从迁移学习到图像合成
地址:https://zhuanlan.zhihu.com/p/376423478
01
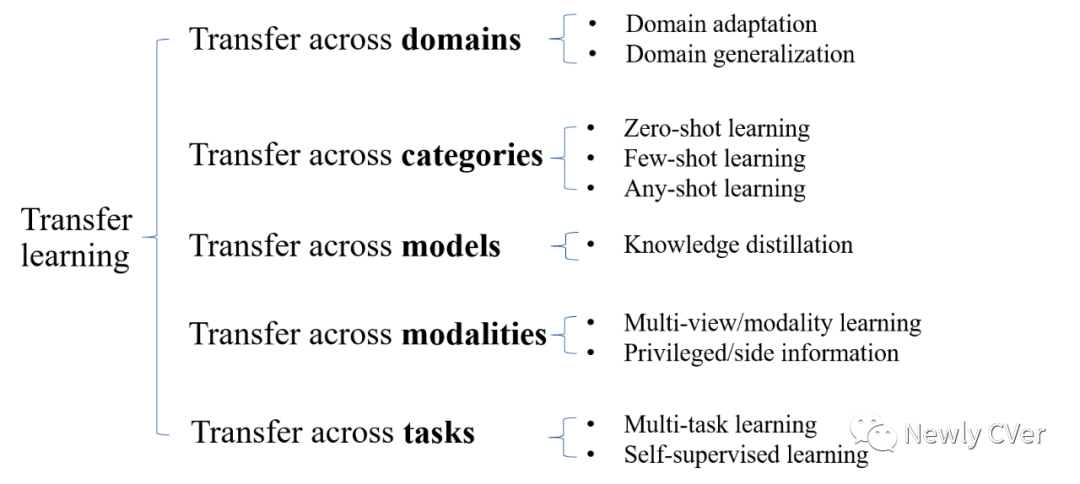
02

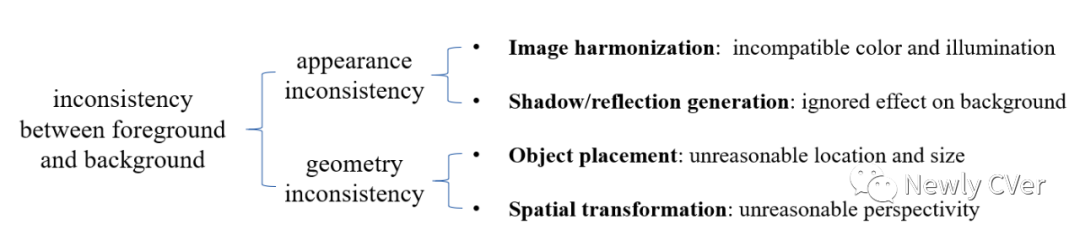

03
图像和谐化
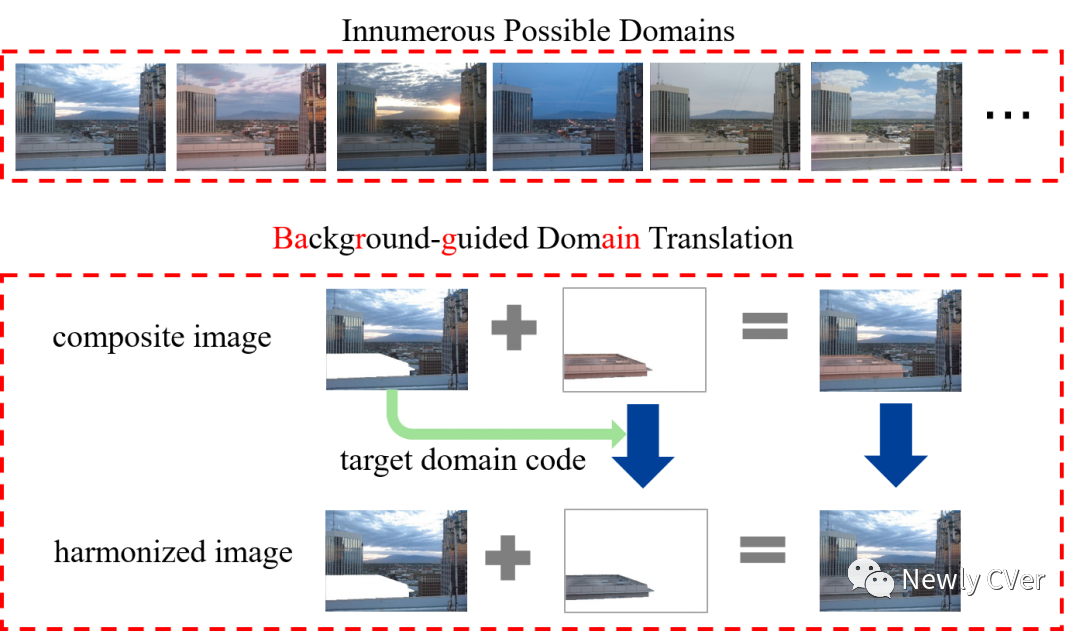
前景阴影生成

前景位置摆放
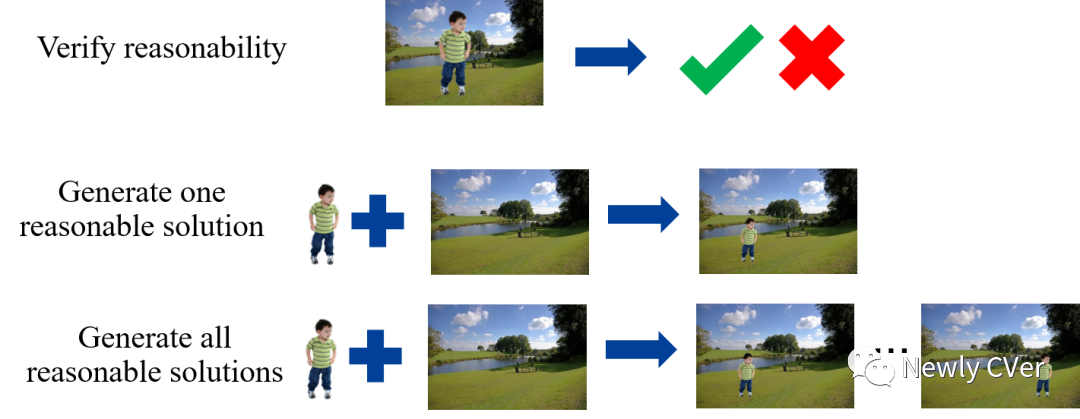
构图评估
04
猜您喜欢:
附下载 |《TensorFlow 2.0 深度学习算法实战》
附下载 | 超100篇!CVPR 2020最全GAN论文梳理汇总!
评论
 下载APP
下载APP地址:https://zhuanlan.zhihu.com/p/376423478
01
02
03
04
猜您喜欢:
附下载 |《TensorFlow 2.0 深度学习算法实战》
附下载 | 超100篇!CVPR 2020最全GAN论文梳理汇总!