
分布式机器学习原理及实战(Pyspark)
一、大数据框架及Spark介绍
1.1 大数据框架
大数据(Big Data)是指无法在一定时间内用常规软件工具对其内容进行抓取、管理和处理的数据集合。大数据技术,是指从各种各样类型的数据中,快速获得有价值信息的能力。
自2003年Google公布了3篇大数据奠基性论文,为大数据存储及分布式处理的核心问题提供了思路:非结构化文件分布式存储(GFS)、分布式计算(MapReduce)及结构化数据存储(BigTable),并奠定了现代大数据技术的理论基础,而后大数据技术便快速发展,诞生了很多日新月异的技术。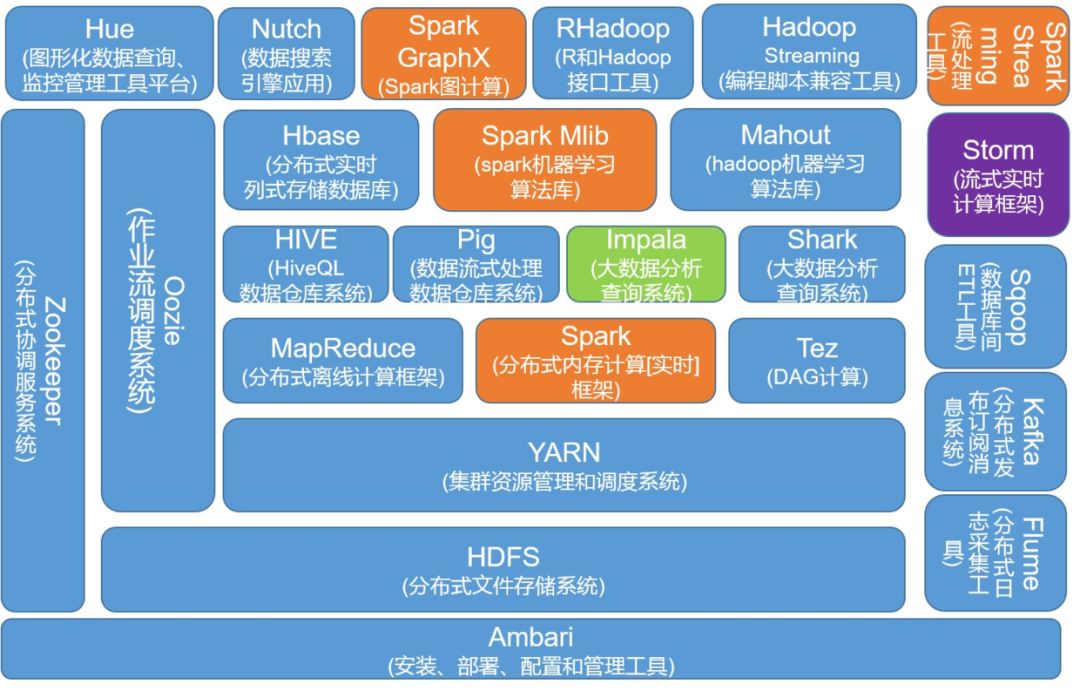 归纳现有大数据框架解决的核心问题及相关技术主要为:
归纳现有大数据框架解决的核心问题及相关技术主要为:
分布式存储的问题:有GFS,HDFS等,使得大量的数据能横跨成百上千台机器; 大数据计算的问题:有MapReduce、Spark批处理、Flink流处理等,可以分配计算任务给各个计算节点(机器); 结构化数据存储及查询的问题:有Hbase、Bigtable等,可以快速获取/存储结构化的键值数据; 大数据挖掘的问题:有Hadoop的mahout,spark的ml等,可以使用分布式机器学习算法挖掘信息;
1.2 Spark的介绍
Spark是一个分布式内存批计算处理框架,Spark集群由Driver, Cluster Manager(Standalone,Yarn 或 Mesos),以及Worker Node组成。对于每个Spark应用程序,Worker Node上存在一个Executor进程,Executor进程中包括多个Task线程。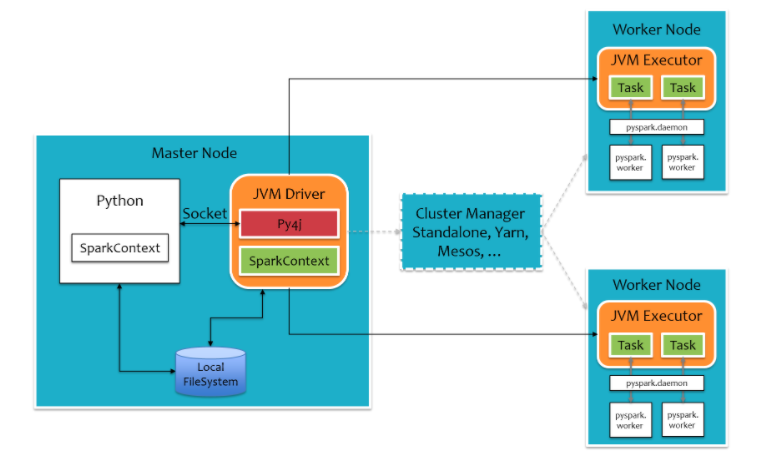 在执行具体的程序时,Spark会将程序拆解成一个任务DAG(有向无环图),再根据DAG决定程序各步骤执行的方法。该程序先分别从textFile和HadoopFile读取文件,经过一些列操作后再进行join,最终得到处理结果。
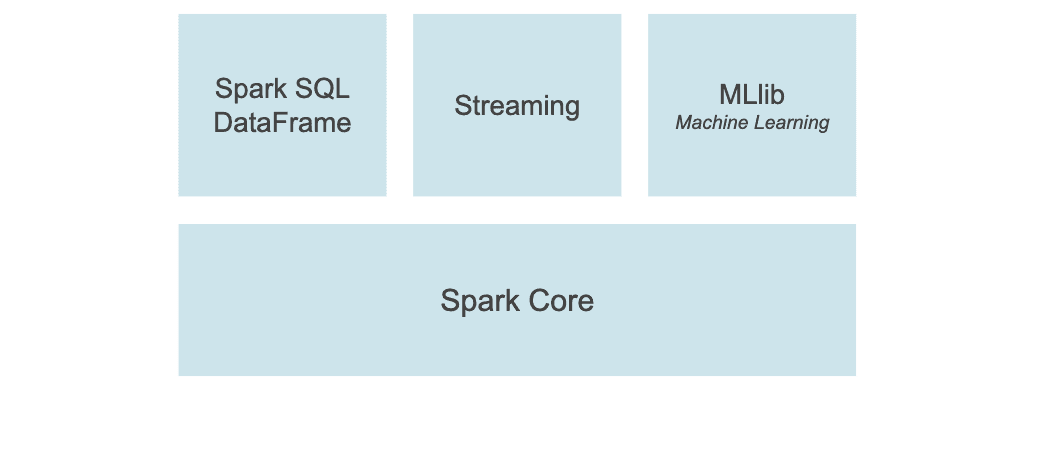
在执行具体的程序时,Spark会将程序拆解成一个任务DAG(有向无环图),再根据DAG决定程序各步骤执行的方法。该程序先分别从textFile和HadoopFile读取文件,经过一些列操作后再进行join,最终得到处理结果。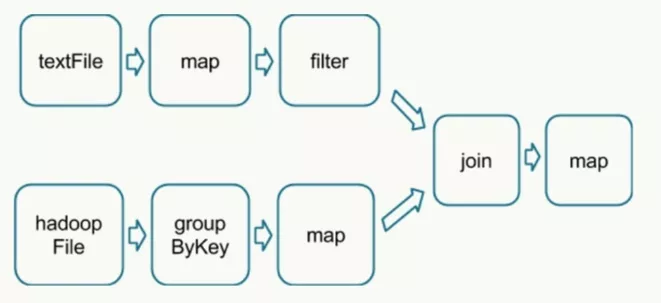 PySpark是Spark的Python API,通过Pyspark可以方便地使用 Python编写 Spark 应用程序, 其支持 了Spark 的大部分功能,例如 Spark SQL、DataFrame、Streaming、MLLIB(ML)和 Spark Core。
PySpark是Spark的Python API,通过Pyspark可以方便地使用 Python编写 Spark 应用程序, 其支持 了Spark 的大部分功能,例如 Spark SQL、DataFrame、Streaming、MLLIB(ML)和 Spark Core。
二、PySpark分布式机器学习
2.1 PySpark机器学习库
Pyspark中支持两个机器学习库:mllib及ml,区别在于ml主要操作的是DataFrame,而mllib操作的是RDD,即二者面向的数据集不一样。相比于mllib在RDD提供的基础操作,ml在DataFrame上的抽象级别更高,数据和操作耦合度更低。
注:mllib在后面的版本中可能被废弃,本文示例使用的是ml库。
pyspark.ml训练机器学习库有三个主要的抽象类:Transformer、Estimator、Pipeline。
Transformer主要对应feature子模块,实现了算法训练前的一系列的特征预处理工作,例如MinMaxScaler、word2vec、onehotencoder等,对应操作为transform;
# 举例:特征加工
from pyspark.ml.feature import VectorAssembler
featuresCreator = VectorAssembler(
inputCols=[col[0] for col in labels[2:]] + [encoder.getOutputCol()],
outputCol='features'
)
Estimator对应各种机器学习算法,主要为分类、回归、聚类和推荐算法4大类,具体可选算法大多在sklearn中均有对应,对应操作为fit;
# 举例:分类模型
from pyspark.ml.classification import LogisticRegression
logistic = LogisticRegression(featuresCol=featuresCreator.getOutputCol(),
labelCol='INFANT_ALIVE_AT_REPORT')
Pipeline可将一些列转换和训练过程串联形成流水线。
# 举例:创建流水线
from pyspark.ml import Pipeline
pipeline = Pipeline(stages=[encoder, featuresCreator, logistic]) # 特征编码,特征加工,载入LR模型
# 拟合模型
train, test = data.randomSplit([0.7,0.3],seed=123)
model = pipeline.fit(train)
2.2 PySpark分布式机器学习原理
在分布式训练中,用于训练模型的工作负载会在多个微型处理器之间进行拆分和共享,这些处理器称为工作器节点,通过这些工作器节点并行工作以加速模型训练。分布式训练可用于传统的 ML 模型,但更适用于计算和时间密集型任务,如用于训练深度神经网络。分布式训练有两种主要类型:数据并行及模型并行,主要代表有Spark ML,Parameter Server和TensorFlow。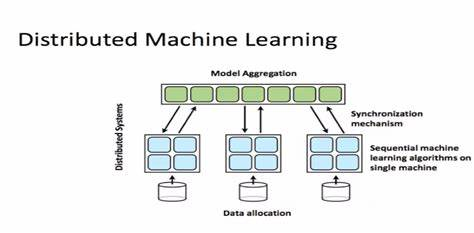
spark的分布式训练的实现为数据并行:按行对数据进行分区,从而可以对数百万甚至数十亿个实例进行分布式训练。以其核心的梯度下降算法为例:
1、首先对数据划分至各计算节点;
2、把当前的模型参数广播到各个计算节点(当模型参数量较大时会比较耗带宽资源);
3、各计算节点进行数据抽样得到mini batch的数据,分别计算梯度,再通过treeAggregate操作汇总梯度,得到最终梯度gradientSum;
4、利用gradientSum更新模型权重(这里采用的阻断式的梯度下降方式,当各节点有数据倾斜时,每轮的时间取决于最慢的节点。这是Spark并行训练效率较低的主要原因)。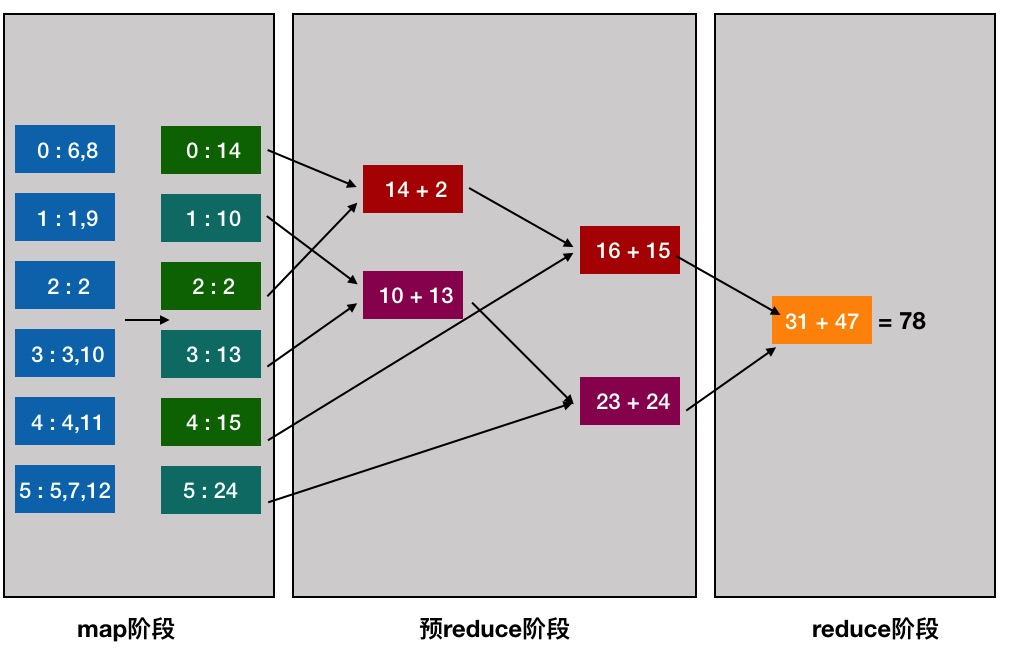
PySpark项目实战
注:单纯拿Pyspark练练手,可无需配置Pyspark集群,直接本地配置下单机Pyspark,也可以使用线上spark集群(如: community.cloud.databricks.com)。
本项目通过PySpark实现机器学习建模全流程:包括数据的载入,数据分析,特征加工,二分类模型训练及评估。
#!/usr/bin/env python
# coding: utf-8
# 初始化SparkSession
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("Python Spark RF example").config("spark.some.config.option", "some-value").getOrCreate()
# 加载数据
df = spark.read.format('com.databricks.spark.csv').options(header='true', inferschema='true').load("./data.csv",header=True)
from pyspark.sql.functions import *# 数据基本信息分析
df.dtypes # Return df column names and data types
df.show() #Display the content of df
df.head() #Return first n rows
df.first() #Return first row
df.take(2) #Return the first n rows
df.schema # Return the schema of df
df.columns # Return the columns of df
df.count() #Count the number of rows in df
df.distinct().count() #Count the number of distinct rows in df
df.printSchema() #Print the schema of df
df.explain() #Print the (logical and physical) plans
df.describe().show() #Compute summary statistics
df.groupBy('Survived').agg(avg("Age"),avg("Fare")).show() # 聚合分析
df.select(df.Sex, df.Survived==1).show() # 带条件查询
df.sort("Age", ascending=False).collect() # 排序# 特征加工
df = df.dropDuplicates() # 删除重复值
df = df.na.fill(value=0) # 缺失填充值
df = df.na.drop() # 或者删除缺失值
df = df.withColumn('isMale', when(df['Sex']=='male',1).otherwise(0)) # 新增列:性别0 1
df = df.drop('_c0','Name','Sex') # 删除姓名、性别、索引列
# 设定特征/标签列
from pyspark.ml.feature import VectorAssembler
ignore=['Survived']
vectorAssembler = VectorAssembler(inputCols=[x for x in df.columns
if x not in ignore], outputCol = 'features')
new_df = vectorAssembler.transform(df)
new_df = new_df.select(['features', 'Survived'])
# 划分测试集训练集
train, test = new_df.randomSplit([0.75, 0.25], seed = 12345)
# 模型训练
from pyspark.ml.classification import LogisticRegression
lr = LogisticRegression(featuresCol = 'features',
labelCol='Survived')
lr_model = lr.fit(test)
# 模型评估
from pyspark.ml.evaluation import BinaryClassificationEvaluator
predictions = lr_model.transform(test)
auc = BinaryClassificationEvaluator().setLabelCol('Survived')
print('AUC of the model:' + str(auc.evaluate(predictions)))
print('features weights', lr_model.coefficientMatrix)
文章首发于算法进阶,公众号阅读原文可访问GitHub项目源码