
轻量化CNN网络MobileNet系列详解
深度学习100问
Author:louwill
Machine Learning Lab
MobileNet系列作为轻量级网络的代表,使得CNN轻量化和移动端的部署成为可能。MobileNet系列目前总共有三个版本, 分别是MobileNet v1、MobileNet v2和MobileNet v3。作为学习轻量化网络的必经之路,本文重点对MobileNet系列网络进行阐述。
MobileNet v1
MobileNet v1论文为MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications,2017年由谷歌提出,主要专注于CNN的移动端使用和部署。

简单来说,MobileNet v1就是将常规卷积替换为深度可分离卷积的VGG网络。下图分别是VGG和MobileNet v1 一个卷积块所包含的网络层。
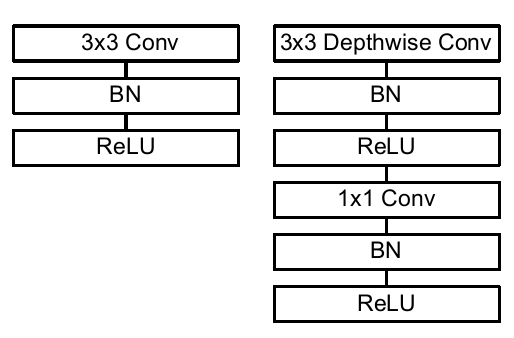
可以看到,VGG的卷积块就是一个常规3*3卷积和一个BN、一个ReLU激活层。MobileNet v1则是一个3*3深度可分离卷积和一个1*1卷积,后面分别跟着一个BN和ReLU层。MobileNet v1的ReLU指的是ReLU6,区别于ReLU的是对激活输出做了一个clip,使得最大最输出值不超过6,这么做的目的是为了防止过大的激活输出值带来较大的精度损失。
那么,什么是深度可分离卷积呢?
从维度的角度看,卷积核可以看成是一个空间维(宽和高)和通道维的组合,而卷积操作则可以视为空间相关性和通道相关性的联合映射。从inception的1*1卷积来看,卷积中的空间相关性和通道相关性是可以解耦的,将它们分开进行映射,可能会达到更好的效果。
深度可分离卷积是在1*1卷积基础上的一种创新。主要包括两个部分:深度卷积和1*1卷积。深度卷积的目的在于对输入的每一个通道都单独使用一个卷积核对其进行卷积,也就是通道分离后再组合。1*1卷积的目的则在于加强深度。下面以一个例子来看一下深度可分离卷积。
假设我们用128个3*3*3的滤波器对一个7*7*3的输入进行卷积,可得到5*5*128的输出。如下图所示:
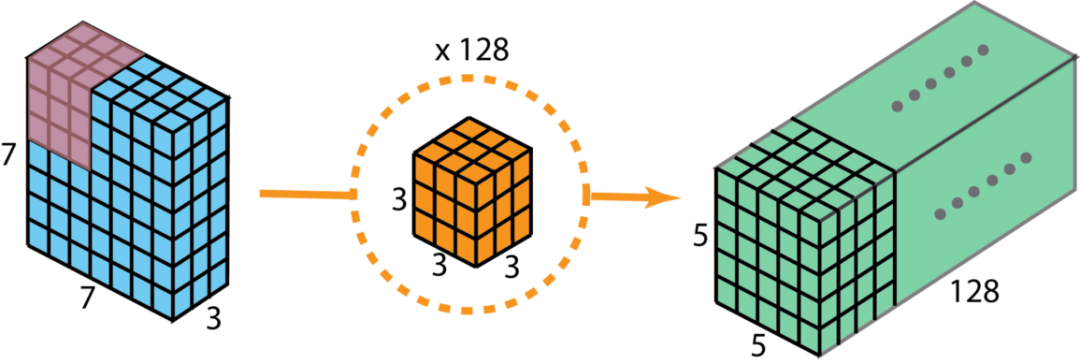
其计算量为5*5*128*3*3*3=86400。
现在看如何使用深度可分离卷积来实现同样的结果。深度可分离卷积的第一步是深度卷积(Depth-Wise)。这里的深度卷积,就是分别用3个3*3*1的滤波器对输入的3个通道分别做卷积,也就是说要做3次卷积,每次卷积都有一个5*5*1的输出,组合在一起便是5*5*3的输出。
现在为了拓展深度达到128,我们需要执行深度可分离卷积的第二步:1x1卷积(Point-Wise)。现在我们用128个1*1*3的滤波器对5*5*3进行卷积,就可以得到5*5*128的输出。完整过程如下图所示:
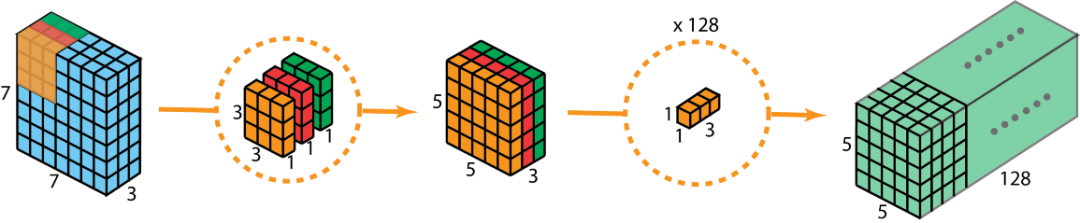
那么我们来看一下深度可分离卷积的计算量如何。第一步深度卷积的计算量:5*5*1*3*3*1*3=675。第二步1x1卷积的计算量:5*5*128*1*1*3=9600,合计计算量为10275次。可见,相同的卷积计算输出,深度可分离卷积要比常规卷积节省12倍的计算成本。所以深度可分离卷积是MobileNet v1能够轻量化的关键原因。
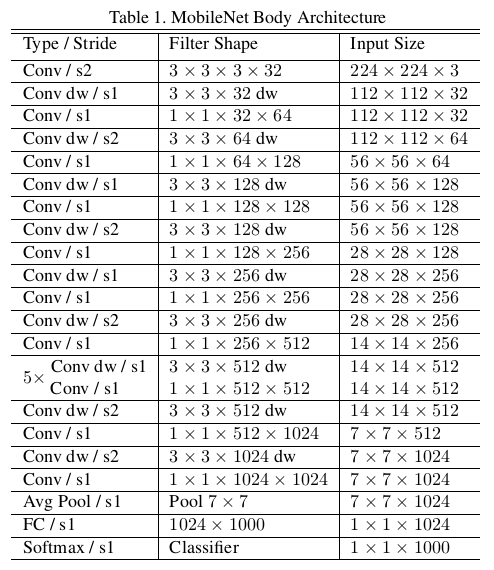
MobileNet v1完整网络结构如下图所示。
MobileNet v1与GoogleNet和VGG 16在ImageNet上的效果对比,如下表所示:

可以看到,MobileNet v1相比与VGG 16精度损失不超过一个点的情况下,参数量小了32倍之多!MobileNet v1在速度和大小上的优势是显而易见的。
MobileNet v2
MobileNet v2是在v1基础上的改进与优化版本。MobileNet v2论文题目为MobileNetV2: Inverted Residuals and Linear Bottlenecks,由谷歌发表于2018年CVPR上。

MobileNet v1的特色就是深度可分离卷积,但研究人员发现深度可分离卷积中有大量卷积核为0,即有很多卷积核没有参与实际计算。是什么原因造成的呢?v2的作者发现是ReLU激活函数的问题,认为ReLU这个激活函数,在低维空间运算中会损失很多信息,而在高维空间中会保留较多有用信息。
既然如此,v2的解决方案也很简单,就是直接将ReLU6激活换成线性激活函数,当然也不是全都换,只是将最后一层的ReLU换成线性函数。具体到v2网络中就是将最后的Point-Wise卷积的ReLU6都换成线性函数。v2给这个操作命名为linear bottleneck,这也是v2网络的第一个关键点。
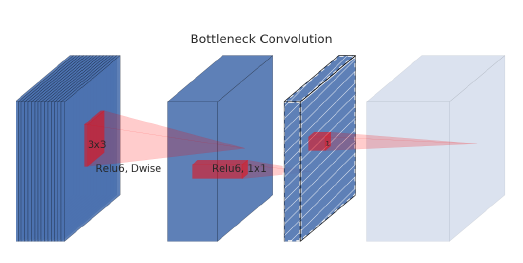
深度卷积(Depth-Wise)本身没有改变通道的作用,比如本文前例中的深度可分离卷积的例子,在前一半的深度卷积操作中,输入是3个通道,输出还是3个通道。所以为了能让深度卷积能在高维上工作,v2提出在深度卷积之前加一个扩充通道的卷积操作,什么操作能给通道升维呢?当然是1*1卷积了。

这种在深度卷积之前扩充通道的操作在v2中被称作Expansion layer。这也是v2网络的第二个关键点。
MobileNet v1虽然加了深度可分离卷积,但网络主体仍然是VGG的直筒型结构。所以v2网络的第三个大的关键点就是借鉴了ResNet的残差结构,在v1网络结构基础上加入了跳跃连接。相较于ResNet的残差块结构,v2给这种结构命名为Inverted resdiual block,即倒残差块。与ResNet相比,我们来仔细看一下“倒”在哪。
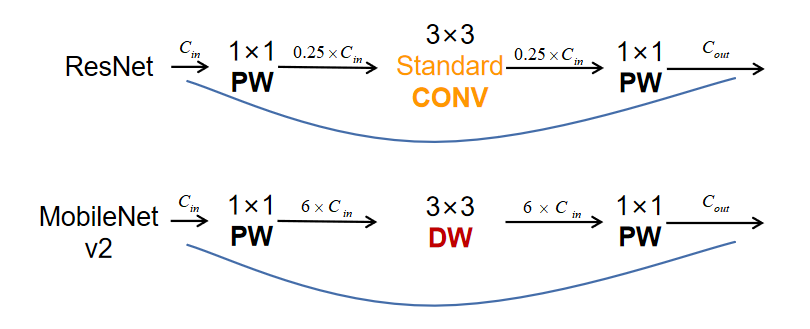
从图中可以看到,ResNet是先0.25倍降维,然后标准3*3卷积,再升维,而MobileNet v2则是先6倍升维,然后深度可分离卷积,最后再降维。更形象一点我们可以这么画:
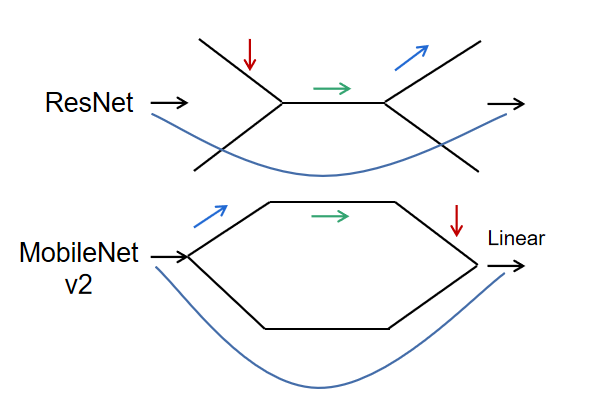
MobileNet v2的维度升降顺序跟ResNet完全相反,所以才叫倒残差。
综合上述三个关键点:Linear Bottlenecks、Expansion layer和Inverted resdiual之后就组成了MobileNet v2的block,如下图所示。

MobileNet v2的网络结构如下图所示。
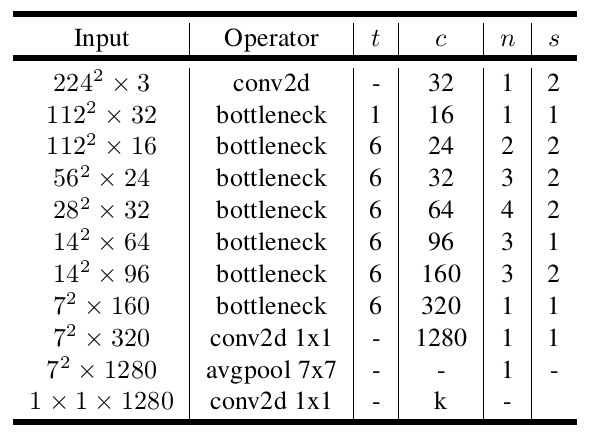
可以看到,输入经过一个常规卷积之后,v2网络紧接着加了7个bottleneck block层,然后再两个1*1卷积和一个7*7的平均池化的组合操作。
MobileNet v3
MobileNet v3同样是由谷歌于于2019年提出新版本的MobileNet。在v2网络的基础上,v3提出了四个大的改进措施。
使用NAS神经架构搜索确定网络结构
在v2的block基础上引入Squeeze and Excitation结构
使用h-swish激活函数
对v2网络尾部结构进行改进
v3论文为Searching for MobileNetV3,将神经架构搜索引入的意思已经很明显了。

关于NAS这里笔者不太了解,也没法展开细说,感兴趣的朋友可以直接查阅NAS相关论文。第二个改进措施就是在v2基础上引入squeeze and excitation结构,熟悉SENet的读者应该知道,这是一个对通道之间相互依赖关系进行建模的操作。
Squeeze and Excitation包括Squeeze(压缩)和Excitation(激活)两个部分。其中Squeeze通过在特征图上执行Global Average Pooling得到当前特征图的全局压缩特征向量,Excitation通过两层全连接得到特征图中每个通道的权值,并将加权后的特征图作为下一层网络的输入。所以可以看到SE block只跟当前的一组特征图存在依赖关系,因此可以非常容易的嵌入到几乎现在所有的卷积网络中。所以MobileNet v3就自然拿来使用了。
在v2基础上,v3网络的block如下图所示。
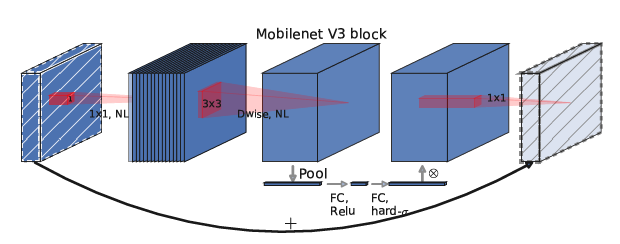
第三个改进点是使用了h-swish激活函数。h-swish激活函数是基于swish的改进,swish激活函数表达式如下:
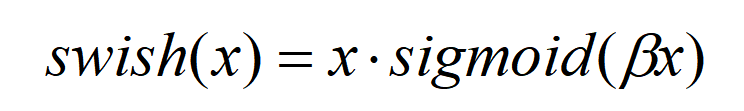
swish激活函数图像在β取0.1、1.0和10.0时如下图所示:

swish激活函数在一系列深度卷积网络上都对效果有显著提升,MobileNet也不例外,但是v3认为,作为一个轻量化的网络,swish激活虽然能带来精度提升,但在移动设备上会有速度损失。所以在swish函数的基础上,v3对其进行了改进,提出了h-swish激活函数。
h-swish的基本想法是用一个近似函数来逼近swish函数,让swish函数变得不那么光滑(hard),基于MobileNet v1和v2的经验,v3还是选择了ReLU6。变换逻辑如下图所示。
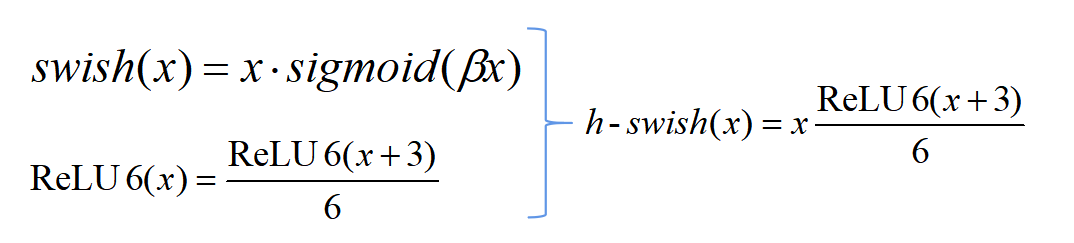
swish和h-swish函数对比图像:
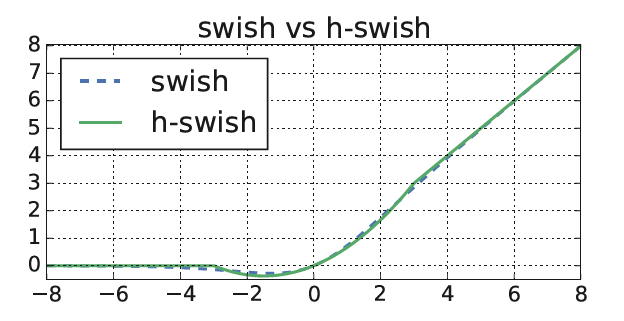
可以将h-swish视为swish的低精度化模式,相较于swish,h-swish能够保持相同精度的条件下减少时间和计算量的开销。对v2网络尾部的修改这里不做详细描述,感兴趣的读者可直接阅读v3论文原文进行学习。
总结
最后一句话对MobileNet系列做个简单的总结,MobileNet v1就是加了深度可分离卷积的VGG;MobileNet v2则是在v1基础上加了Linear激活、Expansion layer和Inverted residual三大关键操作;而v3则是在v2基础上引入NAS,并且加入Squeeze and Excitation结构、h-swish激活和网络尾部优化等改进措施。
参考资料:
往期精彩:
点个在看