
送书 | 聊聊逆向爬取数据
最好的挣钱方式是钱生钱,怎样钱生钱呢,钱生钱可以通过投资,例如买股票、基金等方式,有人可能说买股票基金发财,我没这样的命和运气。买股票基金靠的不只有命运和运气,更多靠的是长期的经验和对股票基金数据的分析,今天我们使用scrapy框架来js逆向爬取某证信数据平台的国内指数成分股行情数据。
今日网站
aHR0cDovL3dlYmFwaS5jbmluZm8uY29tLmNu
(网址已加密,需要的话扫一扫文末二维码加微信获取)
网页分析
首先进入某证信数据平台国内指数成分股行情数据并打开开发者模式,经过简单查找发现国内指数成分股行情的数据存放在如下图的URL链接中:
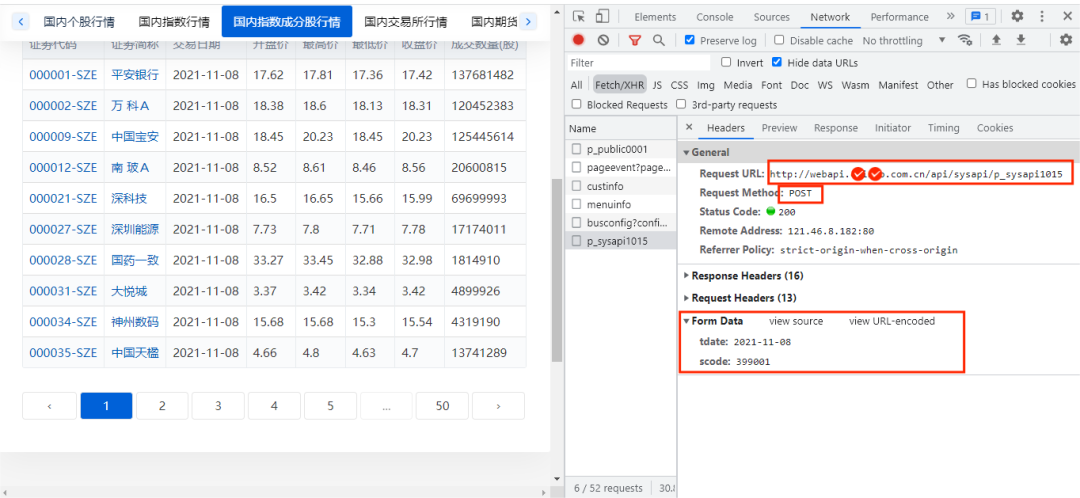
这样一看,很明显,该网络请求是POST请求,URL链接、请求表单没什么加密,那么是不是获取该URL链接的数据就很简单了呢,这里我们简单的编写代码来请求该url链接的数据,具体代码如下所示:
import requests
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'
}
url='xxx.xxx.cn/api/sysapi/p_sysapi1095'
data={
'tdate':'2021-11-2',
'scode':'399001'
}
response=requests.post(url,headers=headers,data=data)
print(response.json())
按照上图的内容信息,我们这样编写爬虫是没有问题的,是可以获取到数据的,但运行这段代码就出了如下问题:
{'resultmsg': '未经授权的访问', 'resultcode': 401}
那么我们在请求头中添加Cookie、Host、referer等参数,运行结果如下所示:
{'resultmsg': '无授权访问,请联系*********', 'resultcode': 401}
又出现了问题,这时,我们要观察一下requests 请求头中有哪些可疑的请求参数没有添加到代码中的headers中,如下图所示:
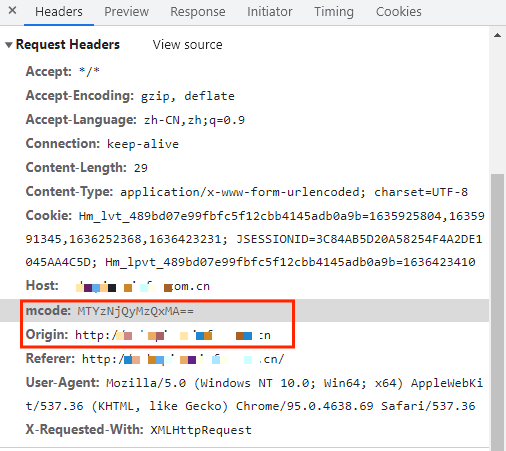
有两个比较可疑的参数,首先我们添加第一个mcode参数到headers中,运行结果如下图所示:

我们发现在headers中添加mcode参数就可以获取到数据,那么问题来了,mcode参数的值没有规律可言,而且每次刷新网页,mcode的值都会发现改变,怎么办好呢,这时我们可以通过js逆向来找出mcode值的生成方式。
js逆向加密
找出加密参数的生成方式大致可以分为四步:
寻找加密参数的方法的位置找出来; 设置断点找加密方法; 把加密方法写入js文件; 调试js文件。
寻找加密参数位置
打开开发者模式,点击右上角三个小点,选择Search,搜索mcode,如下图所示:
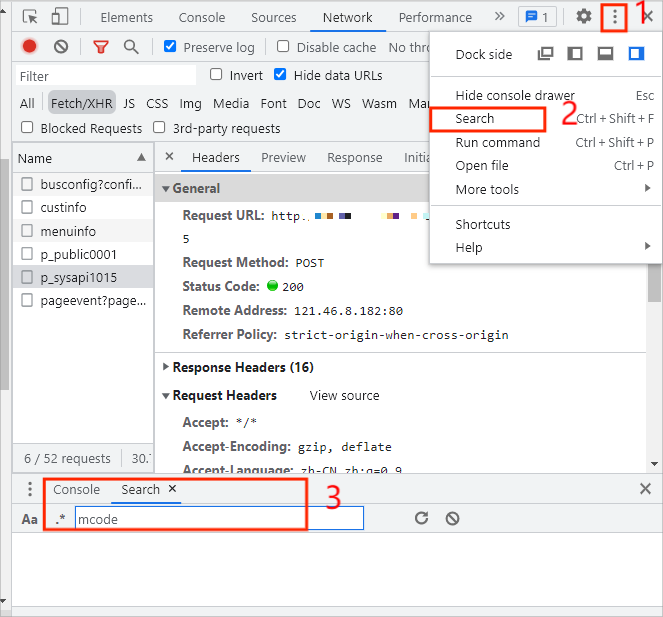
搜索结果如下图所示:

我们发现有三个js有mcode参数内容,那该怎么办呢,这时我们可以精确一点搜索,在mcode后面就英文状态的:,这时就只剩下第一个js了,双击该js文件,如下图所示:

在该js文件中,我们搜索mcode,返回的结果有75个那么多,该怎么办呢,这时我们发现在mcode上面一部分与我们要爬取的url有点关联,那么我们可以在该js文件中搜索url中最后的p_sysapi1015,如下图所示:

这时我们发现搜索结果只有一个了,我们发现mcode是通过indexcode.getResCode()方法生成的,那么该方法有什么作用 呢,我们还不知道,这时就需要通过设置断点来找出加密方法函数。
设置断点
我们在上面的mcode代码行中设置断点并刷新网页,如下图所示:

点击上图中的红框释放,如下图所示:

刚好出现了indexcode和getResCode,很明显var time是和时间有关的,而返回值 window.JSonToCSV.missjson()要调用time,但我们不知道.missjson()方法的作用是什么,这时我们搜索一下missjson,如下图所示:
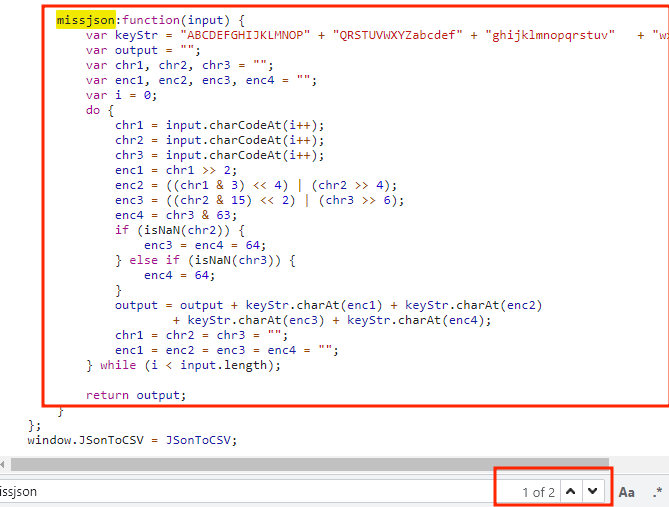
搜索结果有两个,其中一个是刚才调用的missjson()函数,另外一个是missjson函数的具体代码。看不懂这代码的作用是什么,也没关系,我们直接把这missjson()函数全部保存在一个js文件中。
写js文件
加密参数的方法已经知道了,接下来我们将把加密参数missjson()函数写入js文件中,这里我js文件名为mcode.js,如下图所示:
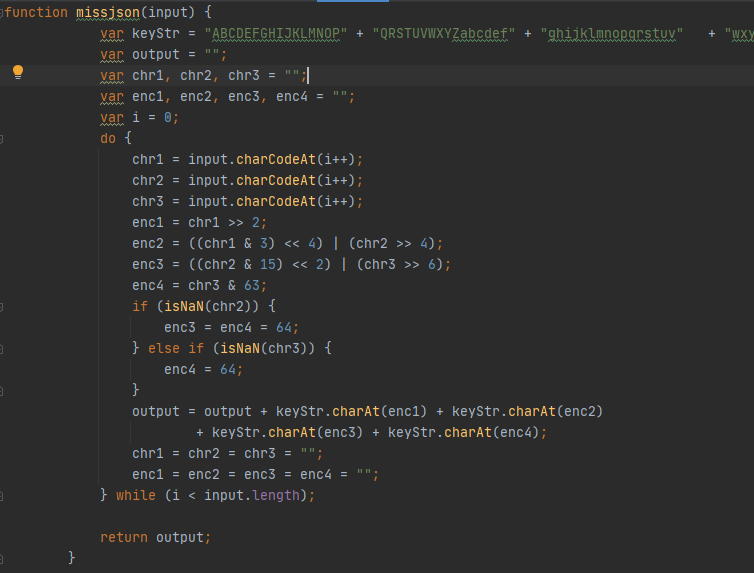
这里需要注意的是:function必须要在missjson前面,这和JavaScript的语法有关。
好了,js文件已经写好了,接下来我们调试一下js文件。
调试js文件
这里我们编写程序来调试js文件,主要代码如下图所示:
import execjs
from os.path import realpath,dirname
import js2py
def get_js():
path = dirname(realpath(__file__)) + '/js/' + 'mcode' + '.js'
with open(path,'r',encoding='utf-8')as f:
read_js=f.read()
return_js=execjs.compile(read_js)
print(return_js)
if __name__ == '__main__':
get_js()
首先导入execjs、js2py这两个调试js文件的库,再自定义方法get_js()来读取js文件,并调用execjs.compile()方法来执行js程序。运行结果如下图所示:

发现没有报错,但没有得到我们想要的参数值,这是因为我们还没有编写time时间的参数进去。主要代码如下图所示:
time1 = js2py.eval_js('Math.floor(new Date().getTime()/1000)')
mcode=return_js.call('missjson','{a}'.format(a=time1))
print(mcode)
return mcode
首先调用js2py.eval_js()方法来处理获取的时间,在通过.call()方法将return_js加密数据和时间结合在一起,最后返回mcode。
运行结果如下图所示:

好了,mcode参数成功获取下来了,接下来将正式编写代码来爬取国内指数成分股行情数据。
实战演练
scrapy框架爬虫
创建scrapy框架爬虫很简单,执行如下代码即可:
scrapy startproject
cd
scrapy genspider <爬虫名字> <允许爬取的域名>
其中,我们的Scrapy项目名为Shares,爬虫名字为:shares,允许爬取的域名为:网站域名(xxx.xxx.cn)。
好了创建Scrapy项目后,接下来我们创建一个名为js的文件夹来存放刚才编写的js文件,并把调试js文件的Read_js.py文件放在Scrapy项目中,项目目录如下图所示:
这样我们的爬虫准备工作就做好了,接下来正式编写代码来获取数据。
itmes.py文件
在获取数据前,我们先在items.py文件中,定义爬取数据的字段,具体代码如下所示:
import scrapy
class SharesItem(scrapy.Item):
# define the fields for your item here like:
Transaction_date=scrapy.Field() #交易日期
Opening_price=scrapy.Field() #开盘价
Number_of_transactions=scrapy.Field()#成交数量
Closing_price=scrapy.Field() #收盘价
minimum_price=scrapy.Field() #最低价
Highest_price=scrapy.Field() #最高价
Securities_code=scrapy.Field() #证券代码
Securities_abbreviation=scrapy.Field() #证券简称
这里我们只定义了网页展示给我们数据的字段,要想获取更多数据,可以根据下图自行定义字段:

发送网络请求
定义好字段后,我们要在spiders爬虫文件中的shares.py文件中编写start_requests()方法来发送网络请求,主要代码如下所示:
def start_requests(self):
data1 = {
'tdate': '2021/10/11',
'scode': '399001'
}
url='xxx.xxx.cn/api/sysapi/p_sysapi1015'
yield scrapy.FormRequest(url,formdata=data1,callback=self.parse)
通过创建的data1字典来构造Form Data表单数据,由于是POST请求,所以我们要使用scrapy.FormRequest()方法来发送网络请求,发送网络请求后,通过回调函数callback来将响应内容返回给parse()方法。
提取数据
在上一步中,我们成功获取到了响应内容,接下来我们继续编写把响应内容解析并提取我们想要的数据,主要代码如下所示:
def parse(self, response):
p=response.json()
if p!=None:
pda=p.get('records')
for i in pda:
item=SharesItem()
item['Transaction_date']=i.get('交易日期')
item['Opening_price']=i.get('开盘价')
item['Number_of_transactions']=i.get('成交数量')
item['Closing_price']=i.get('收盘价')
item['minimum_price']=i.get('最低价')
item['Highest_price']=i.get('最高价')
item['Securities_code']=i.get('证券代码')
item['Securities_abbreviation']=i.get('证券简称')
yield item
我们把响应内容通过json()的格式来获取下来,再通过.get()方法把我们想要的数据提取出来,最后通过yield生成器将数据返回给引擎。
保存数据
在上一步中,我们成功把数据提取出来并返回给引擎了,接下来在piplines.py文件中保存数据在MySQL数据库中,主要代码如下所示:
class mysqlPipeline:
conn = None
cursor = None
def open_spider(self,spider):
print('爬虫开始!!!')
self.conn=pymysql.Connection(host='localhost',user='root',passwd='123456',port=3306,db='commtent1')
def process_item(self,item,spider):
self.cursor=self.conn.cursor()
sql2 = 'insert into data(Transaction_date,Opening_price,Number_of_transactions,Closing_price,minimum_price,Highest_price,Securities_code,Securities_abbreviation) value(%s,%s,%s,%s,%s,%s,%s,%s)'
print(list(item.values()))
self.cursor.execute(sql2,list(item.values()))
self.conn.commit()
def close_spider(self,spider):
print('爬虫结束!!!')
self.cursor.close()
首先我们自定义pysqlPipeline类,然后编写open_spider()方法来连接mysql数据库,再通过process_item()方法来将数据存放在数据库中,然后通过编写close_spider()方法将数据库关闭。
请求头headers
接下来开始编写请求头headers,headers请求头一般是在settings.py文件中编写,首先在settings.py文件中找到DEFAULT_REQUEST_HEADERS代码行并将注释去掉,主要代码如下图所示:
from Shares.Read_js import get_js
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'
mcode=get_js()
DEFAULT_REQUEST_HEADERS = {
'Referer': 'xxx.xxx.xxx.cn/',
'Cookie':'Hm_lvt_489bd07e99fbfc5f12cbb4145adb0a9b=1635913057,1635925804,1635991345,1636252368; JSESSIONID=584FD4CCC7E980CAE09908DC0EF835FF; Hm_lpvt_489bd07e99fbfc5f12cbb4145adb0a9b=1636252373',
'mcode': mcode
}
LOG_LEVEL="WARNING"
ITEM_PIPELINES = {
# 'Shares.pipelines.SharesPipeline': 300,
'Shares.pipelines.mysqlPipeline': 301,
}
首先导入Shares.Read_js中的get_js方法,并通过变量mcode来接收get_js()方法的返回值,最后通过LOG_LEVEL="WARNING"把运行爬虫程序的日志屏蔽,在setting.py文件中找到我们的ITEM_PIPELINES代码行并将其注释去掉,开启我们的项目管道。
执行爬虫
好了,所有代码已经编写完毕了,接下来将执行如下代码即可运行爬虫程序:
scrapy crawl shares
运行结果如下图所示:
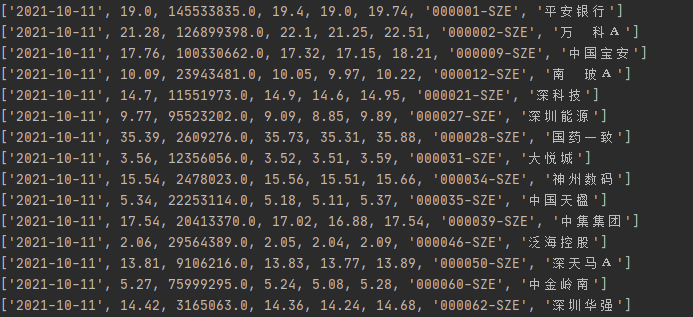
这里我们只获取到了一天的数据,当我们要获取多天的数据怎么办呢?
获取多天数据
获取多天数据很简单,只需要调用pandas.period_range()方法即可,将发送网络请求中的代码修改为如下代码即可:
datatime = pd.period_range('2021/10/11', '2021/10/12', freq='B')
for i in datatime:
data1 = {
'tdate': str(i),
'scode': '399001'
}
url='xxx.xxx.xxx.cn/api/sysapi/p_sysapi1015'
yield scrapy.FormRequest(url,formdata=data1,callback=self.parse)
其中freq='B'表示工作日,运行结果如下图所示:
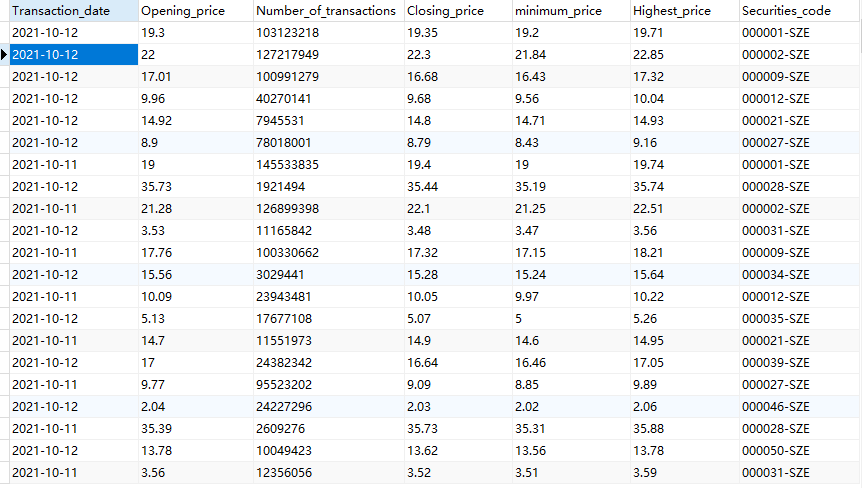
好了,爬取某证信股票行情就讲到这里了,感谢观看!!!
送书
又到了每周三的送书时刻,今天给大家带来的是《每个人的Python 数学、算法和游戏编程训练营》,本书以数字为切入点,介绍用编程来解决数学问题,其中涉及的算法和游戏相关的题目也与数学相关。本书以问题驱动为主线——提出一系列问题,然后介绍如何使用编程这种工具来解决它!通过学习本书你会发现,编程并不是只有专业人士才能干的事,任何人只要有兴趣都可以学会它,重要的是可以用编程来解决问题!
话题:Python;编程;算法。

点击下方回复:送书 即可!
(加我获取本文网址~)