
聊聊Flink:Flink的基础架构
一、前言
哈喽,大家好,我是微信公众号【老周聊架构】的作者老周,老周这次给大家分享下Flink系列的知识。作为Flink系列的开篇之作,我脑海中想着有没有一种很好的方式来让大家通俗易懂的了解Flink。因为你一上来就介绍Flink的一些概念和核心思想,初学的小伙伴不是那么容易接受这么生疏的东西。所以,老周想从大数据的开发总体架构来说,让大家知道Flink在大数据领域处于一个什么位置,先有个整体的概念,再对Flink娓娓道来,初始、进阶、高级,一步一步认清Flink,只有对Flink的原理掌握了,那么在开发中也会得心应手些。
二、大数据开发整体架构
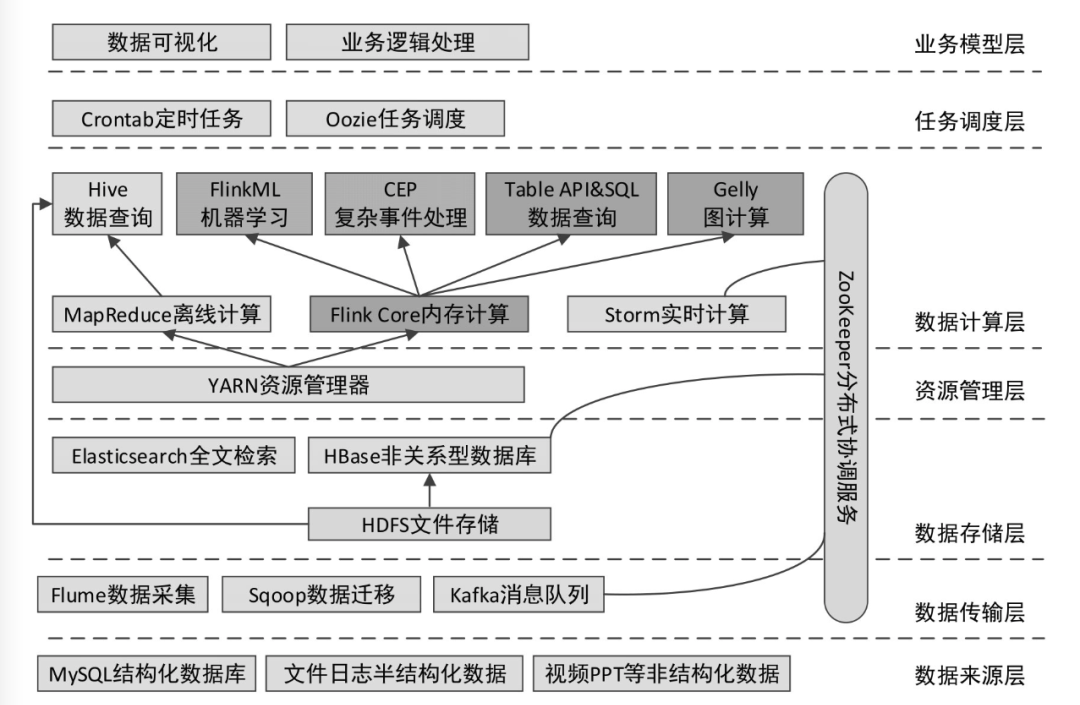
2.1 数据来源层
在大数据领域,数据的来源往往是关系型数据库、日志文件(用户在Web网站和手机App中浏览相关内容时,服务器端会生成大量的日志文件)、其他非结构化数据等。要想对这些大量的数据进行离线或实时分析,需要使用数据传输工具将其导入Hadoop平台或其他大数据集群中。
2.2 数据传输层
常用的数据传输工具有Flume、Sqoop、Kafka。Flume是一个日志收集系统,用于将大量日志数据从不同的源进行收集、聚合,最终移动到一个集中的数据中心进行存储。Sqoop主要用于将数据在关系型数据库和Hadoop平台之间进行相互转移。Kafka是一个分布式消息引擎,它可以实时处理大量消息数据以满足各种需求,相当于数据中转站。
2.3 数据存储层
数据可以存储于分布式文件系统HDFS中,也可以存储于分布式数据库HBase中,而HBase的底层实际上还是将数据存储于HDFS中。此外,为了满足对大量数据的快速检索与统计,可以使用Elasticsearch作为全文检索引擎。
2.4 资源管理层
YARN是大数据开发中常用的资源管理器,它是一个通用资源(内存、CPU)管理系统,不仅可以集成于Hadoop中,也可以集成于Flink、Spark等其他大数据框架中。
2.5 数据计算层
MapReduce是Hadoop的核心组成部分,可以结合Hive通过SQL的方式进行数据的离线计算,当然也可以单独编写MapReduce应用程序进行计算。Storm用于进行数据的实时计算,可以非常容易地实时处理无限的流数据。Flink提供了离线计算库和实时计算库两种,离线计算库支持FlinkML(机器学习)、Gelly(图计算)、基于Table的关系操作,实时计算库支持CEP(复杂事件处理),同时也支持基于Table的关系操作。
2.6 任务调度层
Oozie是一个用于Hadoop平台的工作流调度引擎,可以使用工作流的方式对编写好的大数据任务进行调度。若任务不复杂,则可以使用Linux系统自带的Crontab定时任务进行调度。
2.7 业务模型层
对大量数据的处理结果最终需要通过可视化的方式进行展示。可以使用Java、PHP等处理业务逻辑,查询结果数据库,最终结合ECharts等前端可视化框架展示处理结果。
我们从另一个角度来看看Flink在大数据开发整体架构中位置,看完估计你心里有个底了。
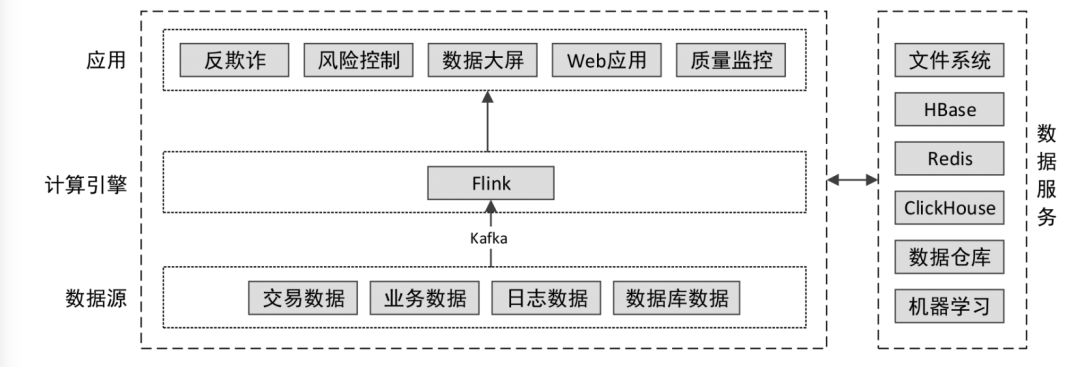
三、Flink是什么

Apache Flink是一个框架和分布式处理引擎,用于对无边界和有边界的数据流进行有状态的计算。Flink被设计为可以在所有常见集群环境中运行,并能以内存速度和任意规模执行计算。
Flink在实现流处理和批处理时,与传统的一些方案完全不同,它从另一个视角看待流处理和批处理,将二者统一起来:Flink 是完全支持流处理,也就是说作为流处理看待时输入数据流是无界的;批处理被作为一种特殊的流处理,只是它的输入数据流被定义为有界的。基 于同一个Flink运行时(Flink Runtime),分别提供了流处理和批处理API,而这两种API也是实现上层面向流处理、批处理类型应用框架的基础。
我们再来看离线批计算与实时流计算:
批计算:有界流
流式计算:无界流
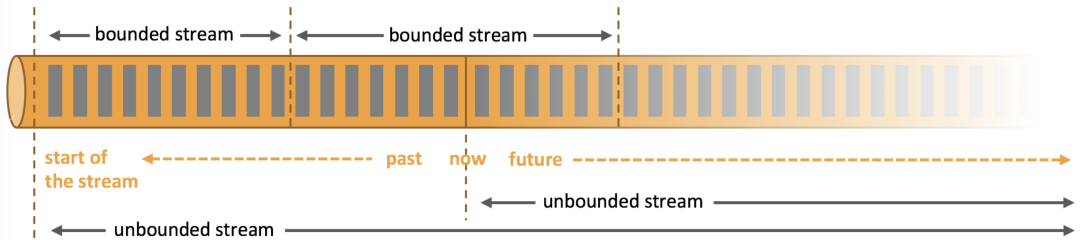
-
批计算:针对有界流,在计算结果前可以看到整个数据集。
-
流计算:针对无界流,永远无法看到输入数据的整体,数据的输入无法看到结束,数据到达就计算,输出当时(实时)的计算结果;输出结果也是一个无界流;数据到达也可以理解为可以把无界流变成有界流在计算,比如时间划分,数据量划分。
这里Flink把流计算和批计算进行了API层面的统一,是一个流批一体的计算框架。
3.1 Flink的特性
3.1.1 Flink核心特性
-
支持高吞吐、低延迟、高性能的流处理
-
支持带有事件时间的窗口(Window)操作
-
支持有状态计算的 Exactly-once 语义
-
支持高度灵活的窗口(time/count/session)Window 操作,以及 data-driven 驱动
-
支持具有 BackPressure 功能的持续流模型
-
支持基于轻量级分布式快照(Snapshot)实现的容错
-
一个运行时同时支持 Batch on Streaming 处理和 Streaming 处理
-
Flink 在 JVM 内部实现了自己的内存管理
-
支持迭代计算
-
支持程序自动优化:避免特定情况下 Shuffle、排序等昂贵操作,中间结果进行缓存。
3.1.2 Flink特点
-
Correctness guarantees: 恰好一次状态一致性、事件时间处理、复杂的后期数据处理
-
Layered APIs: 流式和批量数据上的 SQL、数据流 API 和数据集 API、ProcessFunction(时间和状态)
-
Operational focus: 灵活部署、可靠性、checkpoint
-
Scalability: 横向扩展架构、支持非常大的状态、增量检查点
-
Performance: 低延迟、高吞吐量、内存计算
3.1.3 Flink关键特性
-
低延时:提供 ms 级时延的处理能力
-
Exactly Once:提供异步快照机制,保证所有数据真正处理一次
-
HA:JobManager 支持主备模式,保证无单点故障
-
水平扩展能力:TaskManager 支持手动水平扩展
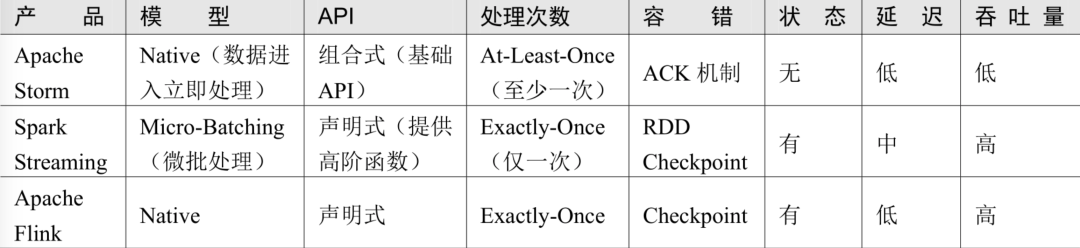
3.2 流计算框架对比
四、Flink的主要组件
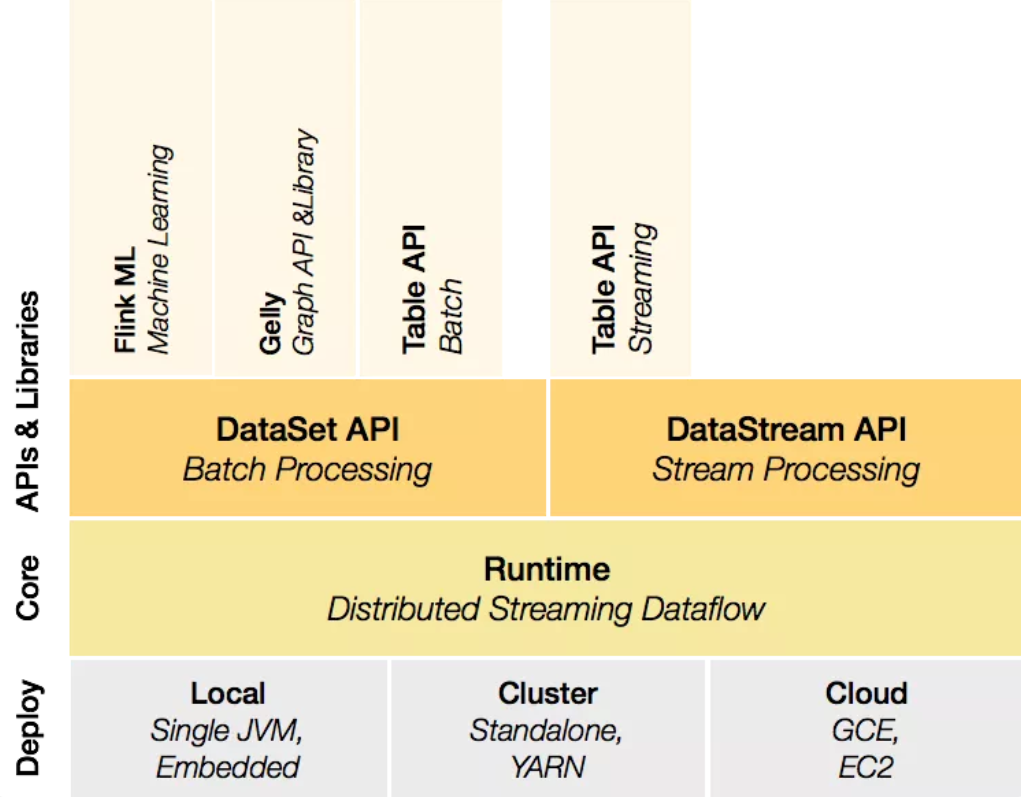
-
Deploy层:该层主要涉及了Flink的部署模式,Flink支持多种部署模式:本地、集群(Standalone/YARN)、云(GCE/EC2),Standalone部署模式与Spark类似。
-
Runtime层:Runtime层提供了支持Flink计算的全部核心实现,比如:支持分布式Stream处理、Job Graph到Execution Graph的映射、调度 等,为上层API层提供基础服务。
-
API层:API层主要实现了面向无界Stream的流处理和面向Batch的批处理API,其中面向流处理对应DataStream API,面向批处理对应DataSet API。
-
Libraries层:该层也可以称为Flink应用框架层,根据API层的划分,在API层之上构建的满足特定应用的实时计算框架,也分别对应于面向流处理和面向批处理两类。面向流处理支持:CEP(复杂事件处理)、SQL-like的操作(基于Table的关系操作);面向批处理支持:FlinkML(机器学习库)、Gelly(图处理)。
五、编程接口
Flink提供了丰富的数据处理接口,并将接口抽象成3层,由下向上分别为Stateful Stream Processing API、DataStream/DataSet API、SQL/Table API,开发者可以根据具体需求选择任意一层接口进行应用开发。
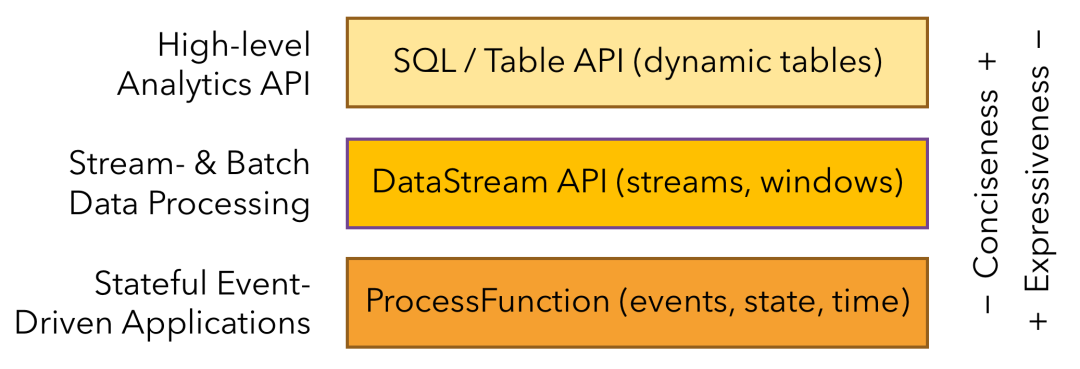
5.1 Stateful Stream Processing API
Flink中处理有状态流最底层的接口,它通过Process Function(低阶API,Flink提供的最具表达力的底层接口)嵌入DataStream API中,允许用户自由地处理一个或多个流中的事件,并使用一致的容错状态。此外,用户可以注册事件时间和处理时间回调,从而允许程序实现复杂的计算。用户可以通过这个API接口操作状态、时间等底层数据。
使用Stateful Stream Process API接口可以实现非常复杂的流式计算逻辑,开发灵活性非常强,但是用户使用成本也相对较高。
5.2 DataStream/DataSet API
实际上,大多数应用程序不需要上述低级抽象,而是针对核心API进行编程的,例如DataStream API和DataSet API。DataStream API用于处理无界数据集,即流处理;DataSet API用于处理有界数据集,即批处理。这两种API都提供了用于数据处理的通用操作,例如各种形式的转换、连接、聚合等。
低级Process Function与DataStream API集成在一起,从而使得仅对某些操作进行低级抽象成为可能。DataSet API在有限的数据集上提供了其他原语,例如循环/迭代。
5.3 SQL/Table API
Table API作为批处理和流处理统一的关系型API,即查询在无界实时流或有界批数据集上以相同的语义执行,并产生相同的结果。Flink中的Table API通常用于简化数据分析、数据流水线和ETL应用程序的定义。
Table API构建在DataStream/DataSet API之上,提供了大量编程接口,例如GroupByKey、Join等操作,是批处理和流处理统一的关系型API,使用起来更加简洁。使用Table API允许在表与DataStream/DataSet数据集之间无缝切换,并且可以将Table API与DataStream/DataSet API混合使用。
Table API的原理是将内存中的DataStream/DataSet数据集在原有的基础上增加Schema信息,将数据类型统一抽象成表结构,然后通过Table API提供的接口处理对应的数据集,从而简化数据分析。
此外,Table API程序还会通过优化规则在数据处理过程中对处理逻辑进行大量优化。
Flink提供的最高级别的抽象是SQL API。这种抽象在语义和表达方式上均类似于Table API,但是将程序表示为SQL查询表达式。SQL抽象与Table API紧密交互,并且可以对Table API中定义的表执行SQL查询。此外,SQL语言具有比较低的学习成本,能够让数据分析人员和开发人员快速上手。
六、程序结构
在Hadoop中,实现一个MapReduce应用程序需要编写Map和Reduce两部分;在Storm中,实现一个Topology需要编写Spout和Bolt两部分;同样,实现一个Flink应用程序也需要同样的逻辑。
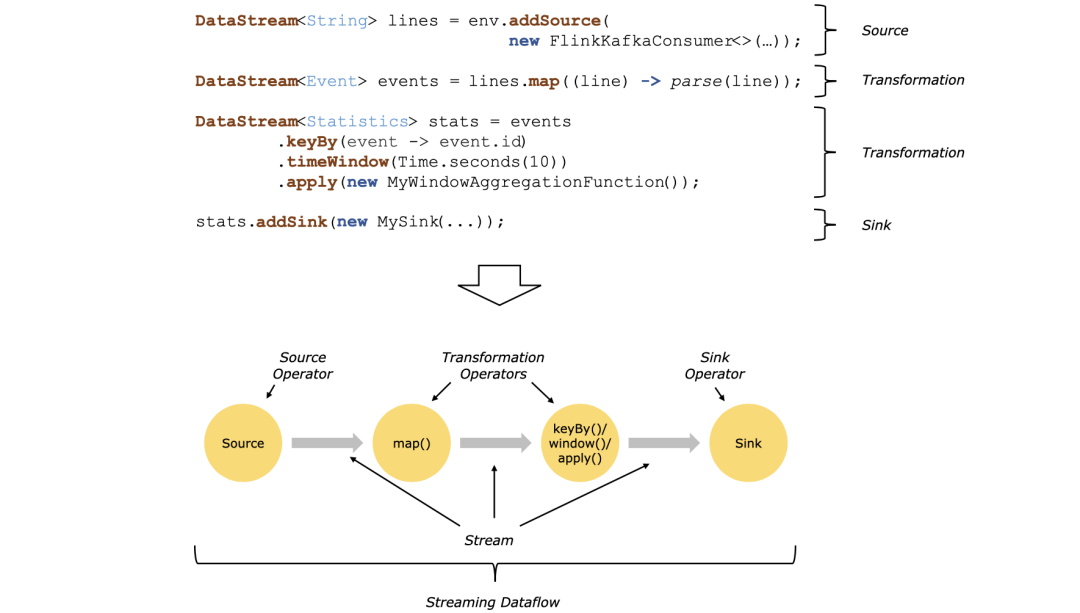
一个Flink应用程序由3部分构成,或者说将Flink的操作算子可以分成3部分,分别为Source、Transformation和Sink。

· Source:数据源部分。负责读取指定存储介质中的数据,转为分布式数据流或数据集,例如readTextFile()、socketTextStream()等算子。Flink在流处理和批处理上的Source主要有4种:基于本地集合、基于文件、基于网络套接字Socket和自定义Source。
· Transformation:数据转换部分。负责对一个或多个数据流或数据集进行各种转换操作,并产生一个或多个输出数据流或数据集,例如map()、flatMap()、keyBy()等算子。
· Sink:数据输出部分。负责将转换后的结果数据发送到HDFS、文本文件、MySQL、Elasticsearch等目的地,例如writeAsText()算子。
Flink应用程序可以消费来自消息队列或分布式日志这类流式数据源(例如Apache Kafka或Kinesis)的实时数据,也可以从各种数据源中消费有界的历史数据。同样,Flink应用程序生成的结果流也可以发送到各种数据存储系统中(例如数据库、对象存储等)。
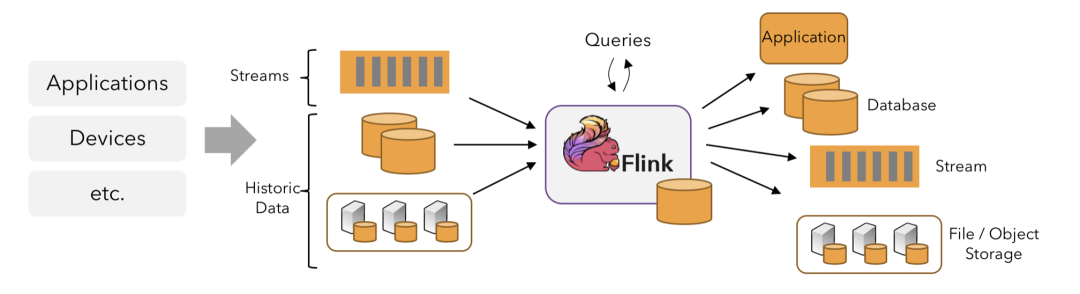
知道Flink的程序结构至关重要,知道了结构后才是深入Flink的第一步。说实话,Flink难也难,你说简单也简单,你看它的程序结构,就是围绕Source、Transformation和Sink这三种类型的算子在玩。
欢 迎 大 家 关 注 我 的 公 众 号 【 老 周 聊 架 构 】 ,AI 、大数据、云原生、物联网等相关领域的技术知识分享。