
Flink SQL 在字节跳动的优化与实践
摘要:本文由 Apache Flink Committer,字节跳动架构研发工程师李本超分享,以四个章节来介绍 Flink 在字节的应用实战。 内容如下:
整体介绍
实践优化
流批一体
未来规划
Tips:点击文末「阅读原文」可查看作者原版分享视频~
一、整体介绍
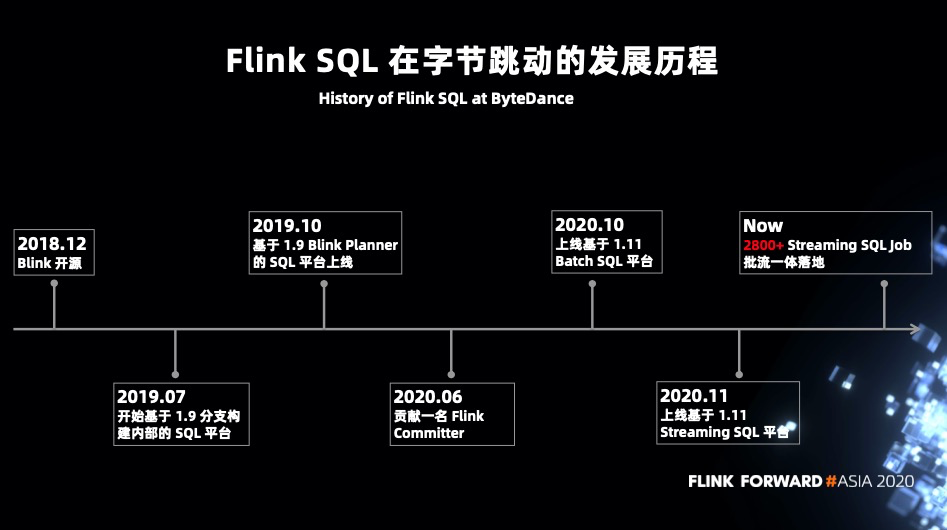
2018 年 12 月 Blink 宣布开源,经历了约一年的时间 Flink 1.9 于 2019 年 8 月 22 发布。在 Flink 1.9 发布之前字节跳动内部基于 master 分支进行内部的 SQL 平台构建。经历了 2~3 个月的时间字节内部在 19 年 10 月份发布了基于 Flink 1.9 的 Blink planner 构建的 Streaming SQL 平台,并进行内部推广。在这个过程中发现了一些比较有意思的需求场景,以及一些较为奇怪的 BUG。
基于 1.9 的 Flink SQL 扩展
create table create view create function add resource
source: RocketMQ sink: RocketMQ/ClickHouse/Doris/LogHouse/Redis/Abase/Bytable/ByteSQL/RPC/Print/Metrics
在线的界面化 SQL 平台
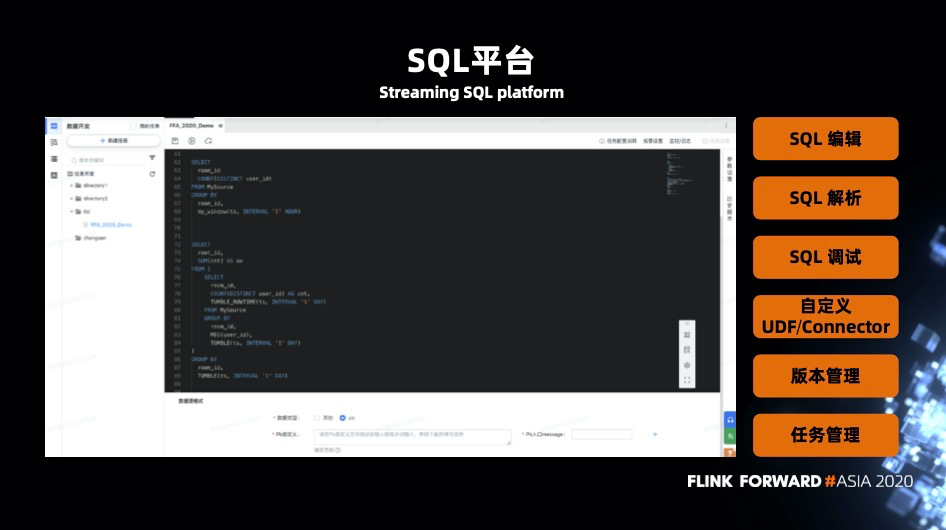
除了对 Flink 本身功能的扩展,字节内部也上线了一个 SQL 平台,支持以下功能:
SQL 编辑 SQL 解析 SQL 调试 自定义 UDF 和 Connector 版本控制 任务管理
二、实践优化
Window 性能优化
-- my_window 为自定义的窗口,满足特定的划分方式SELECTroom_id,COUNT(DISTINCT user_id)FROM MySourceGROUP BYroom_id,my_window(ts, INTERVAL '1' HOURS)
SELECTroom_id,COUNT(DISTINCT user_id)FROM MySourceGROUP BYroom_id,TUMBLE(ts, INTERVAL '7' DAY, INTERVAL '3', DAY)
维表优化
所以用户希望如果 Join 不到,则暂时将数据缓存起来之后再进行尝试,并且可以控制尝试次数,能够自定义延迟 Join 的规则。这个需求场景不单单在字节内部,社区的很多同学也有类似的需求。
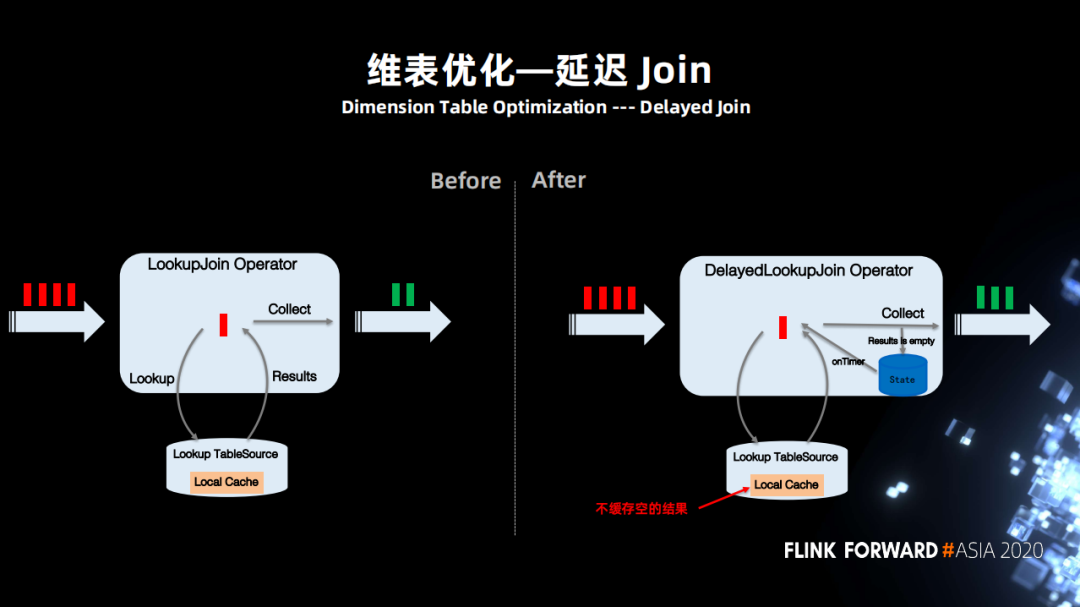

当作业并行度比较大,每一个维表 Join 的 subtask,访问的是所有的缓存空间,这样对缓存来说有很大的压力。
广播维表:有些场景下维表比较小,而且更新不频繁,但作业的 QPS 特别高。如果依然访问外部系统进行 Join,那么压力会非常大。并且当作业 Failover 的时候 local cache 会全部失效,进而又对外部系统造成很大访问压力。那么改进的方案是定期全量 scan 维表,通过Join key hash 的方式发送到下游,更新每个维表 subtask 的缓存。 Mini-Batch:主要针对一些 I/O 请求比较高,系统又支持 batch 请求的能力,比如说 RPC、HBase、Redis 等。以往的方式都是逐条的请求,且 Async I/O 只能解决 I/O 延迟的问题,并不能解决访问量的问题。通过实现 Mini-Batch 版本的维表算子,大量降低维表关联访问外部存储次数。
Join 优化
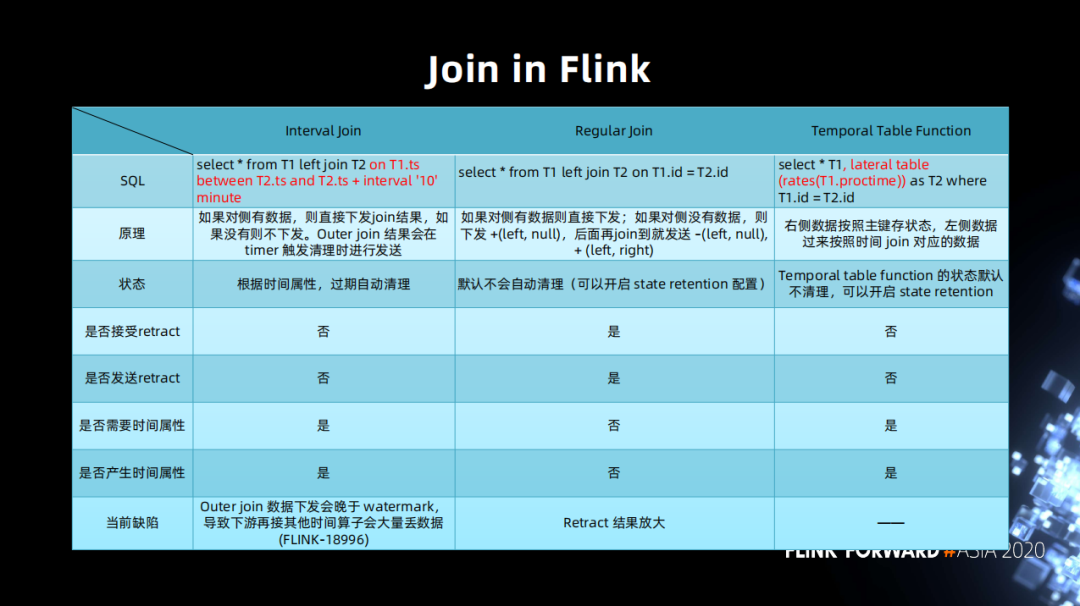
Interval Join 目前使用上的缺陷是它会产生一个 out join 数据和 watermark 乱序的情况。 Regular Join 的话,它最大的缺陷是 retract 放大(之后会详细说明这个问题)。 Temporal table function 的问题较其它多一些,有三个问题。
不支持 DDl 不支持 out join 的语义 (FLINK-7865 的限制) 右侧数据断流导致 watermark 不更新,下游无法正确计算 (FLINK-18934)
增强 Checkpoint 恢复能力
第一点:operate ID 是自动生成的,然后因为某些原因导致它生成的 ID 改变了。
第二点:算子的计算的逻辑发生了改变,即算子内部的状态的定义发生了变化。

下图左上是正常的社区版的作业会产生的一个逻辑, source 和后面的并行度一样的算子会被 chain 在一起,用户是无法去改变的。但算子并行度是常会会发生修改,比如说 source 由原来的 100 修改为 50,cacl 的并发是 100。此时 chain 的逻辑就会发生变化。
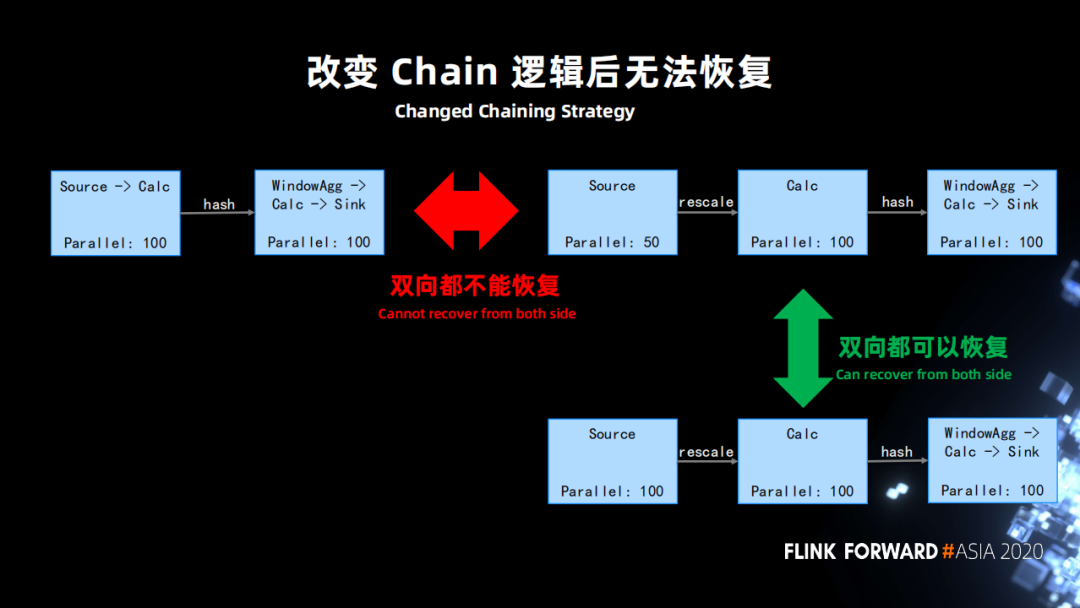
为了处理这种情况,支持了一种特殊的配置模式,允许用户配置生成 operator ID 的时候可以忽略下游 chain 在一起算子数量的条件。
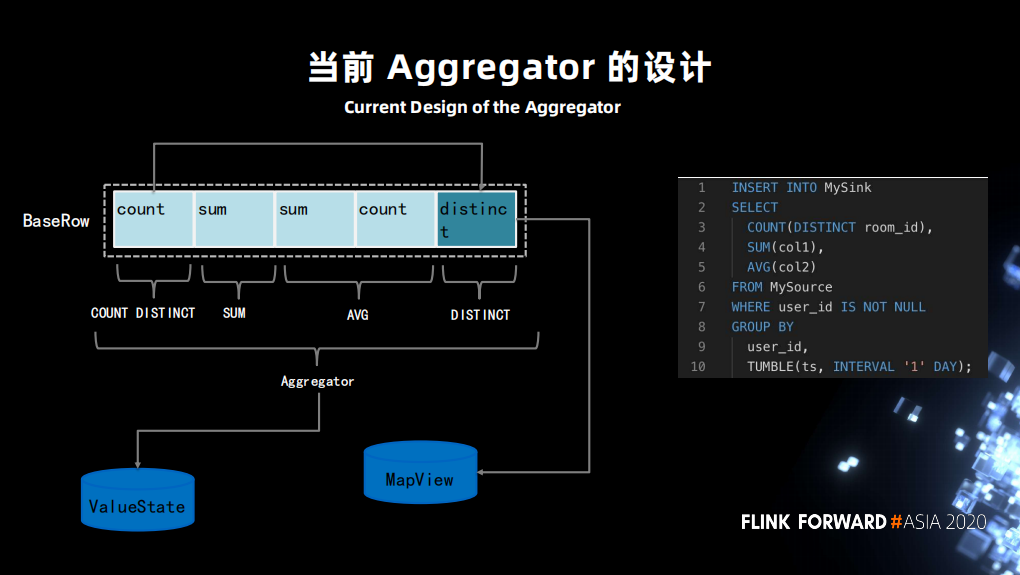
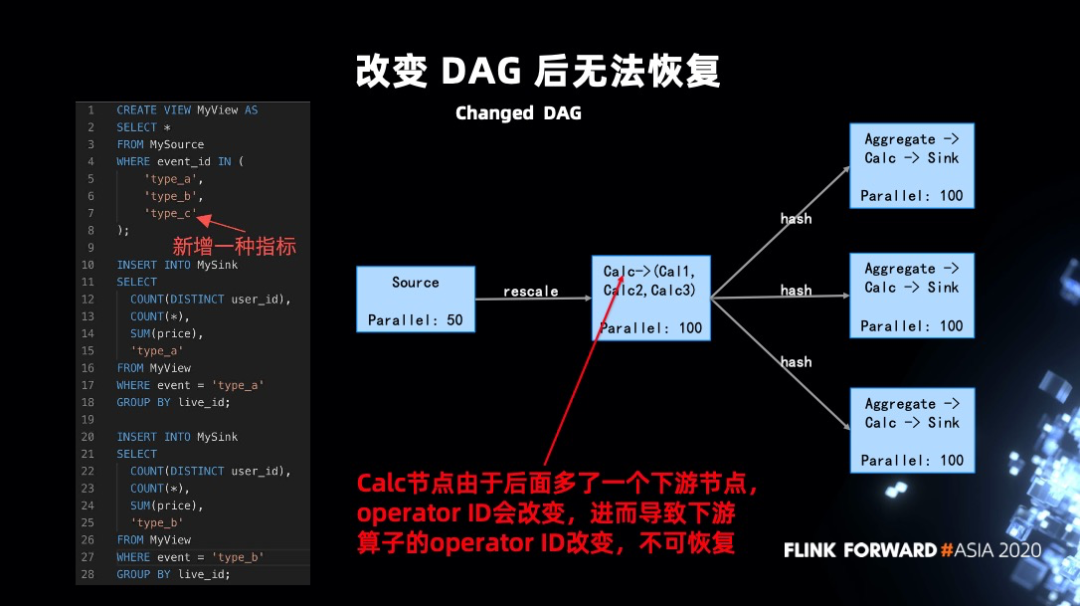
这导致了如新增或者减少指标,都会使原先的状态没办法从 ValueState 中正常恢复,因为 VauleState 中存储的状态 “schema” 和新的(修改指标后)的 “schema”不匹配,无法正常反序列化。
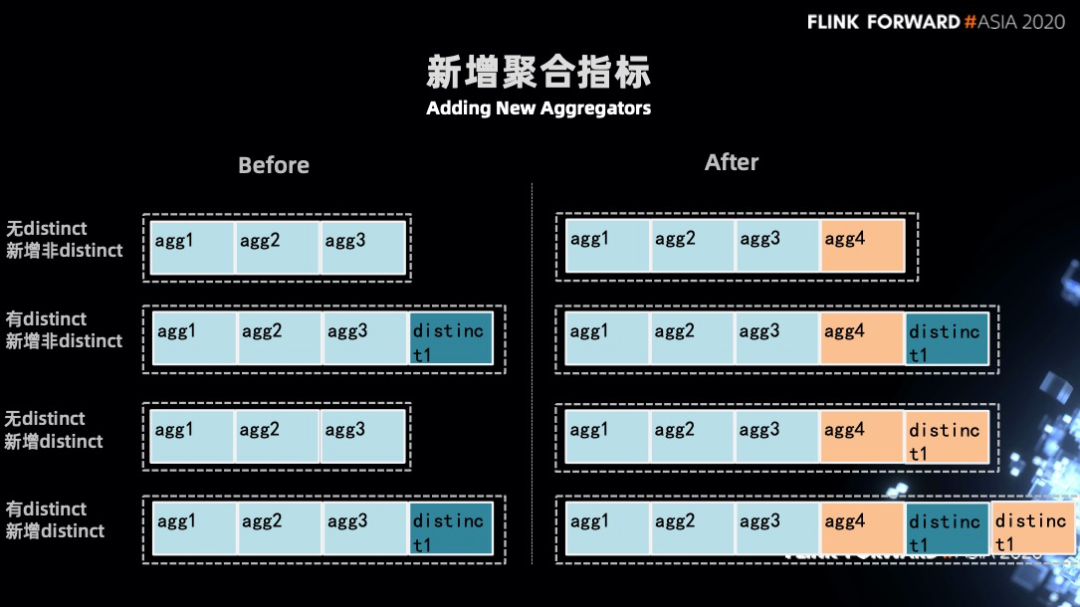
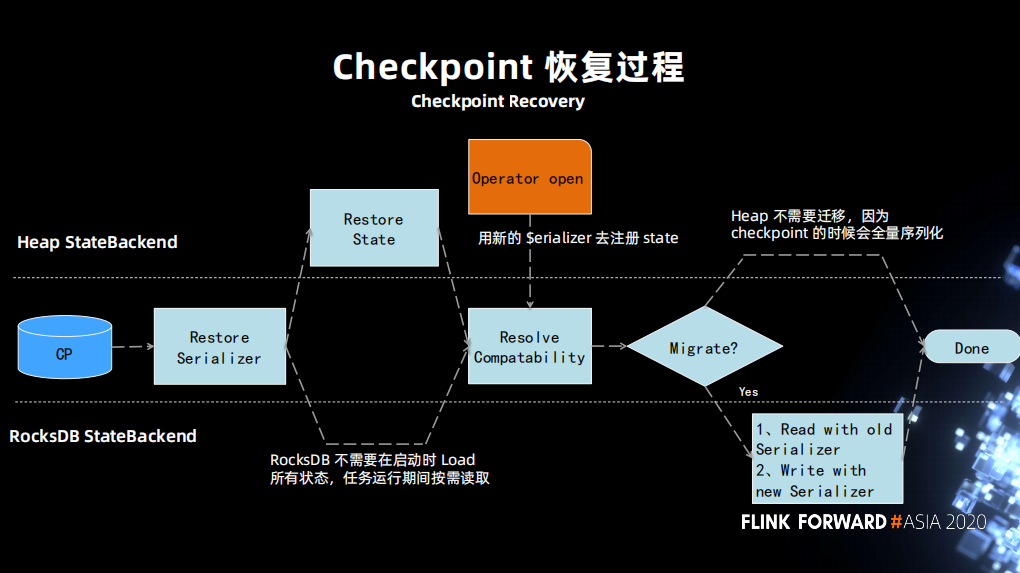
不兼容的另一种处理情况是允许返回一个 migration(实现两个不匹配类型的状态恢复)那么也可以恢复成功。
第一步使新旧 serializer 互相知道对方的信息,添加一个接口,且修改了 statebackend resolve compatibility 的过程,把旧的信息传递给新的,并使其获取整个 migrate 过程。 第二步判断新老之间是否兼容,如果不兼容是否需要做一次 migration。然后让旧的 serializer 去恢复一遍状态,并使用新的 serializer 写入新的状态。 对 aggregation 的代码生成进行处理,当发现 aggregation 拿到的是指标是 null,那么将做一些初始化的工作。
三、流批一体探索
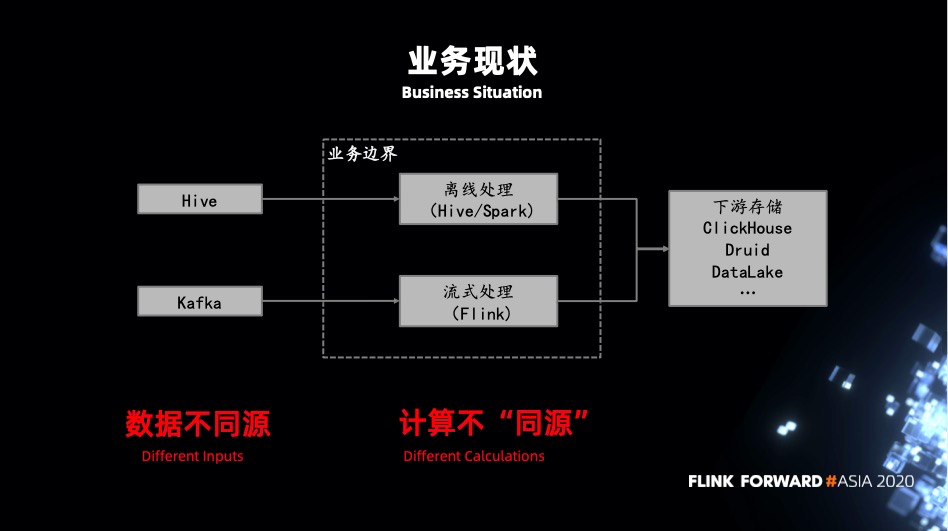
业务现状
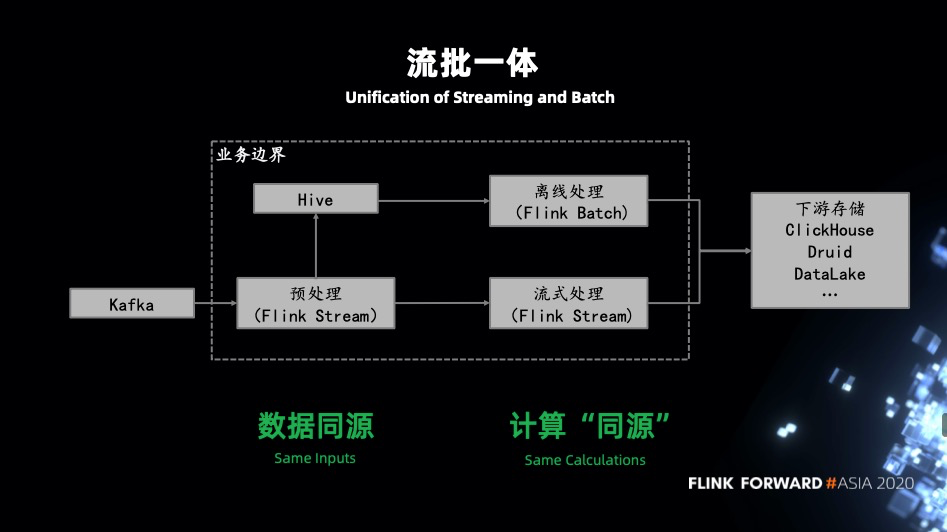
流批一体
数据不同源:批任务一般会有一次前置处理任务,不管是离线的也好实时的也好,预先进过一层加工后写入 Hive。而实时任务是从 kafka 读取原始的数据,可能是 json 格式,也可能是 avro 等等。直接导致批任务中可执行的 SQL 在流任务中没有结果生成或者执行结果不对。 计算不同源:批任务一般是 Hive + Spark 的架构,而流任务基本都是基于 Flink。不同的执行引擎在实现上都会有一些差异,导致结果不一致。不同的执行引擎有不同的 API 定义 UDF,它们之间也是无法被公用的。大部分情况下都是维护两套基于不同 API 实现的相同功能的 UDF。
数据不同源:流式处理先通过 Flink 处理之后写入 MQ 供下游流式 Flink job 去消费,对于批式处理由 Flink 处理后流式写入到 Hive,再由批式的 Flink job 去处理。 引擎不同源:既然都是基于 Flink 开发的流式,批式 job,自然没有计算不同源问题,同时也避免了维护多套相同功能的 UDF。
业务收益
统一的 SQL:通过一套 SQL 来表达流和批计算两种场景,减少开发维护工作。 复用 UDF:流式和批式计算可以共用一套 UDF。这对业务来说是有积极意义的。 引擎统一:对于业务的学习成本和架构的维护成本都会降低很多。 优化统一:大部分的优化都是可以同时作用在流式和批式计算上,比如对 planner、operator 的优化流和批可以共享。
四、未来工作和规划
优化 retract 放大问题

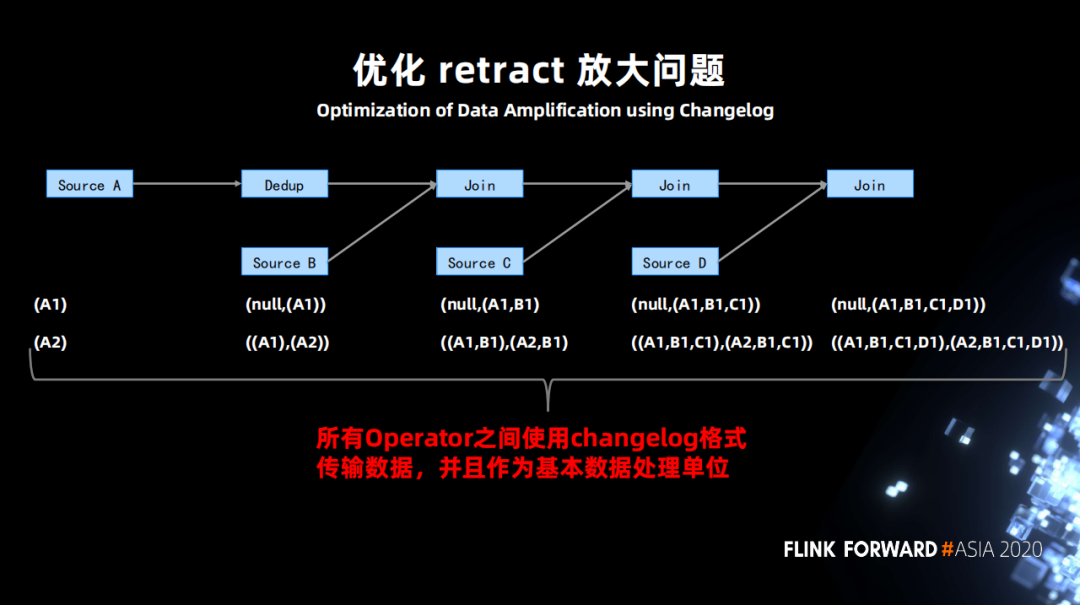
将原先 retract 的两条数据变成一条 changelog 的格式数据,在算子之间传递。算子接收到 changelog 后处理变更,然后仅仅向下游发送一个变更 changelog 即可。

1.功能优化
支持所有类型聚合指标变更的 checkpoint 恢复能力
window local-global
事件时间的 Fast Emit
广播维表
更多算子的 Mini-Batch 支持:维表,TopN,Join 等
全面兼容 Hive SQL 语法
2.业务扩展
进一步推动流式 SQL 达到 80%
探索落地流批一体产品形态
推动实时数仓标准化
评论