
Flink SQL高效Top-N方案的实现原理

https://www.jianshu.com/p/dea467eb67e0
Top-N
Top-N是我们应用Flink进行业务开发时的常见场景,传统的DataStream API已经有了非常成熟的实现方案,如果换成Flink SQL,又该怎样操作?好在Flink SQL官方文档已经给出了标准答案,我们只需要照抄就行,其语法如下:
SELECT [column_list]
FROM (
SELECT [column_list],
ROW_NUMBER() OVER ([PARTITION BY col1[, col2...]]
ORDER BY col1 [asc|desc][, col2 [asc|desc]...]) AS rownum
FROM table_name)
WHERE rownum <= N [AND conditions]看官可能已经能够在日常工作中熟练应用这种查询风格了。那么,Flink内部是如何将它转化成高效的执行方案的呢?接下来基于最新的Flink 1.12版本稍微探究一下。
Logical Plan
使用EXPLAIN语句观察示例查询的执行计划(部分)如下:
EXPLAIN PLAN FOR SELECT * FROM (
SELECT *,
row_number() OVER(PARTITION BY merchandiseId ORDER BY totalQuantity DESC) AS rownum
FROM (
SELECT merchandiseId, sum(quantity) AS totalQuantity
FROM rtdw_dwd.kafka_order_done_log
GROUP BY merchandiseId
)
) WHERE rownum <= 10
== Abstract Syntax Tree ==
LogicalProject(merchandiseId=[$0], totalQuantity=[$1], rownum=[$2])
+- LogicalFilter(condition=[<=($2, 10)])
+- LogicalProject(merchandiseId=[$0], totalQuantity=[$1], rownum=[ROW_NUMBER() OVER (PARTITION BY $0 ORDER BY $1 DESC NULLS LAST)])
+- ...
== Optimized Logical Plan ==
Rank(strategy=[RetractStrategy], rankType=[ROW_NUMBER], rankRange=[rankStart=1, rankEnd=10], partitionBy=[merchandiseId], orderBy=[totalQuantity DESC], select=[merchandiseId, totalQuantity, w0$o0])
+- Exchange(distribution=[hash[merchandiseId]])
+- ...
== Physical Execution Plan ==
Stage 1 : Data Source
...
Stage 2 : Operator
...
Stage 4 : Operator
...
Stage 6 : Operator
content : Rank(strategy=[RetractStrategy], rankType=[ROW_NUMBER], rankRange=[rankStart=1, rankEnd=10], partitionBy=[merchandiseId], orderBy=[totalQuantity DESC], select=[merchandiseId, totalQuantity, w0$o0])
ship_strategy : HASH由执行计划可知,row_number() OVER(PARTITION BY ...)子句在逻辑计划阶段被优化成了名为Rank的RelNode(看官可参见Calcite的相关资料了解RelNode),可以用如下的简图说明。
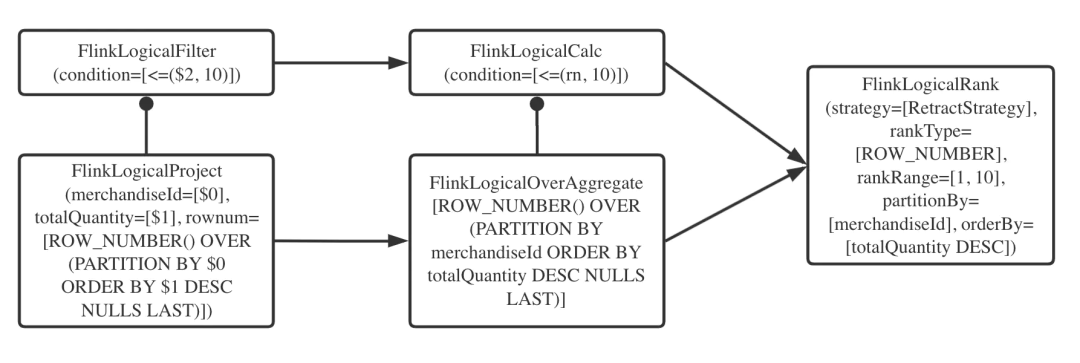 负责这个优化的RelOptRule在Flink项目中名为FlinkLogicalRankRule。它将符合规则的开窗聚合操作(FlinkLogicalOverAggregate RelNode)和对排名的过滤操作(FlinkLogicalCalc RelNode)合并为FlinkLogicalRank。也就是说,只有严格符合上一节所述语法的查询才能得到优化。
负责这个优化的RelOptRule在Flink项目中名为FlinkLogicalRankRule。它将符合规则的开窗聚合操作(FlinkLogicalOverAggregate RelNode)和对排名的过滤操作(FlinkLogicalCalc RelNode)合并为FlinkLogicalRank。也就是说,只有严格符合上一节所述语法的查询才能得到优化。
FlinkLogicalRank节点会记录以下主要信息:
partitionKey:
分组键。
orderKey:
排序键与排序规则。
rankType:
排名函数的类型,即ROW_NUMBER、RANK或者DENSE_RANK。
rankRange:
排名区间(即Top-N一词中的N)。
strategy:
Top-N结果的更新策略,目前有3种:
AppendFast:
结果只追加,不更新;
Retract:
类似于回撤流,结果会更新,前提是输入数据没有主键,或者主键与partitionKey不同;
UpdateFast:
快速更新,前提是输入数据有主键,且结果单调递增/递减,还要求orderKey的排序规则与结果的单调性相反(例:
ORDER BY sum(quantity) DESC)。
可见它的效率最高,但是也最苛刻。
outputRankNumber:
是否输出排名的序号,即在外层查询中是否有SELECT rownum子句。
显然,如果不输出序号,在排名发生变化时可以大大减少回撤输出的数据量,降低Flink端的压力,具体可参见官方文档"No Ranking Output Optimization"一节。
Physical Plan
在流处理环境下,StreamPhysicalRankRule规则负责将FlinkLogicalRank逻辑节点转换成StreamPhysicalRankRule物理节点,并翻译成物理执行节点StreamExecRank。注意如果是分组Top-N(即有PARTITION BY子句),就会按照partitionKey的hash值分发到各个sub-task,否则会将并行度强制设为1,计算全局Top-N。另外从代码可以读出,Top-N语法目前仅支持ROW_NUMBER,暂时还不支持RANK和DENSE_RANK排名。
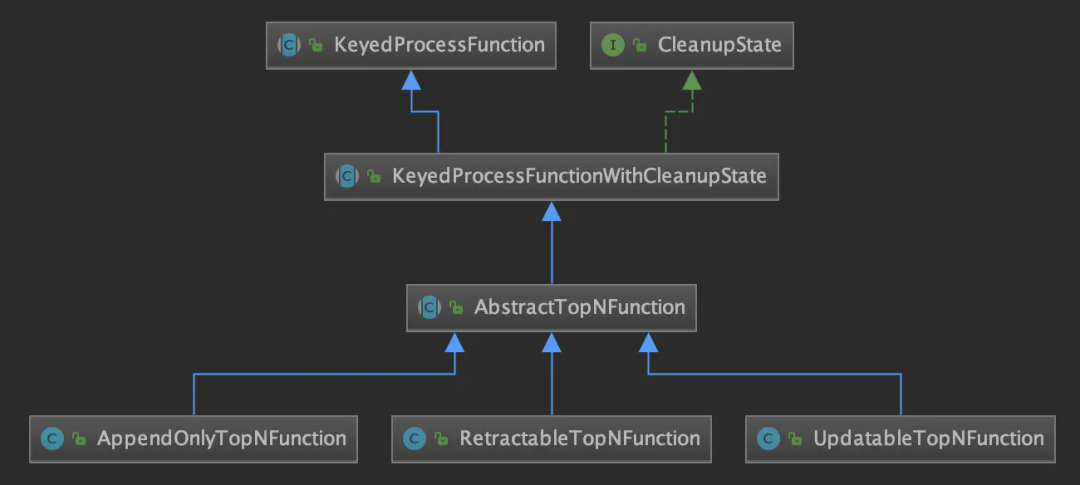
根据上文所述更新策略的不同,实际执行时采用的ProcessFunction也不同,如下类图所示。其中CleanupState接口表示支持空闲状态保留时间(idle state retention time)特性。
以最常用到的RetractableTopNFunction为例,当有一条累加数据到来时,处理流程可以用如下的简图来说明。
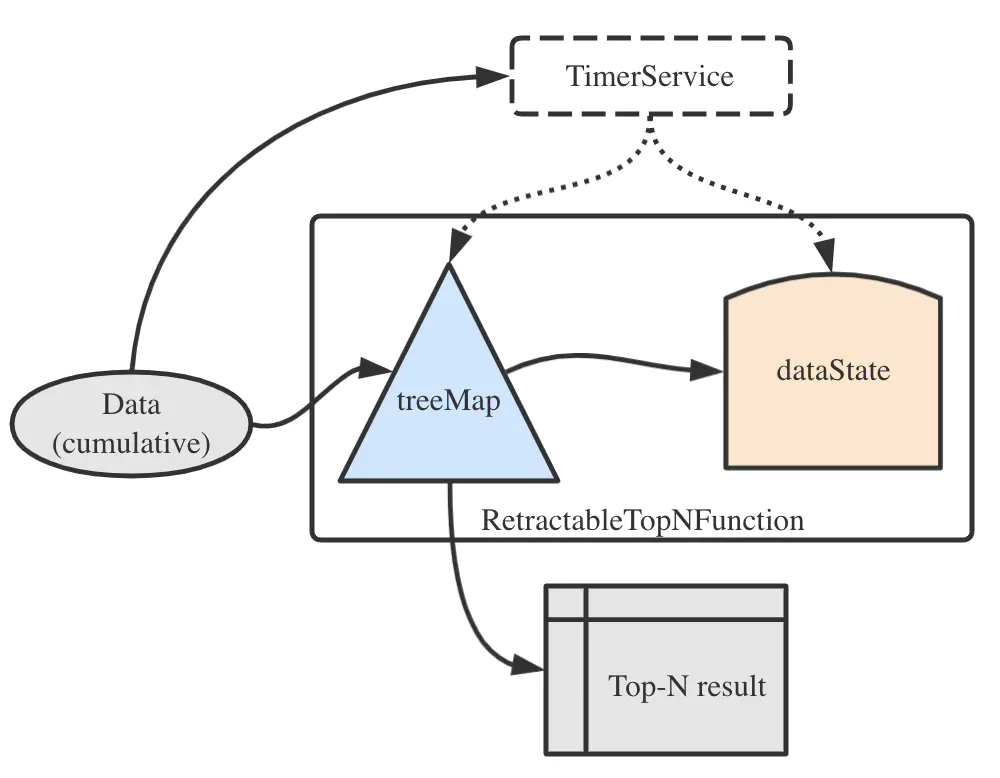 其中,dataState是MapState
其中,dataState是MapState
另外,我们一定要记得启用空闲状态保留时间,这样dataState和treeMap中的数据才不会永远积攒下去。不过空闲状态的清理并非确定性的,所以如果要计算有时间维度的排行榜(如按天、按小时等),需要把时间维度也加入PARTITION BY子句,而不是将保留时间设为对应的长度。
最后,在StreamExecRank中还提供了一个可配置的参数table.exec.topn.cache-size(默认值10000),即Top-N缓存的大小。如果Top-N的规模比较大,适当增加此值可以避免频繁访问状态,提高执行效率。
数仓建模分层理论
数据湖是谁?那数据仓库又算什么?
数仓架构发展史
Hive整合Hbase
Hive中的锁的用法场景
数仓建模方法论