255) COLLATE utf8_bin DEFAULT NULL COMMENT '英文 行为',
`zh_behavior` varchar(255) COLLATE utf8_bin DEFAULT NULL COMMENT '中文 行为',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8 COLLATE=utf8_bin;
-- 搞两条数据
INSERT INTO `dijie_test`.`dim_behavior`(`id`, `en_behavior`, `zh_behavior`) VALUES (1, 'buy', '购买');
INSERT INTO `dijie_test`.`dim_behavior`(`id`, `en_behavior`, `zh_behavior`) VALUES (2, 'pv', '浏览');
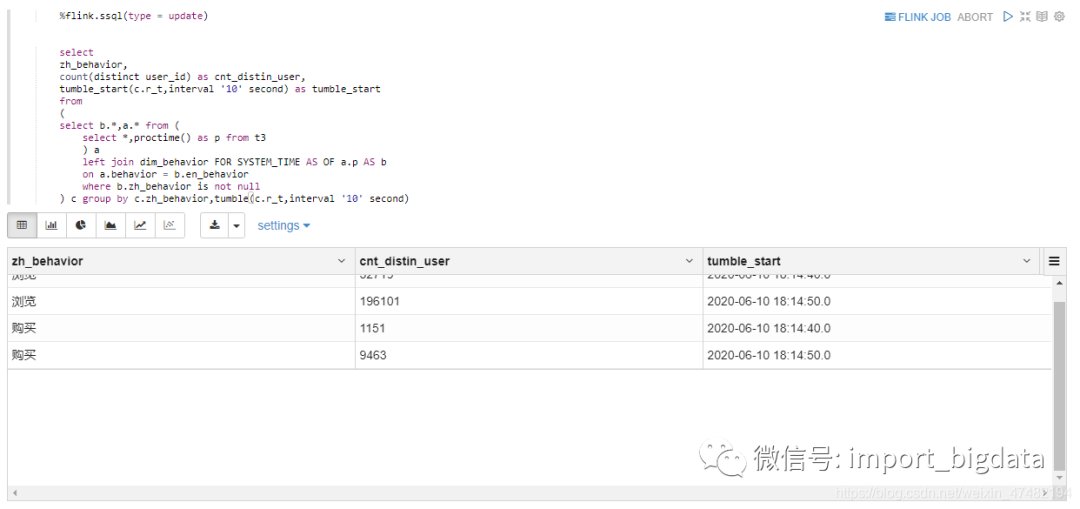
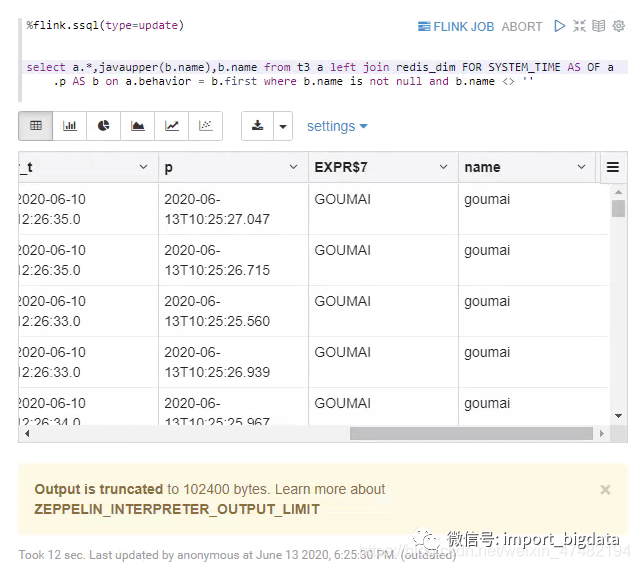
%flink.ssql(type = update)我们在Sql里进行了判断,把维表中没有的数据给过滤了。瞄一眼结果,发现确实正确的过滤了。而且数据正在持续不断的更新
select
zh_behavior,
count(distinct user_id) as cnt_distin_user,
tumble_start(c.r_t,interval '10' second) as tumble_start
from
(
select b.*,a.* from (
select *,proctime() as p from t3
) a
left join dim_behavior FOR SYSTEM_TIME AS OF a.p AS b
on a.behavior = b.en_behavior
where b.zh_behavior is not null
) c group by c.zh_behavior,tumble(c.r_t,interval '10' second)
java.io.IOException: Can not change interpreter properties when interpreter process has already been launched在执行insert或者select时,如果发现任务一点执行就立刻结束,没有报错,Flink Web Ui 也看不到相应的任务信息,同时,Zeppelin的日志也查不到有些的信息时,请将该paragraph的注释内容全部删除,再点击执行,你就会发现任务能够正常运行了。
at org.apache.zeppelin.interpreter.InterpreterSetting.setInterpreterGroupProperties(InterpreterSetting.java:958)
at org.apache.zeppelin.interpreter.ConfInterpreter.interpret(ConfInterpreter.java:73)
at org.apache.zeppelin.notebook.Paragraph.jobRun(Paragraph.java:479)
at org.apache.zeppelin.notebook.Paragraph.jobRun(Paragraph.java:75)
at org.apache.zeppelin.scheduler.Job.run(Job.java:172)
at org.apache.zeppelin.scheduler.AbstractScheduler.runJob(AbstractScheduler.java:130)
at org.apache.zeppelin.scheduler.FIFOScheduler.lambda$runJobInScheduler$0(FIFOScheduler.java:39)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
自定义UDF
在Flink中,使用代码注册UDF有两种方式:tEnv.registerFunction("test",new TestScalarFunc());
tEnv.sqlUpdate("CREATE FUNCTION IF NOT EXISTS test AS 'udf.TestScalarFunc'");而在Zeppelin中,也有多种方式。通过编写Scala代码,然后通过上面两种方式注入。flink.execution.jars加载指定Jar加载进Flink集群中,之后通过上面两种方式注册UDF。使用起来很不爽,首先你得知道有哪些UDF,其次你得挨个注册,而且你还得知道每个UDF的全类名,很麻烦。那么有没有更好的方式呢?flink.udf.jars自动将Jar包中所有UDF注册,相当方便,下面演示一下:先加一下配置参数
%flink.conf
flink.udf.jars /home/data/flink/lib_me/flink-udf-1.0-SNAPSHOT.jar
%flink.ssql(type=update)
show functions
%flink.ssql(type=update)
-- 连from哪个表都没必要写,Zeppelin实在太方便了
select javaupper('a')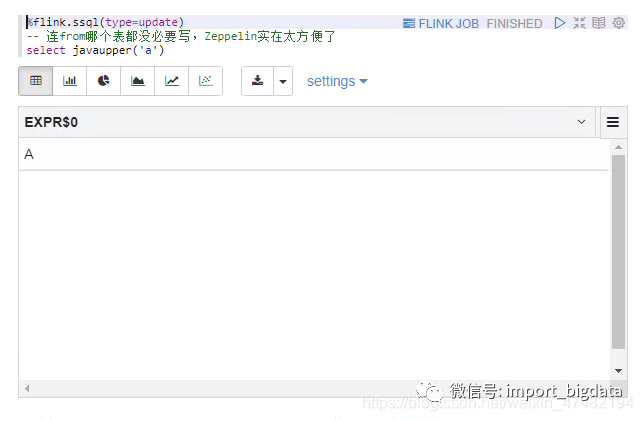
Redis维表
先通过flink.execution.jars将我们的Jar引入:%flink.conf再建一下我们的数据源表和数据维表
flink.udf.jars /home/data/flink/lib_me/flink-udf-1.0-SNAPSHOT.jar
flink.execution.jars /home/data/flink/lib_me/flink-redis-1.0-SNAPSHOT.jar
flink.execution.packages org.apache.flink:flink-connector-kafka_2.11:1.10.0,org.apache.flink:flink-connector-kafka-base_2.11:1.10.0,org.apache.flink:flink-json:1.10.0,org.apache.flink:flink-jdbc_2.11:1.10.0
%flink.ssql
-- Kafka Source DDL
DROP TABLE IF EXISTS t3;
CREATE TABLE t3(
user_id BIGINT,
item_id BIGINT,
category_id BIGINT,
behavior STRING,
ts BIGINT,
r_t AS TO_TIMESTAMP(FROM_UNIXTIME(ts,'yyyy-MM-dd HH:mm:ss'),'yyyy-MM-dd HH:mm:ss'),
WATERMARK FOR r_t AS r_t - INTERVAL '5' SECOND,
p AS proctime()
)WITH (
'update-mode' = 'append',
'connector.type' = 'kafka',
'connector.version' = 'universal',
'connector.topic' = 'zeppelin_01_test',
'connector.properties.zookeeper.connect' = '127.0.0.1:2181',
'connector.properties.bootstrap.servers' = '127.0.0.1:9092',
'connector.properties.group.id' = 'zeppelin_01_test',
'connector.startup-mode' = 'earliest-offset',
'format.type'='json'
)
%flink.ssql再执行我们的Sql,并且用UDF将查出来的维表值转成大写
-- Redis Dim DDl
DROP TABLE IF EXISTS redis_dim;
CREATE TABLE redis_dim (
first String,
name String
) WITH (
'connector.type' = 'redis',
'connector.ip' = '127.0.0.1',
'connector.port' = '6379',
'connector.lookup.cache.max-rows' = '10',
'connector.lookup.cache.ttl' = '10000000',
'connector.version' = '2.6'
)
%flink.ssql(type=update)看一下结果
select a.*,javaupper(b.name) from t3 a left join redis_dim FOR SYSTEM_TIME AS OF a.p AS b on a.behavior = b.first where b.name is not null and b.name <> ''
双流Join
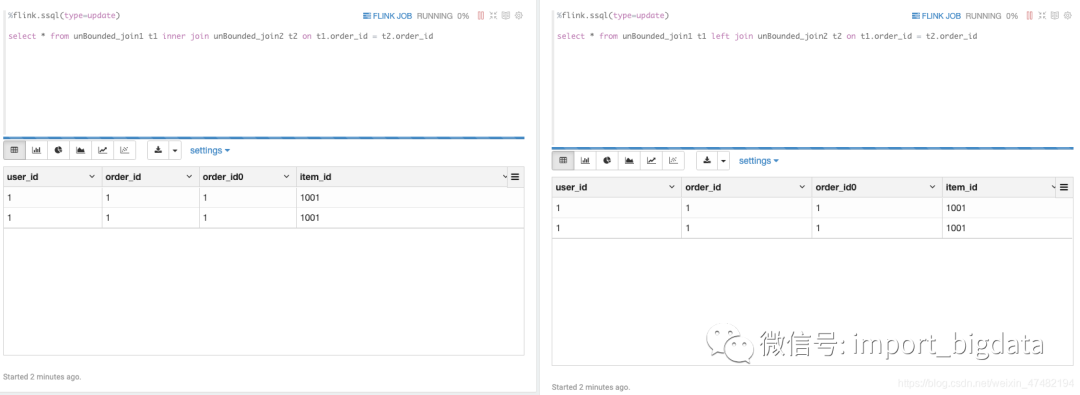
目前Flink双流Join分成两类:UnBounded Join 和 Time Interval Join。在有些场景下,用哪个都行,不过后者的性能会优于前者,而且如果在双流Join之后想要再进行窗口计算,那么只能使用Time Interval Join,目前的UnBounded Join后面是没有办法再进行Event Time的窗口计算。我们先来看一下UnBounded Join,先启动以下两个任务:%flink.ssql(type=update)再插入这样的数据到kafka:
select * from unBounded_join1 t1 inner join unBounded_join2 t2 on t1.order_id = t2.order_id
%flink.ssql(type=update)
select * from unBounded_join1 t1 left join unBounded_join2 t2 on t1.order_id = t2.order_id
%flink.ssql我们来观察一下结果:
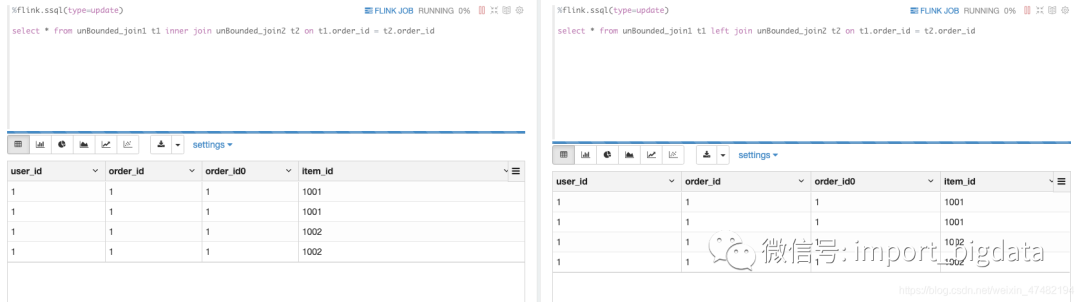
insert into unBounded_join1 select 1,1;
insert into unBounded_join1 select 1,1;
insert into unBounded_join2 select 1,1001;
-- insert into unBounded_join2 select 1,1002;
%flink.ssql(type=update)
select t1.user_id,t1.order_id,t1.ts,t2.order_id,t2.item_id,t2.ts from timeInterval_join1 t1
inner join timeInterval_join2 t2
on t1.order_id = t2.order_id
and (t2.r_t between t1.r_t - interval '10' second and t1.r_t + interval '10' second )
%flink.ssql(type=update)
select t1.user_id,t1.order_id,t1.ts,t2.order_id,t2.item_id,t2.ts from timeInterval_join1 t1
left join timeInterval_join2 t2
on t1.order_id = t2.order_id
and (t2.r_t between t1.r_t - interval '10' second and t1.r_t + interval '10' second )
%flink.ssql(type=update)
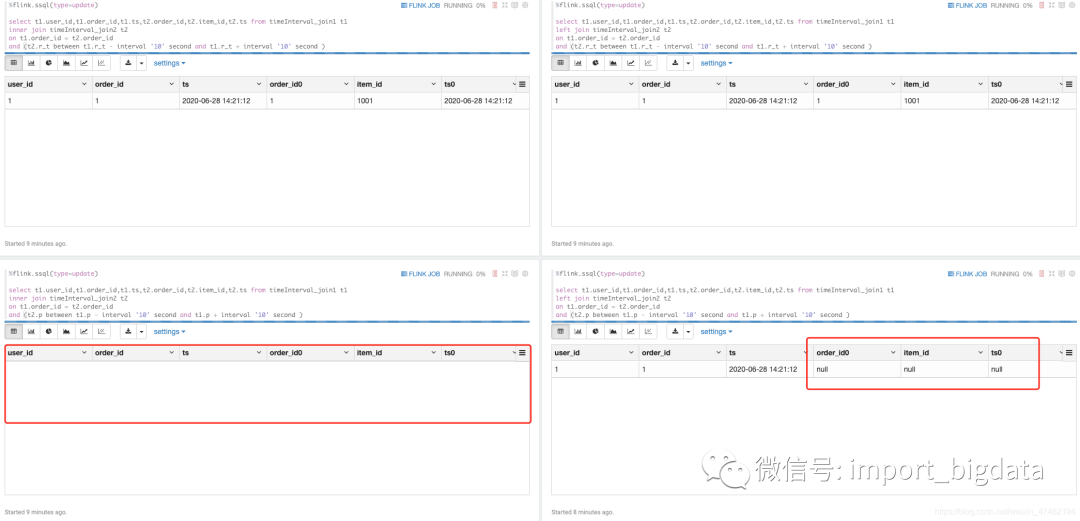
select t1.user_id,t1.order_id,t1.ts,t2.order_id,t2.item_id,t2.ts from timeInterval_join1 t1
inner join timeInterval_join2 t2
on t1.order_id = t2.order_id
and (t2.p between t1.p - interval '10' second and t1.p + interval '10' second )
%flink.ssql(type=update)然后让我们插入数据。注意一点的是,第一条语句先执行,执行完过10秒以上,再执行第二条语句
select t1.user_id,t1.order_id,t1.ts,t2.order_id,t2.item_id,t2.ts from timeInterval_join1 t1
left join timeInterval_join2 t2
on t1.order_id = t2.order_id
and (t2.p between t1.p - interval '10' second and t1.p + interval '10' second )
%flink.ssql然后让我们插入数据。注意一点的是,第一条语句先执行,执行完过10秒以上,再执行第二条语句:
-- 先执行我,执行完过10秒以上再执行下面被注释的语句
insert into timeInterval_join1 select 1,1,'2020-06-28 14:21:12';
-- 我得过10秒再执行
-- insert into timeInterval_join2 select 1,1001,'2020-06-28 14:21:12';
%flink.ssql直接看最终结果:
-- 先执行我,执行完过10秒以上再执行下面被注释的语句
insert into timeInterval_join1 select 1,1,'2020-06-28 14:21:12';
-- 我得过10秒再执行
-- insert into timeInterval_join2 select 1,1001,'2020-06-28 14:21:12';

英雄惜英雄-当Spark遇上Zeppelin之实战案例
Flink SQL 1.11 on Zeppelin集成指南
欢迎点赞+收藏+转发朋友圈素质三连
文章不错?点个【在看】吧!
评论