
ICCV2021 | 端到端的文本图像分块矫正方法
点击下方“AI算法与图像处理”,一起进步!
重磅干货,第一时间送达

本文简要介绍ICCV2021录用论文“End-to-end Piece-wise Unwarping of Document Images”的主要工作。该论文提出将一张文档图像切分成多个Patches来进行局部矫正,这种方式相比于直接在整图上进行全局矫正能够获得更好的效果。而对比之前同样基于Patch进行局部矫正的方法[1],本文实现了Patches拼接过程的端到端可训练化,同时为拼接过程加入了全局信息,可以得到更好的拼接效果。本文方法在多个指标上好于目前的SOTAs。

一、研究背景
移动设备拍照得到的文档图像由于纸张本身包含的物理形变、相机的位置以及复杂的光照环境等因素通常质量较差。其数字化效果不如平面扫描仪得到的扫描图。为了提升拍照文档图像的质量,提高下游任务(如OCR)的性能。我们通常会对拍照得到的文档图像进行矫正,使得其更接近于扫描图。但由于相机角度、纸张形状以及光照环境的多变性和复杂性,拍照文档图像校正是一个极具挑战性的任务。
二、方法原理简述
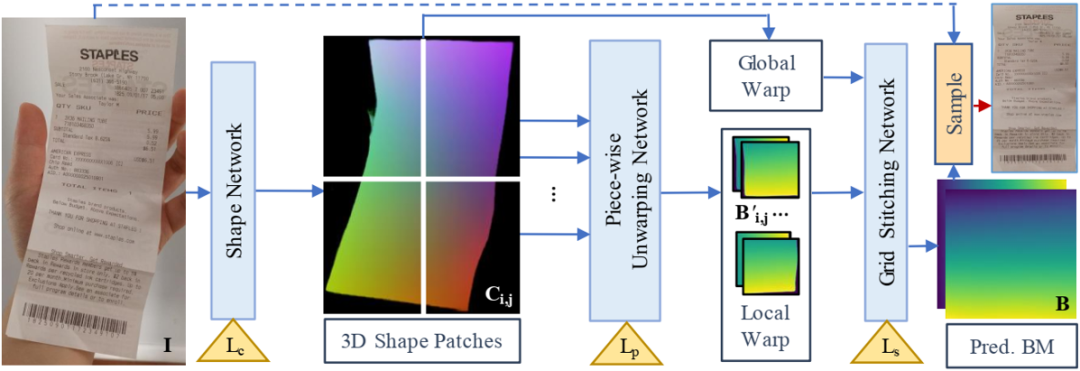
图2 网络整体框架图
图2是这篇文章所提方法的整体结构。总共由三个子网络构成,第一个网络是为了回归3D Shape Map,第二个网络是为了回归Backward Map,最后一个网络将多个Patches 的Backward Map进行拼接。
Shape Network:第一个网络采用类似于UNet的Encoder-decoder结构,将输入图 转化成3D Shape Map。3D Shape Map可以用来表征输入图的形变信息。3D Shape Map由对应的GT通过L1 Loss进行监督训练,此外对它们的梯度也计算L1 Loss:
转化成3D Shape Map。3D Shape Map可以用来表征输入图的形变信息。3D Shape Map由对应的GT通过L1 Loss进行监督训练,此外对它们的梯度也计算L1 Loss:
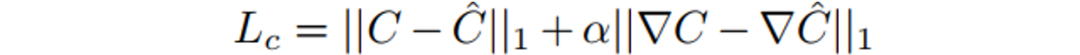
Piece-wise Unwarping Network:第二个网络以DenseNet作为主干网,以从3D Shape Map切片得到的多个Patches作为输入回归各自的Backward Map。所以第二个网络需要对数据进行切分(3D Shape Map和Backward Map都需要进行切分)。3D Shape Map的切分直接按照空间位置将其切分成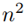 个不重叠的Patches:
个不重叠的Patches: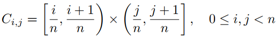 ,其中i和j分别是对Patches横向和纵向的索引。而Backward Map由于与3D Shape Map在空间位置上不是一一对应的,所以不能直接根据其空间位置进行切分,而要根据其取值进行切分:
,其中i和j分别是对Patches横向和纵向的索引。而Backward Map由于与3D Shape Map在空间位置上不是一一对应的,所以不能直接根据其空间位置进行切分,而要根据其取值进行切分:

此外由于切片后Patch相比于整图而言坐标系发生了改变,所以还需要对切片得到的Backward Map Patches进行归一化使其和新坐标系相对应。
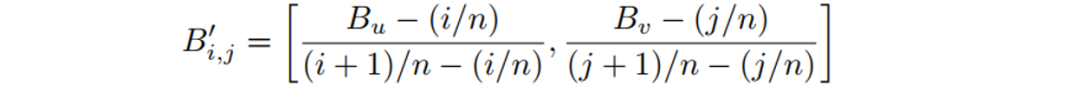
得到成对的3D Shape Map和Backward Map之后,就可以进行训练。Backward Map由对应的GT通过L1 Loss监督生成,同时还对基于Backward Map生成的矫正图计算L2 Loss:
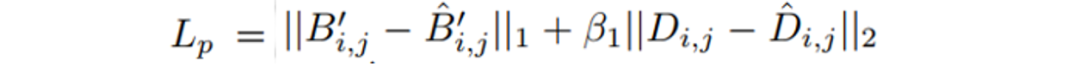
Global Stitching Network:第三个网络目的是将多个Backward Map的Patches进行拼接。先对各个Backward Map Patch进行逆归一化操作,然后再送入如图3所示的CPL模块对所有Backward Map Patches进行一个粗略的排序放置。
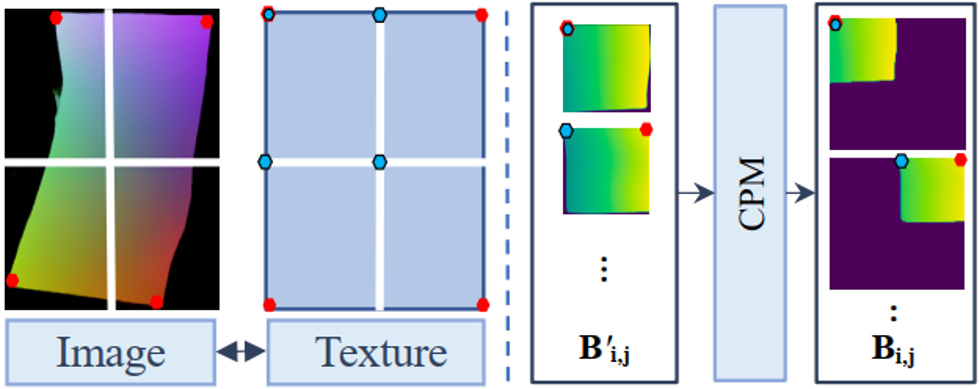
图3 CPL模块。作者基于图像校正前后大致位置不变(如形变图左上角的Patch矫正后应该还是位于矫正图的左上角)的假设来进行粗略的排序放置。
将多个粗略放置好位置的Patches Concatenate在一起之后就作为Global Stitching Network局部分支的输入,提供局部信息。此外,Global Stitching Network还包含一个全局分支:以第一个网络Shape Network得到的3D Shape Map作为输入提供全局信息。如图4所示,Global Stitching Network将两个分支中分别提取的特征进行融合之后再经过卷积网络得到最终拼接好的整图的Backward Map。
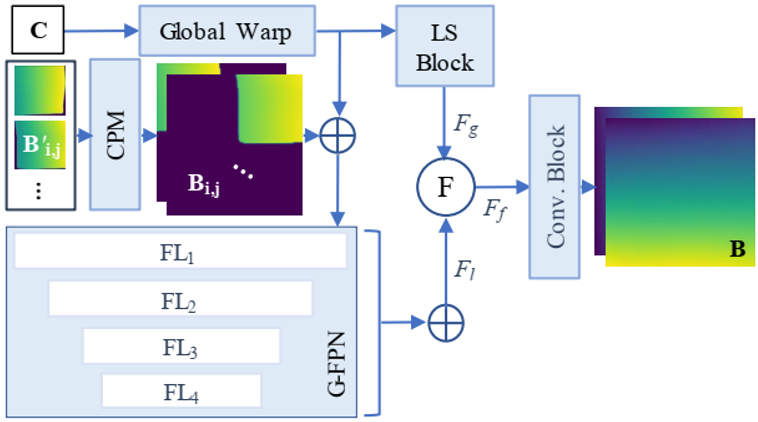
图4 Global Stitching Network的网络结构
损失函数则与Piece-wise Unwarping Network相似,对Backward Map计算L1 Loss,对由Backward Map得到的矫正图计算L2 Loss。

三、主要实验结果及可视化结果


图5 DocUNet[3]基准数据集上CER指标的分布情况。DW代表DewarpNet[2],PW代表本文方法。


图6 与DewarpNet[2]的定性比较结果。其中第1、2、3、4列分别是输入,本文方法结果,DewarpNet[2]结果以及GT。

图7 与CREASE[4]定性比较结果。第1、3列为本文方法,2、4列为CREASE[4]结果。

图8 与DocProj[1]定性比较结果。第1、3列为本文方法,2、4列为DocProj[1]结果。
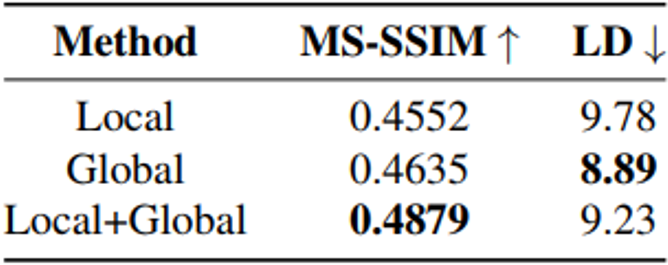
四、总结及讨论
五、相关资源
论文地址:
https://openaccess.thecvf.com/content/ICCV2021/html/Das_End-to-End_Piece-Wise_Unwarping_of_Document_Images_ICCV_2021_paper.html
项目地址:
参考文献
[1] Li, X., Zhang, B., Liao, J., & Sander, P. V. (2019). Document rectification and illumination correction using a patch-based CNN. ACM Transactions on Graphics (TOG), 38(6), 1-11.
[2] Das, S., Ma, K., Shu, Z., Samaras, D., & Shilkrot, R. (2019). Dewarpnet: Single-image document unwarping with stacked 3d and 2d regression networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision (pp. 131-140).
[3] Ma, K., Shu, Z., Bai, X., Wang, J., & Samaras, D. (2018). Docunet: Document image unwarping via a stacked u-net. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 4700-4709).
[4] Markovitz, A., Lavi, I., Perel, O., Mazor, S., & Litman, R. (2020, August). Can You Read Me Now? Content Aware Rectification Using Angle Supervision. In European Conference on Computer Vision (pp. 208-223). Springer, Cham.
原文作者: Sagnik Das, Kunwar Yashraj Singh, Jon Wu, Erhan Bas, Vijay Mahadevan, Rahul Bhotika, Dimitris Samaras
撰稿:张家鑫
免责声明:(1)本文仅代表撰稿者观点,撰稿者不一定是原文作者,其个人理解及总结不一定准确及全面,论文完整思想及论点应以原论文为准。(2)本文观点不代表本公众号立场。
交流群
欢迎加入公众号读者群一起和同行交流,目前有美颜、三维视觉、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群
个人微信(如果没有备注不拉群!) 请注明:地区+学校/企业+研究方向+昵称
下载1:何恺明顶会分享
在「AI算法与图像处理」公众号后台回复:何恺明,即可下载。总共有6份PDF,涉及 ResNet、Mask RCNN等经典工作的总结分析
下载2:终身受益的编程指南:Google编程风格指南
在「AI算法与图像处理」公众号后台回复:c++,即可下载。历经十年考验,最权威的编程规范!
下载3 CVPR2021 在「AI算法与图像处理」公众号后台回复:CVPR,即可下载1467篇CVPR 2020论文 和 CVPR 2021 最新论文
