
Flink CEP 原理和案例详解
点击上方蓝色字体,选择“设为星标”




1 概念
(1)定义
复合事件处理(Complex Event Processing,CEP)是一种基于动态环境中事件流的分析技术,事件在这里通常是有意义的状态变化,通过分析事件间的关系,利用过滤、关联、聚合等技术,根据事件间的时序关系和聚合关系制定检测规则,持续地从事件流中查询出符合要求的事件序列,最终分析得到更复杂的复合事件。
(2)特征
CEP的特征如下:
目标:从有序的简单事件流中发现一些高阶特征;
输入:一个或多个简单事件构成的事件流;
处理:识别简单事件之间的内在联系,多个符合一定规则的简单事件构成复杂事件;
输出:满足规则的复杂事件。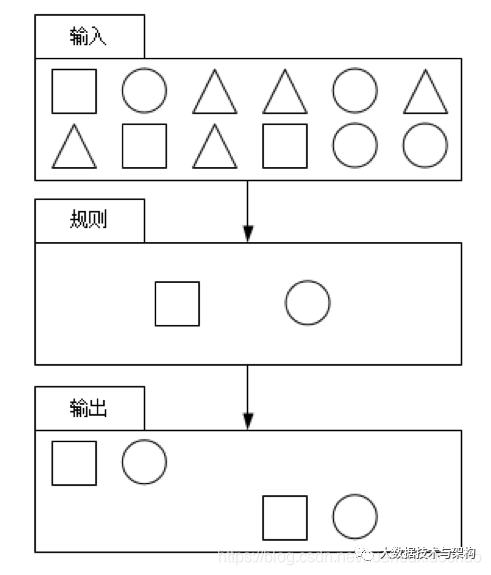
(3)功能
CEP用于分析低延迟、频繁产生的不同来源的事件流。CEP可以帮助在复杂的、不相关的时间流中找出有意义的模式和复杂的关系,以接近实时或准实时的获得通知或组织一些行为。
CEP支持在流上进行模式匹配,根据模式的条件不同,分为连续的条件或不连续的条件;模式的条件允许有时间的限制,当条件范围内没有达到满足的条件时,会导致模式匹配超时。
看起来很简单,但是它有很多不同的功能:
① 输入的流数据,尽快产生结果;
② 在2个事件流上,基于时间进行聚合类的计算;
③ 提供实时/准实时的警告和通知;
④ 在多样的数据源中产生关联分析模式;
⑤ 高吞吐、低延迟的处理
市场上有多种CEP的解决方案,例如Spark、Samza、Beam等,但他们都没有提供专门的库支持。然而,Flink提供了专门的CEP库。
(4)主要组件
Flink为CEP提供了专门的Flink CEP library,它包含如下组件:Event Stream、Pattern定义、Pattern检测和生成Alert。
首先,开发人员要在DataStream流上定义出模式条件,之后Flink CEP引擎进行模式检测,必要时生成警告。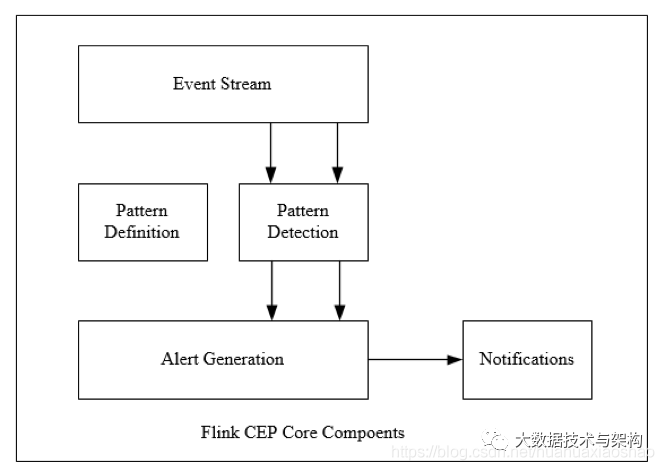
2 Pattern API
处理事件的规则,被叫作模式(Pattern)。
Flink CEP提供了Pattern API用于对输入流数据进行复杂事件规则定义,用来提取符合规则的事件序列。
模式大致分为三类:
① 个体模式(Individual Patterns)
组成复杂规则的每一个单独的模式定义,就是个体模式。
start.times(3).where(_.behavior.startsWith(‘fav’)) ② 组合模式(Combining Patterns,也叫模式序列)
很多个体模式组合起来,就形成了整个的模式序列。
模式序列必须以一个初始模式开始:
val start = Pattern.begin(‘start’)
③ 模式组(Group of Pattern)
将一个模式序列作为条件嵌套在个体模式里,成为一组模式。
2.1个体模式
个体模式包括单例模式和循环模式。单例模式只接收一个事件,而循环模式可以接收多个事件。
(1)量词
可以在一个个体模式后追加量词,也就是指定循环次数
// 匹配出现4次start.time(4)// 匹配出现0次或4次start.time(4).optional// 匹配出现2、3或4次start.time(2,4)// 匹配出现2、3或4次,并且尽可能多地重复匹配start.time(2,4).greedy// 匹配出现1次或多次start.oneOrMore// 匹配出现0、2或多次,并且尽可能多地重复匹配start.timesOrMore(2).optional.greedy
(2)条件
每个模式都需要指定触发条件,作为模式是否接受事件进入的判断依据。CEP中的个体模式主要通过调用.where()、.or()和.until()来指定条件。按不同的调用方式,可以分成以下几类:
① 简单条件
通过.where()方法对事件中的字段进行判断筛选,决定是否接收该事件
start.where(event=>event.getName.startsWith(“foo”)) ② 组合条件
将简单的条件进行合并;or()方法表示或逻辑相连,where的直接组合就相当于与and。
Pattern.where(event => …/*some condition*/).or(event => /*or condition*/) ③ 终止条件
如果使用了oneOrMore或者oneOrMore.optional,建议使用.until()作为终止条件,以便清理状态。
④ 迭代条件
能够对模式之前所有接收的事件进行处理;调用.where((value,ctx) => {…}),可以调用ctx.getEventForPattern(“name”)
2.2 模式序列
不同的近邻模式如下图: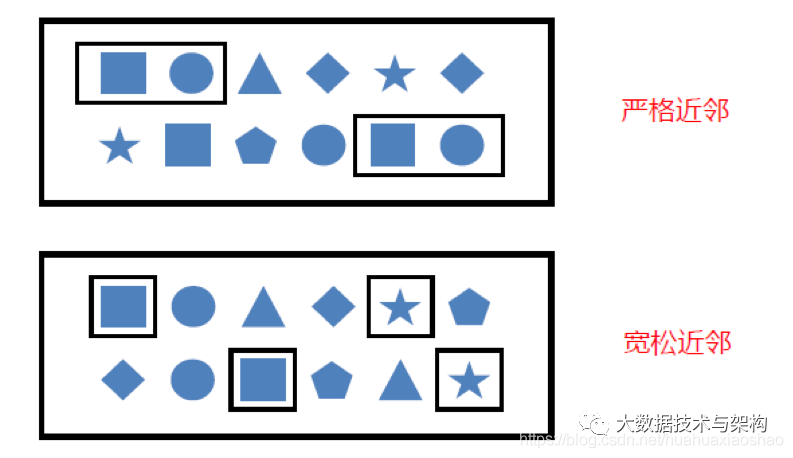
(1)严格近邻
所有事件按照严格的顺序出现,中间没有任何不匹配的事件,由.next()指定。例如对于模式“a next b”,事件序列“a,c,b1,b2”没有匹配。
(2)宽松近邻
允许中间出现不匹配的事件,由.followedBy()指定。例如对于模式“a followedBy b”,事件序列“a,c,b1,b2”匹配为{a,b1}。
(3)非确定性宽松近邻
进一步放宽条件,之前已经匹配过的事件也可以再次使用,由.followedByAny()指定。例如对于模式“a followedByAny b”,事件序列“a,c,b1,b2”匹配为{ab1},{a,b2}。
除了以上模式序列外,还可以定义“不希望出现某种近邻关系”:
.notNext():不想让某个事件严格紧邻前一个事件发生。
.notFollowedBy():不想让某个事件在两个事件之间发生。
需要注意:①所有模式序列必须以.begin()开始;②模式序列不能以.notFollowedBy()结束;③“not”类型的模式不能被optional所修饰;④可以为模式指定时间约束,用来要求在多长时间内匹配有效。
next.within(Time.seconds(10))2.3 模式的检测
指定要查找的模式序列后,就可以将其应用于输入流以检测潜在匹配。调用CEP.pattern(),给定输入流和模式,就能得到一个PatternStream。
val input:DataStream[Event] = …val pattern:Pattern[Event,_] = …val patternStream:PatternStream[Event]=CEP.pattern(input,pattern)
2.4 匹配事件的提取
创建PatternStream之后,就可以应用select或者flatSelect方法,从检测到的事件序列中提取事件了。
select()方法需要输入一个select function作为参数,每个成功匹配的事件序列都会调用它。
select()以一个Map[String,Iterable[IN]]来接收匹配到的事件序列,其中key就是每个模式的名称,而value就是所有接收到的事件的Iterable类型。
def selectFn(pattern : Map[String,Iterable[IN]]):OUT={val startEvent = pattern.get(“start”).get.nextval endEvent = pattern.get(“end”).get.nextOUT(startEvent, endEvent)}
flatSelect通过实现PatternFlatSelectFunction实现与select相似的功能。唯一的区别就是flatSelect方法可以返回多条记录,它通过一个Collector[OUT]类型的参数来将要输出的数据传递到下游。
2.5超时事件的提取
当一个模式通过within关键字定义了检测窗口时间时,部分事件序列可能因为超过窗口长度而被丢弃;为了能够处理这些超时的部分匹配,select和flatSelect API调用允许指定超时处理程序。
3 Flink CEP实战
为了使用Flink CEP,需要导入pom依赖。
<dependency><groupId>org.apache.flinkgroupId><artifactId>flink-cep-scala_2.11artifactId><version>1.7.0version>dependency>
LoginLog.csv中的数据格式为:
5402,83.149.11.115,success,155843081523064,66.249.3.15,fail,15584308265692,80.149.25.29,fail,15584308337233,86.226.15.75,success,15584308325692,80.149.25.29,success,155843084029607,66.249.73.135,success,1558430841
需求:检测一个用户在3秒内连续登陆失败。
// 输入的登录事件样例类case class LoginEvent( userId: Long, ip: String, eventType: String, eventTime: Long )// 输出的异常报警信息样例类case class Warning( userId: Long, firstFailTime: Long, lastFailTime: Long, warningMsg: String)object LoginFailWithCep {def main(args: Array[String]): Unit = {val env = StreamExecutionEnvironment.getExecutionEnvironmentenv.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)env.setParallelism(1)// 1. 读取事件数据,创建简单事件流val resource = getClass.getResource("/LoginLog.csv")val loginEventStream = env.readTextFile(resource.getPath).map( data => {val dataArray = data.split(",")LoginEvent( dataArray(0).trim.toLong, dataArray(1).trim, dataArray(2).trim, dataArray(3).trim.toLong )} ).assignTimestampsAndWatermarks( new BoundedOutOfOrdernessTimestampExtractor[LoginEvent](Time.seconds(5)) {override def extractTimestamp(element: LoginEvent): Long = element.eventTime * 1000L} ).keyBy(_.userId)// 2. 定义匹配模式val loginFailPattern = Pattern.begin[LoginEvent]("begin").where(_.eventType == "fail").next("next").where(_.eventType == "fail").within(Time.seconds(3))// 3. 在事件流上应用模式,得到一个pattern streamval patternStream = CEP.pattern(loginEventStream, loginFailPattern)// 4. 从pattern stream上应用select function,检出匹配事件序列val loginFailDataStream = patternStream.select( new LoginFailMatch() )loginFailDataStream.print()env.execute("login fail with cep job")}}class LoginFailMatch() extends PatternSelectFunction[LoginEvent, Warning]{override def select(map: util.Map[String, util.List[LoginEvent]]): Warning = {// 从map中按照名称取出对应的事件// val iter = map.get("begin").iterator()val firstFail = map.get("begin").iterator().next()val lastFail = map.get("next").iterator().next()Warning( firstFail.userId, firstFail.eventTime, lastFail.eventTime, "login fail!" )}}
4 总结
本章主要围绕scala语言来讲解Flink CEP库。其实,Flink CEP也有SQL的实现。
文章不错?点个【在看】吧! ?