
【论文解读】腾讯FAT | 未来感知的多样化趋势推荐框架
“本文介绍了腾讯提出的一种未来感知的多样化趋势推荐框架FAT,根据相似用户的行为来构建未来序列,再通过动态路由学习多样化的趋势。实验表明,考虑了潜在未来偏好趋势的FAT不仅能够提升推荐的准确性,也能提高多样性。”
本文介绍的论文是《Future-Aware Diverse Trends Framework for Recommendation》
摘要
在推荐系统的用户表示学习中,对用户-项目交互的建模很重要。现有的序列推荐系统通过用户历史序列来捕捉历史偏好。然而,用户的偏好是「不断变化且多样化」的,仅仅对历史偏好建模(不考虑偏好随时间变化的趋势)可能导致推荐多样性、时效性不足。
本文为缩小「历史偏好」和「潜在未来偏好」之间的gap,提出了未来感知的多样化趋势(FAT)框架。其中未来感知是指根据「相似用户」来构建目标用户的「未来序列」(提出了一种邻居行为提取器);多样化趋势是指:认为未来偏好是多样化的,提出了多样化趋势提取器和时间感知的注意力机制,使用「多个向量」表达用户潜在的偏好趋势。利用历史偏好和潜在未来趋势进行最终的推荐。实验表明,FAT不仅能够提升序列推荐的准确性,也能提高推荐的「多样性」和时效性。
贡献
为更好地捕捉用户行为的动态变化,设计了一个FAT框架,利用了未来信息并捕捉了多样化的用户偏好趋势。 首先从相似用户中提取未来行为,然后利用动态路由进行自适应的融合(也可以理解为聚类),得到趋势向量。然后使用时间感知的注意力机制来更好地建模随时间变化的用户潜在偏好。 与现有方法相比,FAT在几个公开数据集上效果更好,且FAT召回的项目具有更高的多样性
模型
模型结构图:
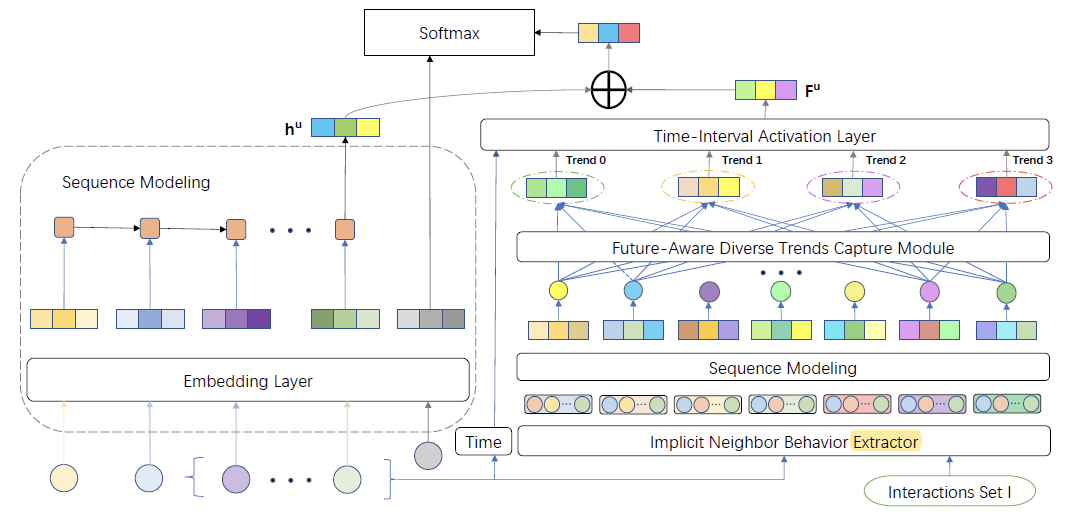
左侧:对当前用户的历史序列建模,得到历史偏好向量 。灰色小球和向量表示对待预测item做embedding,后面预测层使用。
右侧:为当前用户找到多个相似用户,对每个相似用户进行历史序列建模,得到其偏好向量。这些偏好向量经过一个胶囊网络得到T个趋势向量,再通过时间感知的注意力层来融合,得到未来偏好向量。
下面对每个模块进行具体介绍:
Sequence Modeling
输入是按照时间排列的用户历史行为序列,对这些item id做embedding之后使用LSTM提取序列特征(LSTM公式不再赘述),得到用户的偏好向量。
相似用户的历史序列同样也使用LSTM来进行特征提取。
Implicit Neighbor Behavior Extractor
用皮尔逊相关系数来计算用户间相似度 (但作者并未说明找到相似用户后如何构建序列)。除此之外,也设计了一个更简单的过滤器来提取相似用户:
在当前用户的历史序列中,挑出K个目标项目用于训练,剩下的用于测试。实际中K=1的效果就足够好且简单。(论文也没写K>1时具体怎么处理,是分别用每个target item跑一遍右侧的网络,然后得到K个和拼接?还是找那些和这K个target items都有过交互的用户?)
找出与目标项目交互过的所有用户,然后对每个近邻用户(使用目标项目找到的)构建未来序列:
「举个例子」描述一下模型的主要思想:
我今天买了《深度学习推荐系统》,模型在给我推荐时,会参考其他买了这本书的用户「后面会买什么」。假如有5个用户也买了这本书,其中用户a, c后面买了《计算广告》(「继续深入学习」),用户b, d, e后面买了《java从入门到精通》(「弃坑转方向」),这就代表未来两种不同的偏好趋势。动态路由部分的任务就是从这5个用户中,学习出(也可以理解为聚类)2个趋势 。
那模型又怎么确定我更可能偏向哪种趋势呢?这个任务就交给后面的注意力部分了,主要根据时间间隔来判断(这里感觉不太合理,只看时间间隔,并不能体现我更偏向哪种趋势呀)。
Future-Aware Diverse Trends
把每个近邻用户的偏好向量作为邻居胶囊,使用动态路由来学习兴趣胶囊。具体过程为:
其中为输入的邻居胶囊,代表低阶胶囊与高阶胶囊连接的概率。
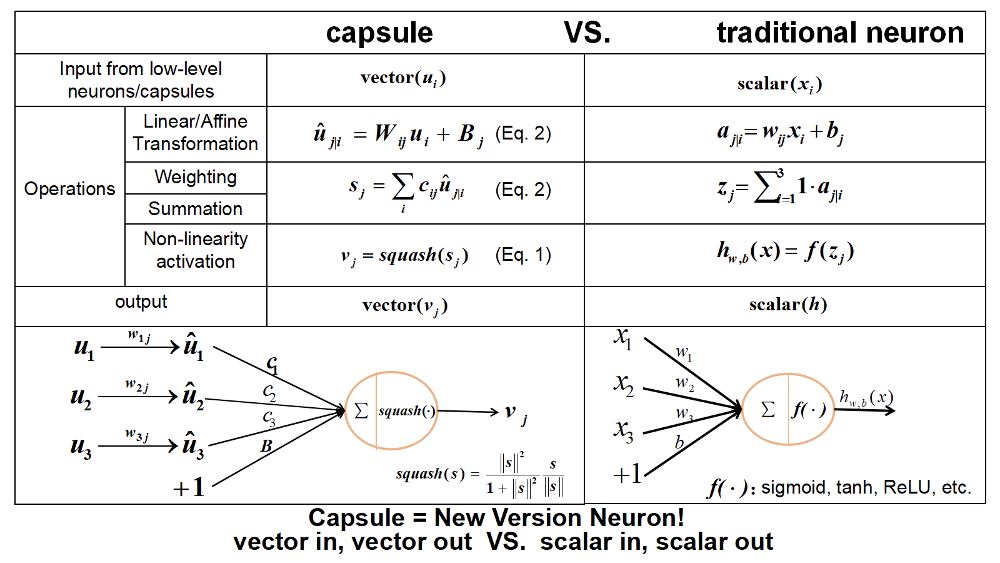
胶囊网络可以看作一种“向量神经元”,其输入和输出都是「向量」,且每一步也都可以与传统的标量神经元对应,对比如下(图片来自文献2):
Time-Aware Attention Layer
使用一种时间感知的注意力机制来计算多个趋势的权重 捕捉每个趋势的时效性
计算用户u最终的未来偏好:
其中是target item 的交互时间,是趋势的交互时间,即对与趋势相关的项目的交互时间取平均值(从items变到trends经过了LSTM以及动态路由,那一个item怎么样算是related to the trend?论文并没有说明)。是趋势的向量表示
,,分别对应注意力机制中的q, k, v(即query, key, value)。通过衡量q和k之间的相关性(这里即时间上相隔的远近),找出与q相关的value,再对value进行加权求和。这里的时间应该是归一化后的,即0~1之间的值,这样可以让与间隔更近的trend的权重更高,即最近的兴趣趋势在中占比更高。
Prediction
得到attention激活后的趋势向量后,将其与用户历史偏好向量拼接(所以是保证拼接后的向量维度与item embedding一致?K>1时也是这样处理吗?可能会有问题啊),作为用户最终的偏好向量。给定一个训练样本以及用户的偏好向量、项目的向量表示,通过如下公式来计算交互概率:
其中U, V, I分别是用户集合、项目集合、交互集合。
实验
模型效果对比
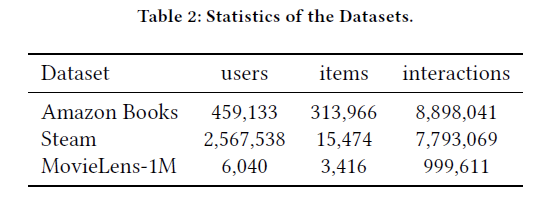
实验数据集及其统计信息:
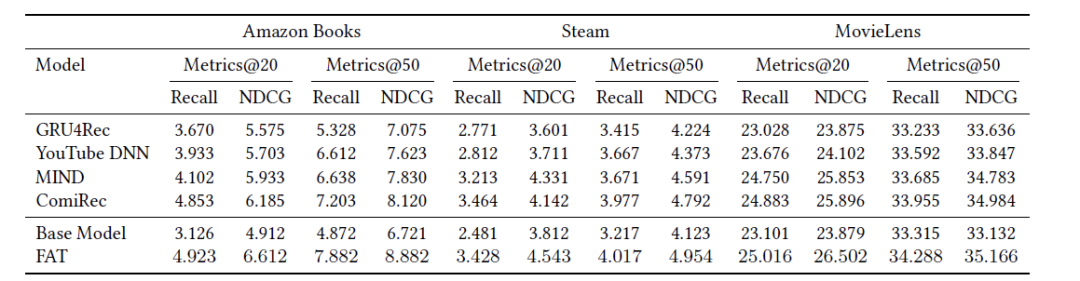
评价指标选取Recall和NDCG。对比结果:
推荐多样性
这里是使用项目类目的多样性来衡量,具体公式如下:
多样性的对比结果:
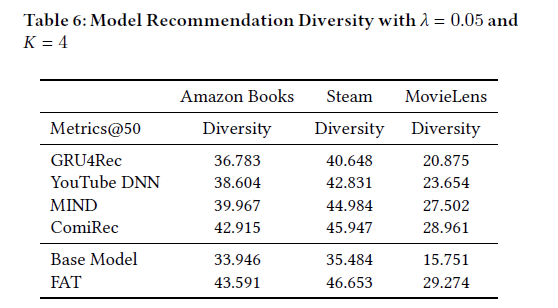
实验结果表明,FAT不仅能够提升序列推荐的效果,也能提高推荐的多样性。
Case Study
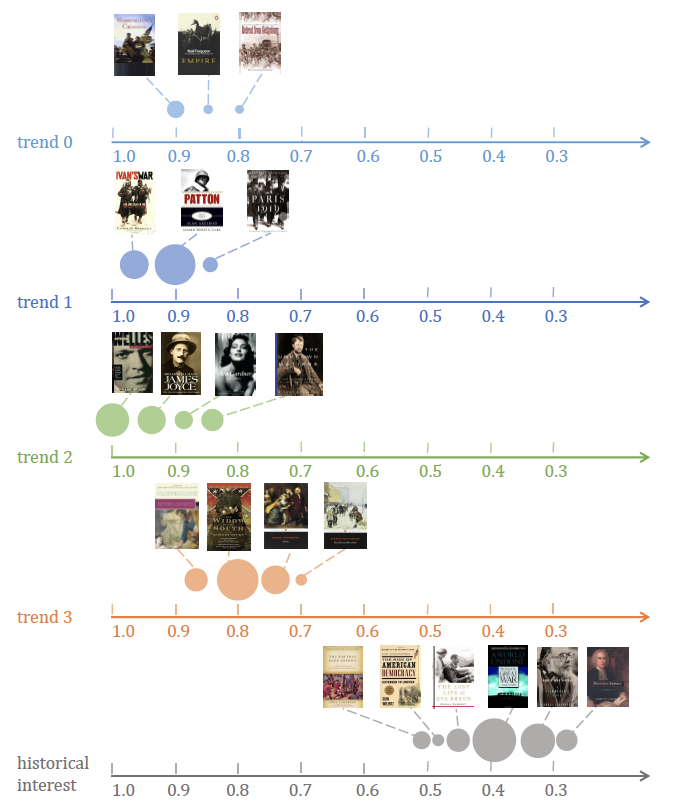
上图是为某用户召回的项目的分布。由于论文对图中横坐标和圆圈的意义描述有歧义,这里说一下笔者的愚见:
圆圈大小代表项目和trend或历史兴趣的相似度,横坐标中的数值代表透出概率。
结果显示,如果使用历史偏好进行推荐,即使是很相似的项目,其透出概率也很低;但如果使用FAT学习出的trend向量找相似的项目,就很容易被推荐出去,体现了本文中未来偏好趋势建模的有效性。
参考文献
[1] Lu Y, Zhang S, Huang Y, et al. Future-Aware Diverse Trends Framework for Recommendation[J]. arXiv preprint arXiv:2011.00422, 2020.
[2] CapsNet-Tensorflow, https://github.com/naturomics/CapsNet-Tensorflow
往期精彩回顾
获取本站知识星球优惠券,复制链接直接打开:
https://t.zsxq.com/qFiUFMV
本站qq群704220115。
加入微信群请扫码: