
CNN轻量化模型及其设计原则综述

极市导读
本文对CNN经典模型的结构设计演变做一个总结,旨在让读者了解一些结构的设计原理,产生效果的原因。主要包括轻量化模型以及设计原则两个方面。>>加入极市CV技术交流群,走在计算机视觉的最前沿
轻量化模型
轻量化模型主要围绕减少计算量,减少参数,降低实际运行时间,简化底层实现方式等这几个方面,提出了深度可分离卷积,分组卷积,可调超参数降低空间分辨率和减少通道数,新的激活函数等方法,并针对一些现有的结构的实际运行时间作了分析,提出了一些结构设计原则,并根据这些原则来设计重新设计原结构。
注:除了以上这种直接设计轻量的、小型的网络结构的方式外,还包括使用知识蒸馏,低秩剪枝、模型压缩等方法来获得轻量化模型。
Xception(2017)
Xception是基于Inception_v3上做轻量化的改进而来,可认为是extreme Inception。
创新之处有一:1. 提出深度可分离卷积(Depthwise Separable Convolution)。
Inception_v3的结构图如下左图,去掉平均池化路径后变成右图
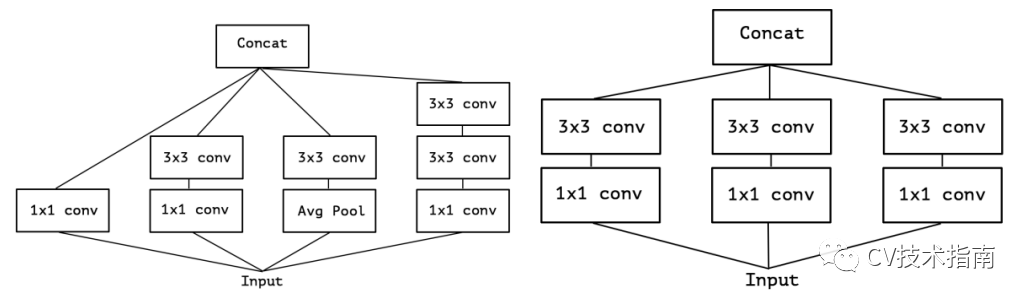
对上右图做一个简化,可变成如下左图的形式。当其极端化时,就变成了如下右图所示结构。

因此,当使用一个3x3卷积对应一个通道时,也就形成了extreme Inception。同时作者认为先进行3x3卷积,再进行1x1卷积不会有什么影响。因此对extreme Inception进行镜像,先进行深度卷积,再进行1x1卷积,形成了深度可分离卷积。
此外,经过实验证明,在使用深度卷积后,不能再使用ReLU这种非线性激活函数,转而使用了线性激活函数,这样收敛速度更快,准确率更高。
MobileNet_v1(2017)
MobileNet v1 提出了一种有效的网络架构和一组两个超参数,这些超参数允许模型构建者根据问题的约束条件为其应用选择合适尺寸的模型,以构建非常小的,低延迟的模型,这些模型可以轻松地与移动和嵌入式视觉应用的设计要求匹配。
创新之处有二:
1. 提出使用深度可分离卷积构建网络,并对计算量做了分析。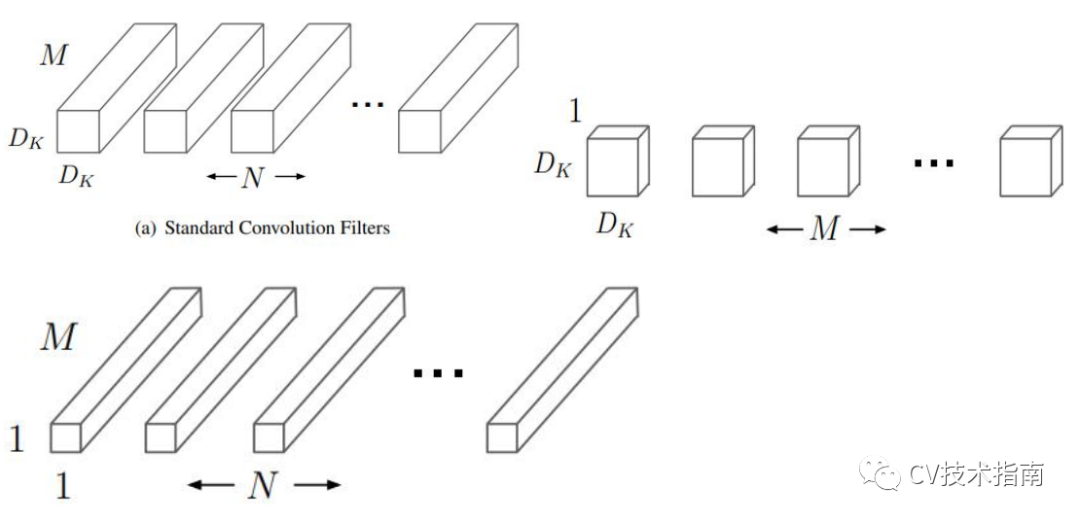
深度可分离卷积是将标准的卷积分解为深度卷积和 1x1 点卷积。深度卷积将单个滤波器应用于每个输入通道,点卷积将深度卷积的输出加权结合,这样的分解效果是大大减少了计算量和模型大小。
例如,给定一个Df x Df x M 的 feature maps 生成Df x Df x N 的 feature maps,假设卷积核大小为Dk。则深度可分离卷积与标准卷积的计算量的比值为:
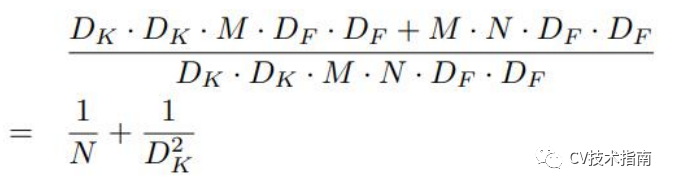 因此,当使用3x3卷积时,这种卷积方式可减少8-9倍计算量,而进度只降低了一点点。
因此,当使用3x3卷积时,这种卷积方式可减少8-9倍计算量,而进度只降低了一点点。
此外,这种深度可分离卷积不只是减少了计算量这么简单。对于无结构的稀疏的矩阵,其计算量虽然比密集矩阵要少,但由于密集矩阵在底层是使用了通用矩阵乘法(general matrix multiply function,即 GEMM)来进行优化(这种优化是在内存中通过 im2col 对卷积进行初始重新排序,再进行矩阵乘法计算),因此密集矩阵计算速度更快。
这里深度可分离卷积中的1x1 卷积不需要进行·im2col 重排序,直接就可以使用矩阵运算,至于深度卷积部分,其参数量和计算量极少,按照正常卷积的优化计算即可。因此深度可分离卷积计算速度同样极快。
2. 提出根据具体环境 使用超参数调整模型大小。
使用超参数alpha调整深度卷积核的个数,即在原模型的深度卷积核个数M和N的基础上乘以缩小因子alpha。使用超参数P降低空间分辨率,在原来输入图尺寸的基础上乘以缩小因子P。注:这种使用超参数的方式只降低了计算量,参数量仍然不变。
MobileNet_v2(2018)
MobileNet_v2 在轻量化结构设计方面没有创新,但提出了一些 MobileNet_v1 存在的一些问题,并在此基础上提出了改进方案。
创新之处有二:
1. 提出线性瓶颈(Linear Bottlenecks)
MobileNet_v2 提出 ReLU 会破坏在低维空间的数据,而高维空间影响比较少。因此,在低维空间使用 Linear activation 代替 ReLU。经过实验表明,在低维空间使用 linear layer 是相当有用的,因为它能避免非线性破坏太多信息。
此外,如果输出是流形的非零空间,则使用 ReLU 相当于是做了线性变换,将无法实现空间映射,因此 MobileNet_v2 使用 ReLU6 实现非零空间的非线性激活。
因此,其结构如下图所示:
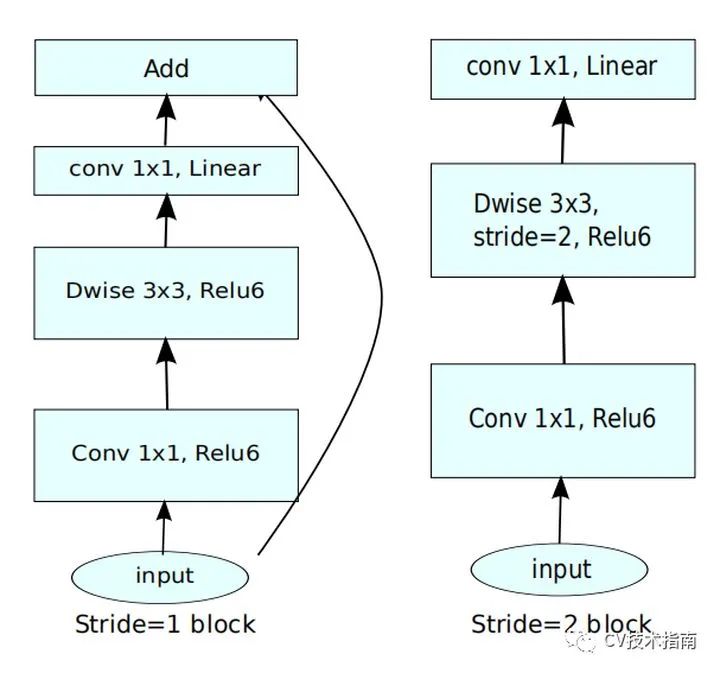
2. 提出倒残差(Inverted Residuals)
MobileNet_v2引入了残差连接和残差块,但不同的是,ResNet中的bottleneck residual是沙漏形的,即在经过1x1卷积层时降维,而MobileNet_v2中是纺锤形的,在1x1卷积层是升维。这是因为MobileNet使用了Depth wise,参数量已经极少,如果使用降维,泛化能力将不足。
ResNet中residual block是两端大,中间小。而MobileNet_v2中是中间大,两端小,刚好相反,作者把它取名为Inverted residual block。
其结构如下:
如上第一个图所示,在MobileNet_v2中没有使用池化来降维,而是使用了步长为2的卷积来实现降维,步长为2的block没有使用shortcut connection。
MobileNet_v3(2019)
MobileNet_v3使用了NAS神经架构搜索技术来构建网络,并提出了一些改进方案。本系列总结的侧重点是结构设计的演变,因此,这里只提结构创新之处。
创新之处有三:
1. 对于时延比较高的层进行重新设计。
在MobileNet_v2的Inverted bottleneck结构中使用1x1卷积作为最后一层,用于扩大到一个更高维的特征空间,这一层对于提供丰富的特征用于预测极为重要,但也增加了延时。
为了降低延时,并保持高维空间特征,MobileNet_v3中把这一层移到了平均池化层的后面,在最后的特征集现在只需要计算1x1的分辨率,而不是原来的7x7。这种设计选择的结果是,在计算和延迟方面,特性的计算变得几乎是免费的。
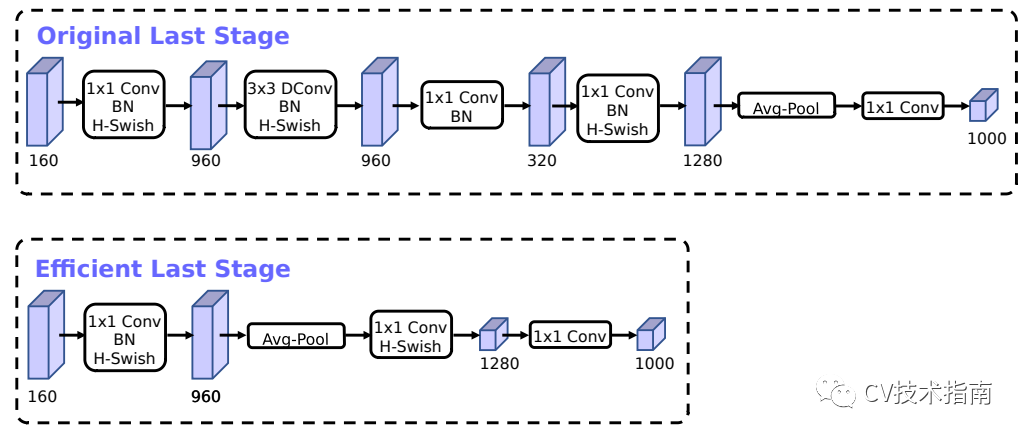
一旦降低了该特性生成层的成本,就不再需要以前的瓶颈投影层来减少计算量。该观察允许删除前一个瓶颈层中的投影和过滤层,从而进一步降低计算复杂度。原始阶段和优化后的阶段如上图所示。
另一个耗时的层是第一层卷积,当前的移动模型倾向于在一个完整的3x3卷积中使用32个滤波器来构建初始滤波器库进行边缘检测。通常这些过滤器是彼此的镜像。
mobileNet_v3对这一层使h-swish非线性激活函数,其好处是使用了h-swish后滤波器的数量可以减少到16,而同时能够保持与使用ReLU或swish的32个滤波器相同的精度。这节省了额外的3毫秒和1000万 MAdds。
2. 提出使用h-swish激活函数
在一篇语义分割的论文中提出了使用swish的非线性函数来代替ReLU函数,它可以显著提高神经网络的精度,其定义为:swish x = x · σ(x),这里σ(x)是sigmoid函数。
然而swish虽然提高了精度,但sigmoid函数计算是极为昂贵的,在嵌入式移动端不适合它的存在,因此,MobileNet_V3提出了计算更为简便的h-swish函数,其定义如下: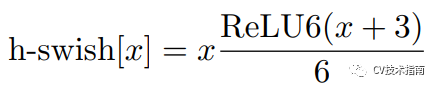
注:在较深的层次中使用更能发挥swish的大多数好处,因此在MobileNet_v3结构中,除了上面提到的第一层用h-swish以外,中高层才使用h-swish, 其它层仍然用ReLU。
3. 提出Large squeeze-and-excite
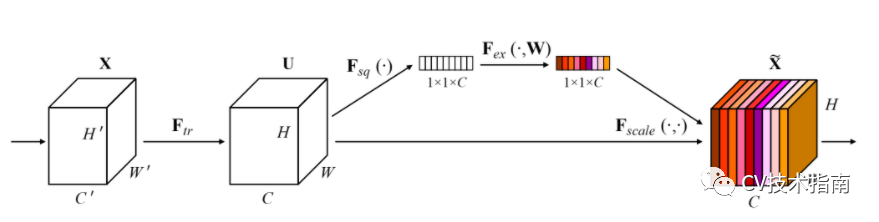 MobileNet_v3引入了在SENet中提出的SE模块,并作了一定的调整。一个是将sigmoid换成了h-swish。第二个是将第二Linear的通道数变为下一层的1/4。但这样就没办法逐像素相乘了,因为通道数不匹配,然后我去找了MobileNet_v3的代码,发现它在通道数变为1/4后又使用expand_as将其扩展成了下一层的通道数。
MobileNet_v3引入了在SENet中提出的SE模块,并作了一定的调整。一个是将sigmoid换成了h-swish。第二个是将第二Linear的通道数变为下一层的1/4。但这样就没办法逐像素相乘了,因为通道数不匹配,然后我去找了MobileNet_v3的代码,发现它在通道数变为1/4后又使用expand_as将其扩展成了下一层的通道数。
ShuffleNet_v1(2018)
创新之处有二:
1. 提出用于分组卷积的通道混洗。
如下图所示,左边是传统卷积,右边是分组卷积,在上一篇《CNN结构演变(一)经典模型》中提到,分组卷积的最初创意来源于AlexNet使用了两个GPU。这样的分组会出现一个问题,如果分组太多,将导致输出层的每层通道都直接从上一层某一个或几个通道卷积而来,这将会阻止通道组之间的信息流动并削弱模型的表示能力。
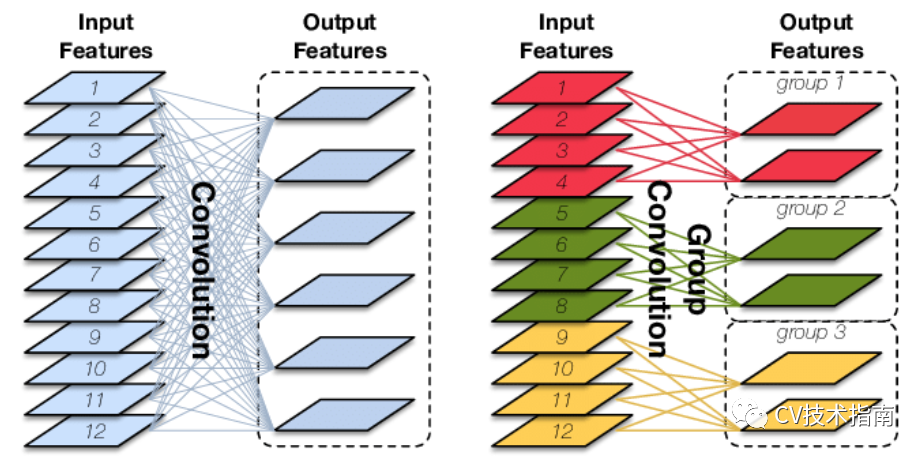
解决的办法就是让不同组进行连接,让不同通道组的信息充分流动。
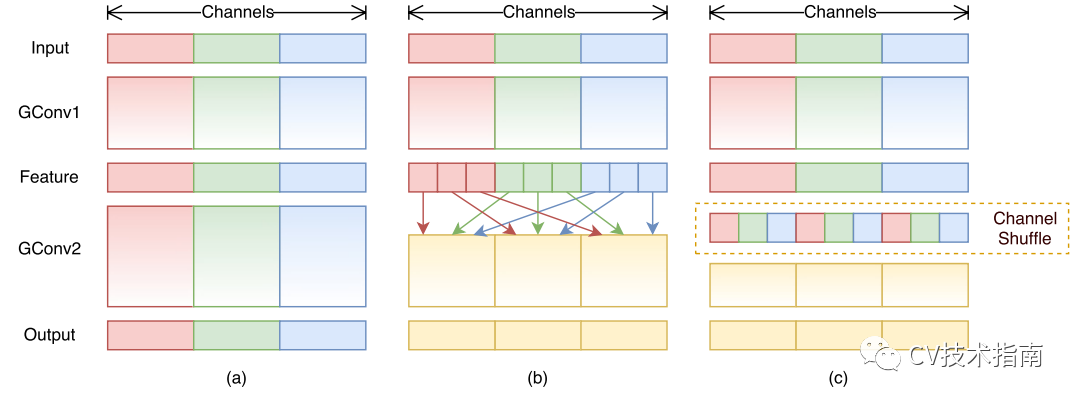
而shuffleNet中提出更好的办法就是直接将组的顺序打乱(如上图右所示),再进行按组连接。注:这样打乱顺序后仍然是可微的,因此这种结构可嵌入网络模型进行端到端训练。
2. 在使用深度卷积的残差块(图a)的基础上,调整并提出ShuffleNet Unit(图b和c)。

图b为正常Unit, 图c为降采样Unit。
shuffleNet Unit将1x1 卷积替代为1x1分组卷积,并在shortcut path上添加了3x3平均池化,并将逐元素相加代替为通道拼接,这样可以扩大通道数尺寸而不用增加计算成本。
此外,shuffleNet Unit取消了深度卷积后的ReLU, 最早是Xception中提出只能使用线性变换,而MobileNet_v2中解释了在深度卷积后使用ReLU会丢失较多的信息。因此,最终的ShuffleNet Unit如图b和c所示。
ShuffleNet_v2(2018)
在前面介绍的几篇轻量化模型中提出了分组卷积,深度可分离卷积等操作用来降低FLOPs,但FLOPs并不是一个直接衡量模型速度或者大小的指标,它只是通过理论上的计算量来衡量模型,然而在实际设备上,由于各种各样的优化计算操作,导致计算量并不能准确地衡量模型的速度。
主要原因一个是FLOPs忽略了一些重要的因素,一个是MAC (memory access cost),即内存访问的时间成本。例如分组卷积,其使得底层使用的一些优化实现算法由于分组后实现性能更低,从而导致,分组数越大,时间成本越高。另一个是并行度,同样FLOPs下,高并行度的模型速度快于低并行度的模型。
第二个是不同平台下,同样的FLOPs的模型运行时间不同。例如在最新的CUDNN library中,优化实现的3x3卷积所花费的时间并没有1x1卷积的9倍。因此,ShuffleNet_v2提出根据实际运行时间来衡量模型速度或大小。
创新之处有二:
1. 在ShuffleNet v2进行了四项实验,得出了一些比较耗时的操作,经过原理分析,提出了四条设计原则。
1) 卷积层输入输出通道数相同时,MAC最小
2) 分组卷积的分组数越大,MAC越大
3) 网络支路会降低模型的并行度
4) Element-wise操作不可忽视
注:该论文十分值得一看,可在CV技术指南的模型总结部分看到该论文的完整解读,这里不对这四条设计原则详细介绍原理和细节。
2. 根据上面四条设计原则,对ShuffleNet_V1 Unit中不合理的部分进行调整,提出了新的Unit。
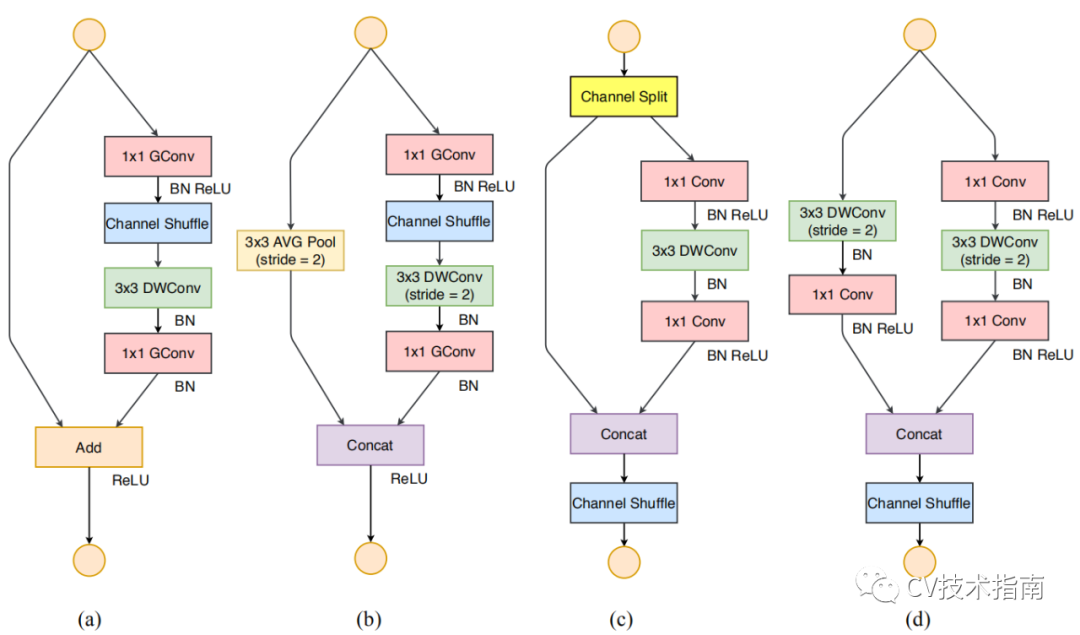 图a为shuffleNet v1正常Unit, 图b为shuffleNet v1降采样Unit,图c为shuffleNet v2 正常Unit, 图d为shuffleNet v2 降采样Unit.
图a为shuffleNet v1正常Unit, 图b为shuffleNet v1降采样Unit,图c为shuffleNet v2 正常Unit, 图d为shuffleNet v2 降采样Unit.
在shuffleNet v2中引入了Channel Split, 将通道数分为c’ 和c - c’,这里c’取c/2。一部分进行卷积操作,另一部分直接进行concat。卷积的那一路的输入和输出相等,这是考虑到第一条原则。
两个1x1卷积不再进行分组,一部分原因是第二条原则,另一部分是因为Channel split就相当于是分组了。两路进行concat后,再进行Channel Shuffle,这是为了通道上的信息进行流动。否则,左端那路的一半通道信息将一直进行到后面都没有通过卷积层。
对于空间降采样层,这个Unit是没有Channel split,这样可以实现在两路concat后,通道数翻倍。其余改动具体看图更容易理解。
注:此处提出的Channel Split似乎是下面会提到的CSPNet中Cross Stage Partial Networks的灵感来源,且Channel Split在CSPNet中会发挥另外一种作用。这种Channel Split在每个block中,一半的通道直接进入下一个block参与下一个block,这可以认为是特征复用(feature reuse)。
SqueezeNet(2017)
SqueezeNet基于以下三点设计理念提出了一种新的模块:
(1)大量使用1x1卷积核替换3x3卷积核,因为参数可以降低9倍;
(2)减少3x3卷积核的输入通道数(input channels),因为卷积核参数为:(numberof input channels) * (number of filters) * 3 * 3.
(3)下采样尽量放在网络后面,前面的layers可以有更大的特征图,有利于提升模型准确度。
创新之处有一:
1. 提出Fire模块。
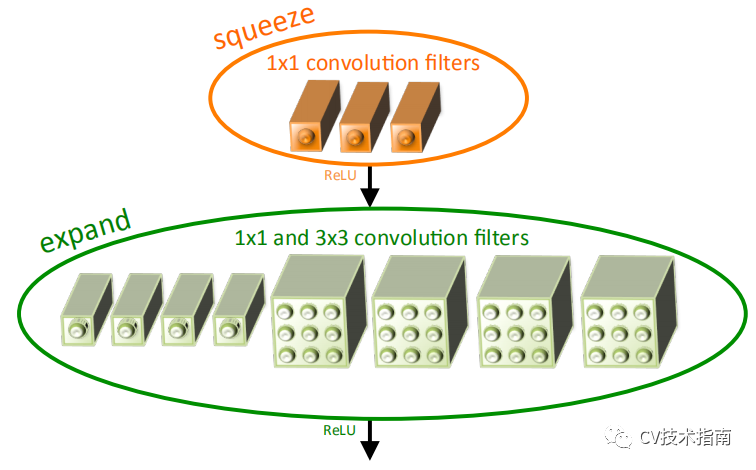 Fire模块由Squeeze layer 和Expand layer组成。
Fire模块由Squeeze layer 和Expand layer组成。
在Squeeze layer,使用1x1卷积,减少通道数;在Expand layer,使用1x1卷积和3x3卷积,1x1卷积和3x3卷积的输出进行concate。
PELEE(2019)
PeleeNet是一种基于DenseNet改进而来的轻量化网络,主要面向移动端部署的目标检测。
创新之处有三:
1. 提出Stem block。
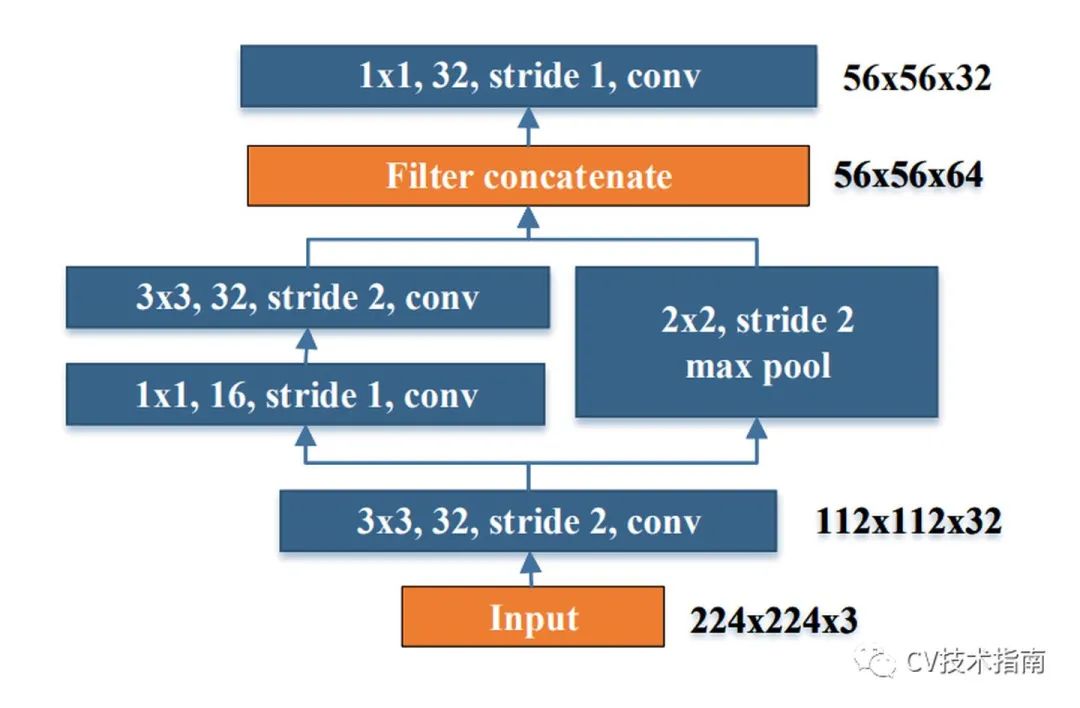
stem block可以在几乎不增加计算量的情况下,提升特征的表达能力。
2. 提出两路Dense Layer。
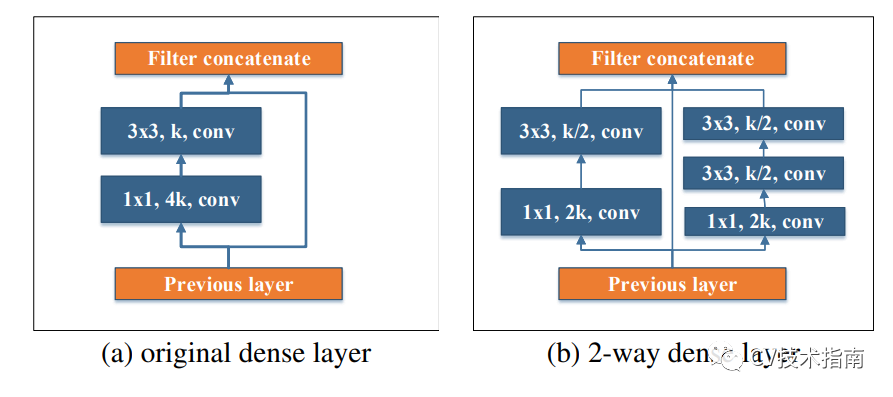 受Inception的启发,使用了两路dense layer, 这两路的感受野不一样,左边是3x3 ,右边是两个3x3堆叠,感受野有5x5。
受Inception的启发,使用了两路dense layer, 这两路的感受野不一样,左边是3x3 ,右边是两个3x3堆叠,感受野有5x5。
注:PELEE还包括一些其它创新点,但跟轻量化没什么关系,就不提了。感兴趣的读者可看原论文。在ImageNet数据集上,PeleeNet只有MobileNet模型的66%,并且比MobileNet精度更高。
CSPNet(2020)
准确来说,这篇论文并不是要提出一个轻量化模型,而是要提出一种增强CNN学习能力的backbone。之所以在这里提这篇论文,是因为CSPNet提出了一种思想,使得网络在保持准确率的情况下,大概降低计算量20%左右。
CSPNet可与现有的一些模型(DenseNet, ResNet, ResNeXt)进行结合,YOLO_v4就是使用CSPDarknet53 作为backbone。
创新之处有一:
1. 提出Cross Stage Partial Network (CSPNet)。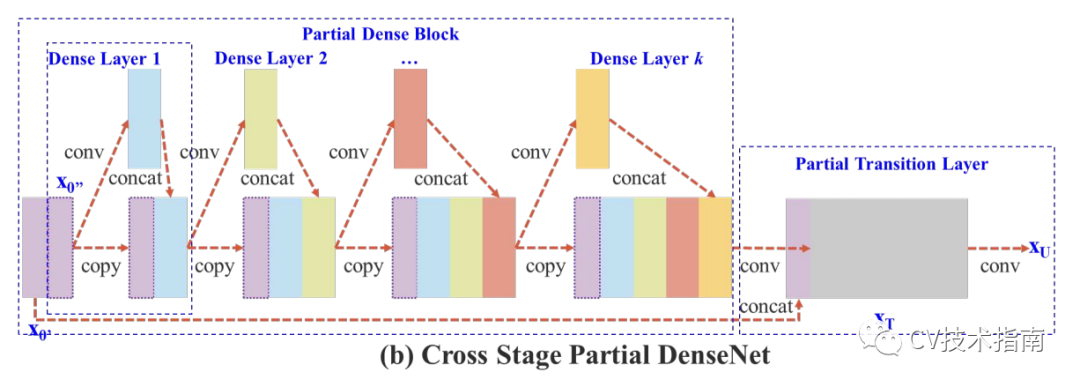
根据DenseNet中提出的基于增加信息流动的方法,提出将一个stage前的feature maps在通道上分成两部分,一部分经过该stage的一系列卷积,激活等操作,另一部分直接在该stage末尾与前一部分concate,并进行transition。实验证明通过concate和transition的梯度信息可以具有较大的差异性。
该方法有以下优点:1.增强CNN的学习能力,2.去除计算量瓶颈,3.降低内存成本(20%左右)。
注:该论文还有其它创新点,这里只提跟轻量化有关的。
设计原则
接下来将介绍两种提升模型的表示能力的结构或方式,模型的五条设计原则,轻量化模型的四个设计方式。
提升模型的表示能力的结构或方式
1.“split-transform-merge”结构
这个概念来源于ResNeXt(2017年),在文中作了如下解释。1) Split:将向量x分成低维嵌入表示;2) Transform:每个低维特征经过一个线性变换;3) Merge:通过单位加合成最后的输出;
Inception系列就是采用了这种策略的一个结构,在Inception模块中,Split采用的是1x1降维的方式,Transform采用卷积,Merge采用Concate的方式。通过 ”split-transform-merge”这种策略,使得模型可以以较少的参数和计算量,实现更深更大模型才具备的特征表示能力。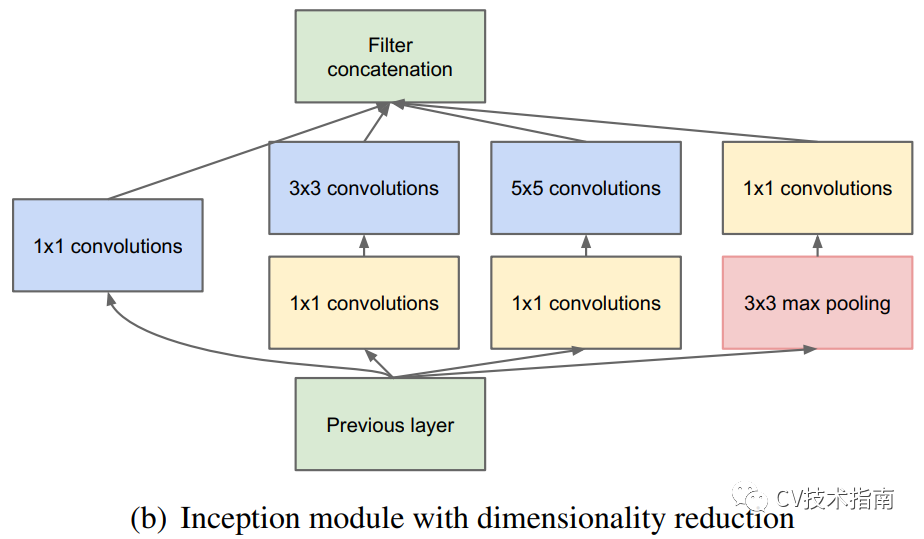
在ResNeXt中提到,基数(cardinality,也就是分支数)增多是一种比加深加宽网络更有效的方式提升精度。基于这一点,在PELEE网络中,就将DenseNet中的结构从单路变成双路的方式来改进模型。
2. 特征复用(feature reuse)
传统的卷积网络在一个前向过程中每层只有一个连接,ResNet增加了残差连接从而增加了信息从一层到下一层的流动。FractalNets重复组合几个有不同卷积块数量的并行层序列,增加名义上的深度,却保持着网络前向传播短的路径。相类似的操作还有Stochastic depth和Highway Networks,DenseNet等。
这些模型都显示一个共有的特征,缩短前面层与后面层的路径,其主要的目的都是为了增加不同层之间的信息流动,使用的方式就是特征复用。
特征复用的实现方式有以下几种:残差连接;feature maps留下一半进入下一层;feature maps通过不同的卷积核数量的并行层序列。
残差连接:采用直接相加的方式。

feature maps留下一半进入下一层:CSPNet。

feature maps通过不同的卷积核数量的并行层序列:FractalNets。
模型的设计原则
在Inception系列的第三篇论文里总结了四条CNN设计的四条原则。
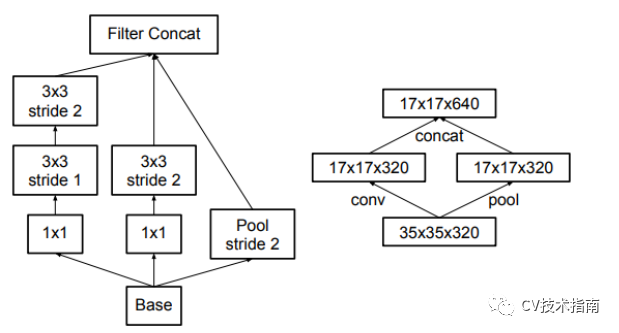
1. 避免表示瓶颈,特别是在网络的浅层。
一个前向网络每层表示的尺寸应该是从输入到输出逐渐变小的。以下图为例,按照左边第一种的方式进行下采样,将会出现表示瓶颈。为了避免这个问题,提出了第四个图所示的结构来进行降采样。
2. 高维度的表示很容易在网络中处理,增加激活函数的次数会更容易解析特征,也会使网络训练的更快。
3. 可以在较低维的嵌入上进行空间聚合,而不会损失很多表示能力。
例如,在执行更分散(例如3×3)的卷积之前,可以在空间聚集之前(浅层)减小输入表示的尺寸,而不会出现严重的不利影响。
我们假设这样做的原因是,如果在空间聚合环境中(中高层)使用输出,则相邻单元之间的强相关性会导致在尺寸缩减期间信息损失少得多。鉴于这些信号应易于压缩,因此减小尺寸甚至可以促进更快的学习。
4. 平衡网络的宽度和深度。
通过平衡每个阶段的滤波器数量和网络深度,可以达到网络的最佳性能。增加网络的宽度和深度可以有助于提高网络质量。但是,如果并行增加两者,则可以达到恒定计算量的最佳改进。因此,应在网络的深度和宽度之间以平衡的方式分配计算预算。
5. 此外再补充一条关于池化的使用。
在网络的特征提取部分,使用最大池化。在分类部分,使用平均池化。具体原因与细节,请阅读CV技术指南中的《池化技术总结》。
轻量化模型设计原则
1. 改进底层实现方式。
如sigmoid函数在实现过程中采用近似的方式,不仅很复杂,还会导致精度损失,因此MobileNet_v3中提出了h-swish非线性激活函数,这个函数的特点就是底层实现很简单,也不会导致推理阶段的精度损失。
2. 减少参数量。
基于这一原则的方式目前有
1)使用深度可分离卷积;
2)使用分解卷积;
3)使用分组卷积;
4)使用特征表示能力强的结构;
5)使用1x1卷积代替3x3卷积;
3. 减少计算量。第二条中的五种方式都具有减少计算量的作用,此外,特征复用也具备减少计算量的作用。
4. 降低实际运行时间。下面提到ShuffleNet_v2中的四条原则就是基于这一点。
在ShuffleNet的第二篇论文里总结了四条实现降低模型实际运行时间的原则。
MAC: memory access cost
1. 卷积层输入输出通道数相同时,MAC最小。
为简化计算表达式,这里使用1x1卷积来进行理论上的推导。
对于空间大小为 h,w的特征图,输入和输出通道数分别为c1和c2,使用1x1卷积, 则FLOPs为B = h x w x c1 x c2。而MAC = hw(c1 + c2 ) + c1 x c2。
这里hwc1为输入特征图内存访问成本,hwc2为输出特征图内存访问时间成本,c1xc2x1x1为卷积核内存访问时间成本。
将B表达式代入MAC表达式中,并根据不等式定理,可有如下不等式: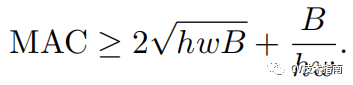
由此式可知,MAC存在下限,当c1 = c2时,MAC取最小值。
这种方式主要指模块的输入输出通道数相同,并非单纯是一层卷积层的输入输出。
2. 分组卷积的分组数越大,MAC越大。
分组卷积在一方面,使得在相同FLOPs下,分组数越大,在通道上的密集卷积就会越稀疏,模型精度也会增加,在另一方面,更多的分组数导致MAC增加。
使用分组卷积的FLOPs表达式为B=h w c1 c2 /g , MAC表达式如下:
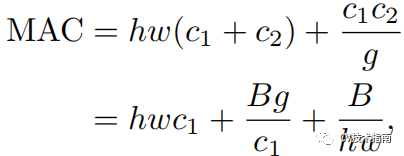
3. 网络支路会降低模型的并行度。
前面提到当网络支路数量增加时,会提高模型的特征表示能力,但同时也降低了效率,这是因为支路对GPU并行运算来说是不友好的,此外,它还引入了额外的开销,如内核启动与同步。
4. Element-wise操作不可忽视。
Element-wise操作在GPU上占的时间是相当多的。Element-wise操作有ReLU, AddTensor, AddBias等。它们都有比较小的FLOPs,却有比较大的MAC。特别地,depthwise conv也可以认为是一个Element-wise操作,因为它有较大的MAC/FLOPs比值。
参考论文:
推荐阅读
2021-02-25

2021-02-23

2021-02-17


# CV技术社群邀请函 #
备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
