微博热搜数据探索与处理
👆👆👆关注我,和老表一起学Python、云服务器
一、前言
二、专栏概要
三、搞事情(上):读取mysql数据并进行数据探索与处理
3.1 pandas+sqlalchemy读取数据
3.2 数据探索与处理
四、下集预告

一、前言
今天的分享来满足这位读者的需求,想读“关于数据库sql或者MySQL的,就那种Python来处理数据库,比如Python爬虫爬到数据,然后封存到数据库里面,然后再从sql里面读取,进行分析可视化”。
后面写文章一方面是自己学习笔记,另外也会针对读者需求写一些专题文章,如果你有自己的想法,欢迎浏览器访问下方链接,或者点击阅读原文,给老表提意见:
https://shimo.im/forms/GryQ9CYRcxJ9hcYx/fill?channel=wechat二、专栏概要
直接来:一行代码爬取微博热搜数据 做准备:将爬取到的数据存入csv和mysql、其他数据库 搞事情(上):读取mysql数据并进行数据探索与处理 搞事情(下):读取处理好的数据并进行数据分析与可视化 进阶活:将可视化数据结果呈现到web页面(大屏可视化) 悄悄话:项目总结与思考,期待你的来稿
三、搞事情:读取mysql数据并进行数据分析与可视化
在上一节中,我们已经将数据存储到了MySQL数据库,本节我们将从数据库中读取出数据,然后进行数据探索和针对性处理。
3.1 pandas+sqlalchemy读取数据
我们采用的是pandas+sqlalchemy进行数据的存储读取等操作,原因嘛,对比其他的这个方法最快,最简单(上篇文章已经说过了),读取出来的数据就是dataframe格式,还可以在读取过程进行数据格式化,优秀。
读取数据:
# 调用pandas 的 read_sql 、读取数据
from sqlalchemy import create_engine
# 利用sqlalchemy的create_engine创建一个数据库连接引擎
engine = create_engine('mysql+pymysql://用户名:密码@localhost:3306/数据库名称?charset=utf8')
sql = 'select * from wb_hot'
# 第一个参数:查询sql语句
# 第二个参数:engine,数据库连接引擎
# 第三个参数:将指定列转换成指定的日期格式
pd_read_sql = pd.read_sql(sql, engine, parse_dates={'wb_first_time': "%Y:%m:%H:%M:%S"})
3.2 数据探索与处理
首先我们可以利用调用shape属性查看数据的规模,调用info函数查看数据信息,调用describe函数查看数据分布情况。
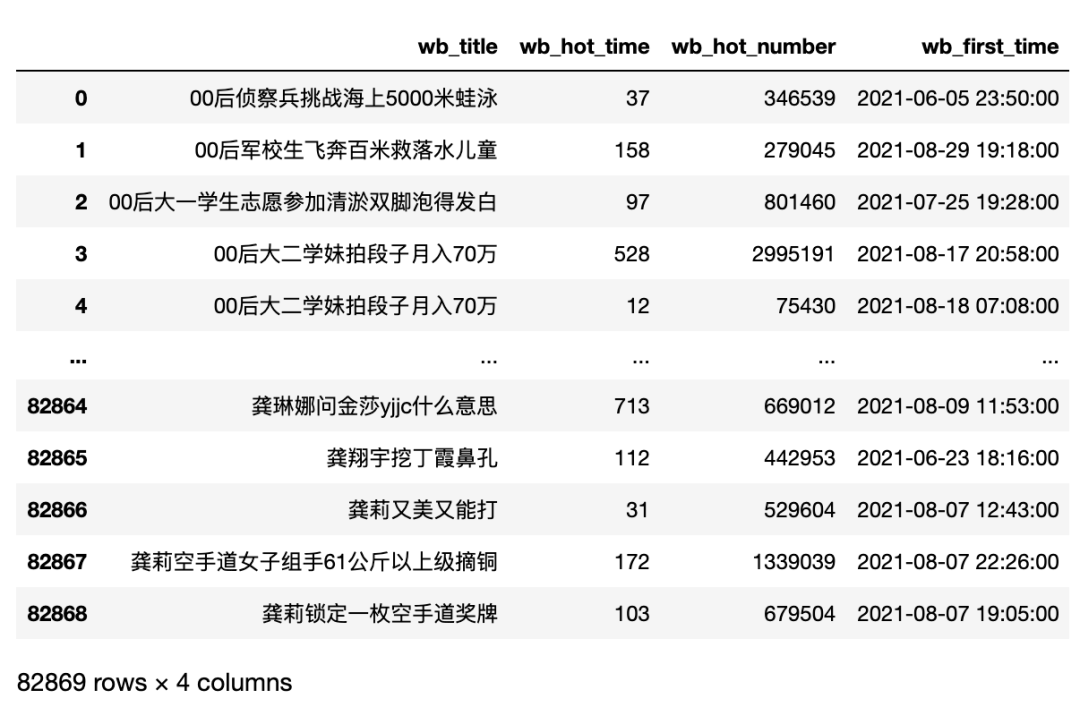
数据有82869行,4列
# 查看数据规模 多少行 多少列
pd_read_sql.shape
# ---输出--- #
(82869, 4)
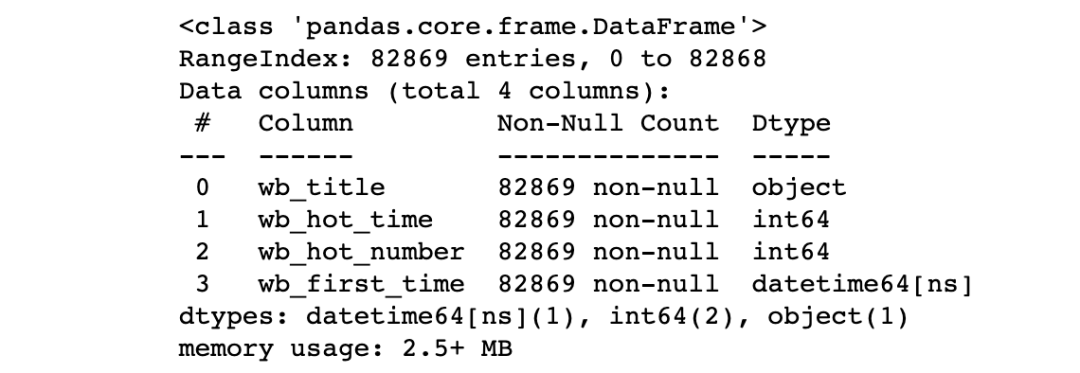
没有空值,we_title是字符串类型,web_hot_time和wb_hot_number是数值类型,wb_first_time是日期类型。
# 查看整体数据信息,包括每个字段的名称、非空数量、字段的数据类型查看数据基本信息
pd_read_sql.info()
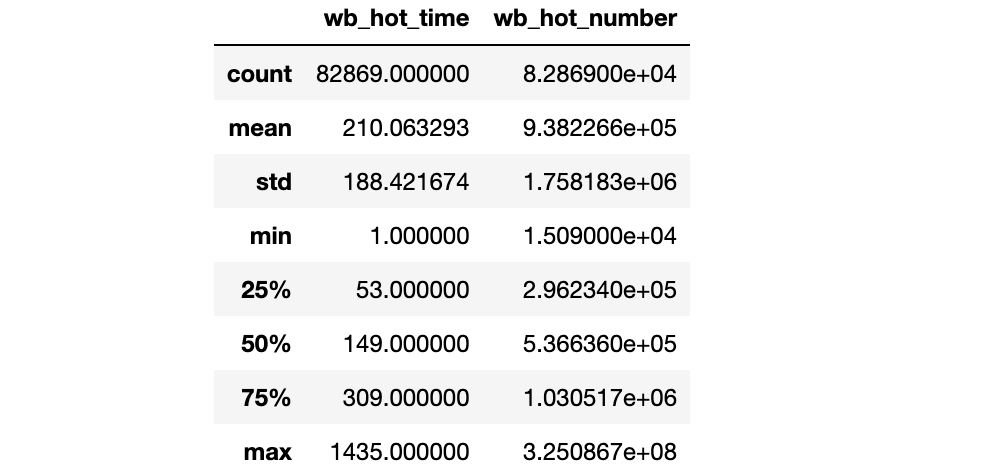
describe默认输出数值类型的列的各项指标数据。
# 查看数据表中数据类型的列的数据分布情况
'''
count:数量统计,非空值数量
mean:均值
std:标准差
min:最小值
25%:四分之一分位数
50%:二分之一分位数
75%:四分之三分位数
max:最大值
unipue:不同的值有多少个
top:出现次数最多的词
freq:top词出现的次数
'''
pd_read_sql.describe()
我们也可以看其他两列(非数值类型)的数据情况
# 查看单列的数据发布情况
pd_read_sql['wb_title'].describe()

看下微博热搜不同标题出现次数情况top10
# 统计所有热搜标题出现次数
pd_read_sql['wb_title'].value_counts()[:10]

通过上面基本探索,我们了解了数据的大概情况,目前数据只有四个维度,能分析的维度就很有限,所以我们需要先自己列下有哪些维度可以拆分、可以进行分析可视化,如下是我自己的简单思考:
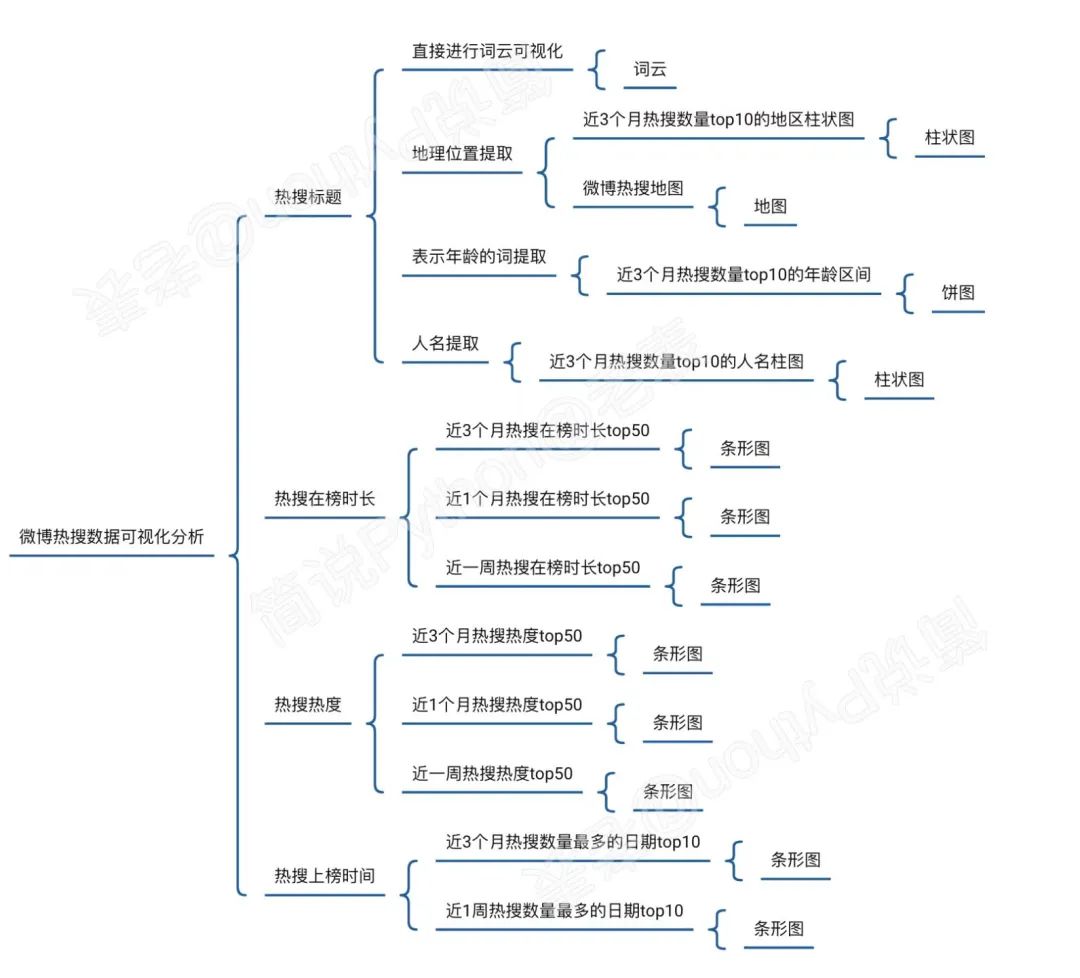
基于上面的内容,需要提前拆分的只有热搜标题,从里面我们可以拆分出热搜相关地理位置、热搜相关人名、热搜相关年龄段等数据。
那么接下来我们就想办法来拆分热搜标题吧~
这里我想到的是直接用现成的命名实体识别库来对热搜标题进行拆分,最先想到的就是之前毕设用过的Stanford CoreNLP,不过由于这个是Java写的,使用需要安装jdk,所以不太想用它,查了下,发现了一个只用python就可以的第三方库:foolnltk,
官方项目地址:https://github.com/rockyzhengwu/FoolNLTK
直接运行pip命令即可安装,不过包比较大(包括训练好的模型)、依赖也多,所以建议用镜像源安装,如:
pip3 install -i http://mirrors.aliyun.com/pypi/simple/ foolnltk

还可以直接调用一些免费、开放的接口,如百度大脑的词法分析,如果大家感兴趣,可以留言说说,下回给大家分享,也欢迎大家提前体验,将学习操作笔记分享给老表。
https://ai.baidu.com/tech/nlp_basic/lexical
安装好后,直接导入,你可能遇到下面问题,不要慌,这是tensorflow版本的问题,tf2.0以后移除了tf.contrib模块,所以我们直接安装低版本tf即可。
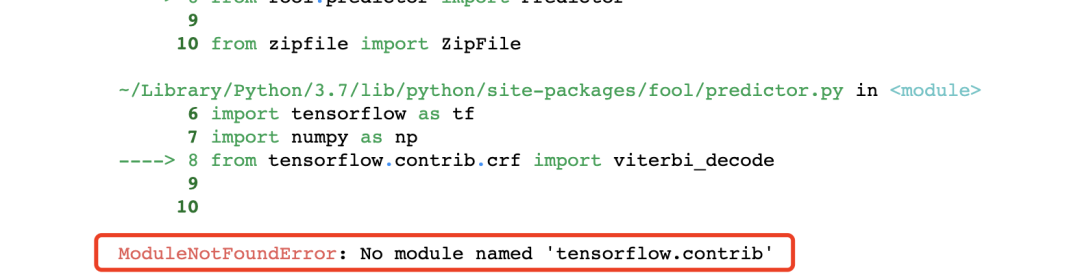
首先卸载tensorflow高版本,然后安装低版本,如1.15.0。
# 先卸载
pip3 install tensorflow
# 安装2.0以下的tensorflow版本 避免No module named 'tensorflow.contrib'
!pip3 install tensorflow==1.15
安装成功后,我们可以运行一个示例看看效果:
import fool
text = ["15地抵北京大兴机场航班取消"]
words, ners = fool.analysis(text)
print(ners)
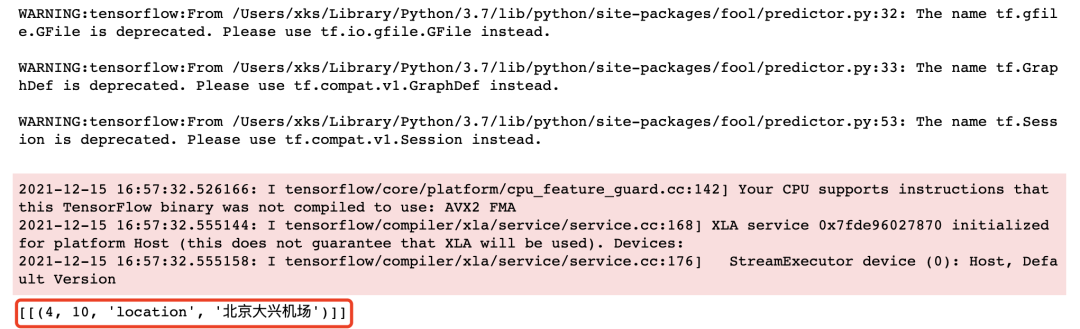
可以看到,结果是出来了,但是有警告提示,也很简单,按上面说明,到对应文件中改下代码即可,先看代码,我们直接调用了foolnltk的analysis函数,传入了一个列表参数(也可以是字符串),返回结果是一个元组。
words是对字符串的文本词性分析,ners是对文本的实体识别,每组是一个元组,其中第一个和第二个元素是识别出的内容在字符串中起始结束位置,第三个元素是字符串表示的含义,比如北京大兴机场被识别出是一个地名,用location表示,最后一个元素是识别出的字符串,而且ners是一个两层列表。
经过测试,我们发现person表示人名(如:赵丽颖),org表示组织名字(一般是国家组织,如:工信部),company表示公司名字(如:鸿星尔克)。
不过有点不太好的就是识别不是很准确,另外无法识别出表示年龄段的词,比如:00后这种,关于识别准确问题,这篇文章暂且这样处理,00后这种年龄段,我写了一个正则表达式来识别。
import re
def get_age_group(text):
data = re.findall('.*?(\d{2}后).*?', text)
if data:
return '-'.join(data)
else:
return ''
那么我们就需要增加五列:location、person、org、company、age,首先写一个函数,用于从一个热搜标题中解析出需要新增的内容,注意get_age_group函数之前上面已经写过啦,所以这里直接调用即可。
import fool
def get_key_word(text):
# 字典匹配速度快
result = {
'person': '',
'location': '',
'org': '',
'company': '',
}
words, ners = fool.analysis(text)
for ner in ners[0]:
if ner[2] in result:
result[ner[2]] = result[ner[2]] + '-' + ner[3]
return result['person'], result['location'], result['org'], result['company'], get_age_group(text)
然后我们写几行代码对原数据进行批量处理,这里我们主要用到了apply函数去批量处理wb_title数据,然后利用concat函数将新增数据和原始数据合并。
import time
# 新增五列 位置 姓名 组织 公司 年龄段
t1 = time.time() # 时间戳 单位秒
print(f'热搜标题处理开始时间:{t1}')
# 从wb_title中解析出新增列
pd_test = pd_read_sql['wb_title'].apply(get_key_word)
t2 = time.time() # 时间戳 单位秒
print(f'热搜标题解析结束时间:{t2}')
print(f'成功解析了数据{pd_test.shape[0]}条,耗费时间:{(t2-t1)/60:.2}分钟')
# 处理新增列
pd_test = pd.DataFrame(list(pd_test), columns=['person', 'location', 'org', 'company', 'age'])
# 合并
pd_all = pd.concat([pd_read_sql, pd_test], axis=1)
t3 = time.time() # 时间戳 单位秒
print(f'热搜标题处理结束时间:{t3}')
print(f'成功处理了数据{pd_all.shape[0]}条,耗费时间:{(t3-t2)/60:.2}分钟')

一共八万多条数据,整个解析花费了7分钟左右,数据处理好后,我们先保存一份到本地,避免系统突然奔溃或者啥误操作,又得重新来过。
# 处理好的数据 首先本地保存下
pd_all.to_csv('wb_data_1.csv', encoding='utf-8_sig',index=False)
# 然后查看下数据的基本情况
pd_all.info()

四、下集预告
以上,相对简洁的给大家分享了如何读取数据,并根据分析维度出发,去拆分、处理现有数据。
下一讲中,我们将一起学习对处理好的数据如何进行数据分析与可视化,也欢迎大家在留言区提出更多可以分析的角度,关于数据分析与可视化这一节,你还想学习什么其他的内容也可以在评论区、留言区进行留言。
点赞+留言+转发,就是对我最大的支持啦~
--End--
如何找到我:
学习更多: 整理了我开始分享学习笔记到现在超过250篇优质文章,涵盖数据分析、爬虫、机器学习等方面,别再说不知道该从哪开始,实战哪里找了 “点赞”就是对博主最大的支持