
Flink之Watermark详解
在上一篇文章中我们介绍了窗口相关的内容彻底搞清Flink中的Window(Flink版本1.8),那么问题来了,比如公司组织春游,规定周六早晨8:00 ~ 8:30清查人数,人齐则发车出发,可是总有那么个同学会睡懒觉迟到,这时候通常也会等待20分钟,但是不能一直等下去,如果到了20分钟则认为,想自己在家过周末,不参与春游活动了,不会继续等待了,直接出发。
这种机制跟这里要讲的watermark机制是一个意思。指的是,由于网络延迟等原因,一条数据会迟到计算,比如使用event time来划分窗口,我们知道窗口中的数据是计算一段时间的数据,如果一个数据来晚了,它的时间范围已经不属于这个窗口了,则会被丢弃,但他的event time实际上是属于这个窗口的。引入watermark机制则会等待晚到的数据一段时间,等待时间到则触发计算,如果数据延迟很大,通常也会被丢弃或者另外处理。
1. 基本概念是什么
Window:Window是处理无界流的关键,Windows将流拆分为一个个有限大小的buckets,可以可以在每一个buckets中进行计算;
start_time,end_time:当Window时时间窗口的时候,每个window都会有一个开始时间和结束时间(前开后闭),这个时间是系统时间;
event-time: 事件发生时间,是事件发生所在设备的当地时间,比如一个点击事件的时间发生时间,是用户点击操作所在的手机或电脑的时间;
Watermarks:可以把他理解为一个水位线,等于evevtTime - delay(比如规定为20分钟),一旦Watermarks大于了某个window的end_time,就会触发此window的计算,Watermarks就是用来触发window计算的。
推迟窗口触发的时间,实现方式:通过当前窗口中最大的eventTime-延迟时间所得到的Watermark与窗口原始触发时间进行对比,当Watermark大于窗口原始触发时间时则触发窗口执行!!!我们知道,流处理从事件产生,到流经source,再到operator,中间是有一个过程和时间的,虽然大部分情况下,流到operator的数据都是按照事件产生的时间顺序来的,但是也不排除由于网络、分布式等原因,导致乱序的产生,所谓乱序,就是指Flink接收到的事件的先后顺序不是严格按照事件的Event Time顺序排列的。
那么此时出现一个问题,一旦出现乱序,如果只根据eventTime决定window的运行,我们不能明确数据是否全部到位,但又不能无限期的等下去,此时必须要有个机制来保证一个特定的时间后,必须触发window去进行计算了,这个特别的机制,就是Watermark。
Watermark是一种衡量Event Time进展的机制。
Watermark是用于处理乱序事件的,而正确的处理乱序事件,通常用Watermark机制结合window来实现。
数据流中的Watermark用于表示timestamp小于Watermark的数据,都已经到达了,因此,window的执行也是由Watermark触发的。
Watermark可以理解成一个延迟触发机制,我们可以设置Watermark的延时时长t,每次系统会校验已经到达的数据中最大的maxEventTime,然后认定eventTime小于maxEventTime - t的所有数据都已经到达,如果有窗口的停止时间等于maxEventTime – t,那么这个窗口被触发执行。
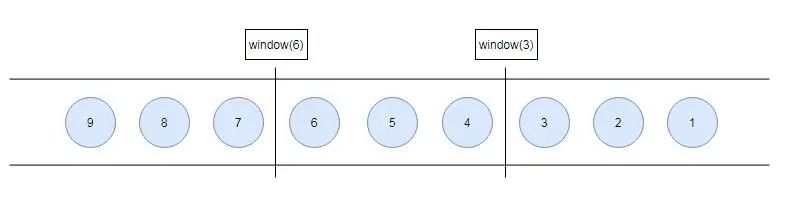
有序流的Watermarker如下图所示:(Watermark设置为0)
乱序流的Watermarker如下图所示:(Watermark设置为2)
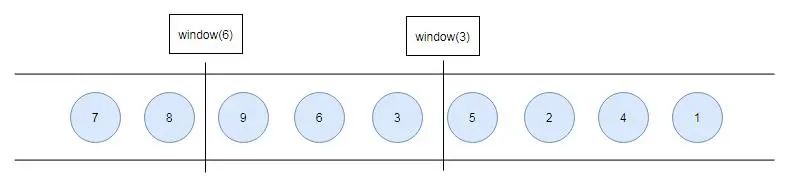
当Flink接收到数据时,会按照一定的规则去生成Watermark,这条Watermark就等于当前所有到达数据中的maxEventTime - 延迟时长,也就是说,Watermark是由数据携带的,一旦数据携带的Watermark比当前未触发的窗口的停止时间要晚,那么就会触发相应窗口的执行。由于Watermark是由数据携带的,因此,如果运行过程中无法获取新的数据,那么没有被触发的窗口将永远都不被触发。
上图中,我们设置的允许最大延迟到达时间为2s,所以时间戳为5s的事件对应的Watermark是3s,时间戳为9s的事件的Watermark是7s,如果我们的窗口1是1s-3s,窗口2是4s-6s,那么时间戳为5s的事件到达时的Watermarker恰好触发窗口1,时间戳为9s的事件到达时的Watermark触发窗口2。
Watermark 就是触发前一窗口的“关窗时间”,一旦触发关门那么以当前时刻为准在窗口范围内的所有所有数据都会收入窗中。只要没有达到水位那么不管现实中的时间推进了多久都不会触发关窗。
2. Watermark的引入
watermark的引入很简单,对于乱序数据,最常见的引用方式如下:
datastream
.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor<String>(Time.milliseconds(maxOutOfOrderness)) {
@Override
public long extractTimestamp(String element) {
return Long.valueOf(JSON.parseObject(element).getString("time"));
}
})
Event Time的使用通常要指定数据源中的时间戳,否则程序无法知道事件的事件时间是什么(数据源里的数据没有时间戳的话,就只能使用Processing Time了)。
我们看到上面的例子中创建了一个看起来有点复杂的类,这个匿名类实现的其实就是分配时间戳的接口。Flink暴露了TimestampAssigner接口供我们实现,使我们可以自定义如何从事件数据中抽取时间戳,必须通过env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)指定通过时间事件EventTime来分配数据。
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 必须指定
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
MyAssigner有两种类型
AssignerWithPeriodicWatermarks
AssignerWithPunctuatedWatermarks
以上两个接口都继承自TimestampAssigner,区别是
定期水位线(Assigner with periodic watermarks)
上面讲述了根据从事件数据中去获取时间戳设置水位线,但存在的问题是没有达到水位线时不管现实中的时间推进了多久都不会触发关窗,所以接下来我们就来介绍下定期水位线(Periodic Watermark)按照固定时间间隔生成新的水位线,不管是否有新的消息抵达,水位线提升的时间间隔是由用户设置的,在两次水位线提升时隔内会有一部分消息流入,用户可以根据这部分数据来计算出新的水位线。举个例子,最简单的水位线算法就是取目前为止最大的事件时间,然而这种方式比较暴力,对乱序事件的容忍程度比较低,容易出现大量迟到事件。
应用定期水位线需要实现AssignerWithPeriodicWatermarks API,以下是 Flink 1.9 官网提供的定期水位线的实现例子。
public class BoundedOutOfOrdernessGenerator implements AssignerWithPeriodicWatermarks<MyEvent> {
private final long maxOutOfOrderness = 3500; // 3.5 seconds
private long currentMaxTimestamp;
@Override
public long extractTimestamp(MyEvent element, long previousElementTimestamp) {
long timestamp = element.getCreationTime();
currentMaxTimestamp = Math.max(timestamp, currentMaxTimestamp);
return timestamp;
}
@Override
public Watermark getCurrentWatermark() {
// return the watermark as current highest timestamp minus the out-of-orderness bound
// 当前最大时间戳减去maxOutOfOrderness,就是watermark
return new Watermark(currentMaxTimestamp - maxOutOfOrderness);
}
}
其中extractTimestamp用于从消息中提取事件时间,而getCurrentWatermark用于生成新的水位线,新的水位线只有大于当前水位线才是有效的。每个窗口都会有该类的一个实例,因此可以利用实例的成员变量保存状态,比如上例中的当前最大时间戳
注:周期性的(一定时间间隔或者达到一定的记录条数)产生一个Watermark。在实际的生产中Periodic的方式必须结合时间和积累条数两个维度继续周期性(默认200ms)产生Watermark,否则在极端情况下会有很大的延时。
@PublicEvolving
public void setStreamTimeCharacteristic(TimeCharacteristic characteristic) {
this.timeCharacteristic = Preconditions.checkNotNull(characteristic);
if (characteristic == TimeCharacteristic.ProcessingTime) {
// 如果是ProcessingTime,那么默认时间间隔是0,一直不会过滤时间。
getConfig().setAutoWatermarkInterval(0);
} else {
// 如果是EventTime,则autoWatermarkInterval设置为200ms
getConfig().setAutoWatermarkInterval(200);
}
}
深入到assignTimestampsAndWatermarks里面,TimestampsAndPeriodicWatermarksOperator有一个定时回调任务:
@Override
public void open() throws Exception {
super.open();
currentWatermark = Long.MIN_VALUE;
watermarkInterval = getExecutionConfig().getAutoWatermarkInterval();
if (watermarkInterval > 0) {
long now = getProcessingTimeService().getCurrentProcessingTime();
getProcessingTimeService().registerTimer(now + watermarkInterval, this);
}
}
里面大家感兴趣可以继续看一下,定时回调的方法,将符合要求的watermark发送出去并且注册下一个定时器。
标点水位线(Assigner with punctuated watermarks)
标点水位线(Punctuated Watermark)通过数据流中某些特殊标记事件来触发新水位线的生成。这种方式下窗口的触发与时间无关,而是决定于何时收到标记事件。
应用标点水位线需要实现AssignerWithPunctuatedWatermarks API,以下是 Flink 1.9 官网提供的标点水位线的实现例子。
public class PunctuatedAssigner implements AssignerWithPunctuatedWatermarks<MyEvent> {
@Override
public long extractTimestamp(MyEvent element, long previousElementTimestamp) {
return element.getCreationTime();
}
@Override
public Watermark checkAndGetNextWatermark(MyEvent lastElement, long extractedTimestamp) {
return lastElement.hasWatermarkMarker() ? new Watermark(extractedTimestamp) : null;
}
}
其中extractTimestamp用于从消息中提取事件时间,checkAndGetNextWatermark用于检查事件是否标点事件,若是则生成新的水位线。不同于定期水位线定时调用getCurrentWatermark,标点水位线是每接受一个事件就需要调用checkAndGetNextWatermark,若返回值非 null 且新水位线大于当前水位线,则触发窗口计算
注:数据流中每一个递增的EventTime都会产生一个Watermark。在实际的生产中Punctuated方式在TPS很高的场景下会产生大量的Watermark在一定程度上对下游算子造成压力,所以只有在实时性要求非常高的场景才会选择Punctuated的方式进行Watermark的生成。
迟到事件
虽说水位线表明着早于它的事件不应该再出现,但是上如上文所讲,接收到水位线以前的的消息是不可避免的,这就是所谓的迟到事件。实际上迟到事件是乱序事件的特例,和一般乱序事件不同的是它们的乱序程度超出了水位线的预计,导致窗口在它们到达之前已经关闭。
迟到事件出现时窗口已经关闭并产出了计算结果,因此处理的方法有3种:
重新激活已经关闭的窗口并重新计算以修正结果。
将迟到事件收集起来另外处理。
将迟到事件视为错误消息并丢弃。
Flink 默认的处理方式是第3种直接丢弃,其他两种方式分别使用Side Output和Allowed Lateness。
Side Output机制可以将迟到事件单独放入一个数据流分支,这会作为 window 计算结果的副产品,以便用户获取并对其进行特殊处理。
Allowed Lateness机制允许用户设置一个允许的最大迟到时长。Flink 会再窗口关闭后一直保存窗口的状态直至超过允许迟到时长,这期间的迟到事件不会被丢弃,而是默认会触发窗口重新计算。因为保存窗口状态需要额外内存,并且如果窗口计算使用了 ProcessWindowFunction API 还可能使得每个迟到事件触发一次窗口的全量计算,代价比较大,所以允许迟到时长不宜设得太长,迟到事件也不宜过多,否则应该考虑降低水位线提高的速度或者调整算法。
// 侧输出
SingleOutputStreamOperator<Tuple2<String, Long>> lateOutputTag = new OutputTag<>("lateOutputTag");
DataStream<Tuple2<String, Long>> dataStream = senv.addSource(
new FlinkKafkaConsumer010<>(
config.get("kafka-topic"),
new SimpleStringSchema(),
kafkaProps
))
//设置watermark
.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor<String>(Time.milliseconds(maxOutOfOrderness)) {
@Override
public long extractTimestamp(String element) {
return Long.valueOf(JSON.parseObject(element).getString("time"));
}
}).map(x -> {
JSONObject message = JSON.parseObject(x);
return Tuple2.of(message.getString("name"), 1L);
})
.returns(Types.TUPLE(Types.STRING, Types.LONG))
.keyBy(value -> value.f0)
.window(TumblingEventTimeWindows.of(Time.seconds(3)))
// 窗口会等待5s
.allowedLateness(Time.milliseconds(5000))
// 另外收集起来
.sideOutputLateData(lateOutputTag)
.process(new ProcessWindowFunction<Tuple2<String, Long>, Tuple2<String, Long>, String, TimeWindow>() {
@Override
public void process(String key, Context context, Iterable<Tuple2<String, Long>> elements, Collector<Tuple2<String, Long>> out) throws Exception {
long count = 0;
for(Tuple2<String, Long> element : elements){
count = count + 1;
}
out.collect(Tuple2.of("pv-" + key, count));
}
});
// 获取迟到数据并写入对应Sink
dataStream.getSideOutput(lateOutputTag).addSink(new RichSinkFunction<Tuple2<String, Long>>() {
...
});
每个Kafka分区的Timestamp
当使用Apache Kafka座位数据源时,每个Kafka分区可能有一个简单的事件时间模式(递增的timestamp或者有界的无序)。然而,当消费Kafka中的数据时,多个分区通常是并发进行的,将事件从分区中分离开来,并销毁分区模式(这是Kafka consumer客户端固有的工作模式)。
在这种情况下,你可以使用Flink的 Kafka-partition-aware(译作:Kafka分区识别或者Kafka分区敏感)水印生成,使用这个特性,水印会在Kafka消费端的每个分区中生成,并且每个分区的水印会在stream shuffle中进行合并。
例如:如果每个Kafka分区中的事件timestamp是严格递增的话,使用ascending timestamps watermark generator(递增时间戳水印生成器)将会得到完美的整体水印。
下图展示了如何使用per-kafka-partition水印生成,以及水印是如何在流式数据流中传播的。
FlinkKafkaConsumer09<MyType> kafkaSource = new FlinkKafkaConsumer09<>("myTopic", schema, props);
kafkaSource.assignTimestampsAndWatermarks(new AscendingTimestampExtractor<MyType>() {
@Override
public long extractAscendingTimestamp(MyType element) {
return element.eventTimestamp();
}
});
DataStream<MyType> stream = env.addSource(kafkaSource);