
PySpark ML——分布式机器学习库
导读
继续PySpark学习之路,本篇开启机器学习子模块的介绍,不会更多关注机器学习算法原理,仅对ML库的基本框架和理念加以介绍。最后用一个小例子实战对比下sklearn与pyspark.ml库中随机森林分类器效果。

前文介绍到,spark在核心数据抽象RDD的基础上,支持4大组件,其中机器学习占其一。进一步的,spark中实际上支持两个机器学习模块,MLlib和ML,区别在于前者主要是基于RDD数据结构,当前处于维护状态;而后者则是DataFrame数据结构,支持更多的算法,后续将以此为主进行迭代。所以,在实际应用中优先使用ML子模块,本文也将针对此介绍。
与此同时,spark.ml库与Python中的另一大机器学习库sklearn的关系是:spark.ml库支持大部分机器学习算法和接口功能,虽远不如sklearn功能全面,但主要面向分布式训练,针对大数据;而sklearn是单点机器学习算法库,支持几乎所有主流的机器学习算法,从样例数据、特征选择、模型选择和验证、基础学习算法和集成学习算法,提供了机器学习一站式解决方案,但仅支持并行而不支持分布式。
所以在实际应用中,可综合根据数据体量大小和具体机器学习算法决定采用哪个框架。
相比于sklearn十八般武器俱全,pyspark.ml训练机器学习库其实主要就是三板斧:Transformer、Estimator、Pipeline。其中:
Transformer主要对应feature子模块,实现了算法训练前的一系列的特征预处理工作,例如word2vec、onehotencoder等,主要对应操作为transform
Estimator对应各种机器学习算法,主要区分分类、回归、聚类和推荐算法4大类,具体可选算法大多在sklearn中均有对应,主要对应操作为fit
Pipeline是为了将一些列转换和训练过程形成流水线的容器(实际在sklearn中也有pipeline),类似于RDD在转换过程中形成DAG的思路一致,分阶段调用transformer中的transform操作或estimator中的fit操作
具体各模块不再详细给出,仅补充如下3点说明:
延迟执行:延迟执行是基于DAG实现,也是Spark实现运行效率优化的一大关键。无论是基于RDD数据抽象的MLlib库,还是基于DataFrame数据抽象的ML库,都沿袭了spark的这一特点,即在中间转换过程时仅记录逻辑转换顺序,而直到遇有产出非结果时才真正执行,例如评估和预测等;
DataFrame增加列:DataFrame是不可变对象,所以在实际各类transformer处理过程中,处理的逻辑是在输入对象的基础上增加新列的方式产生新对象,所以多数接口需指定inputCol和outCol参数,理解这一过程会更有助于学习ml处理和训练流程;
算法与模型:个人认为这是spark.ml中比较好的一个细节,即严格区分算法和模型的定义边界,而这在其他框架或大多数学习者的认知中是一个模糊的概念。在Spark中,算法是通常意义下的未经过训练的机器学习算法,例如逻辑回归算法、随机森林算法,由于未经过训练,所以这里的算法是通用的;而模型则是经过训练后产出的带有参数配置的算法,经过训练后可直接用于预测和生产。所以,从某种意义上讲,模型=算法+配套参数。在spark中,模型在相应算法命名基础上带有Model后缀,例如LinearSVC和LinearSVCModel,前者是算法,后者则是模型。
这里仍然是采用之前的一个案例(武磊离顶级前锋到底有多远?),对sklearn和pyspark.ml中的随机森林回归模型进行对比验证。具体数据和特征构建的过程可查阅前文了解,这里不再赘述。
选取球员各项能力数据,对PES中球员星级(取值为1-5,多分类任务)进行预测,训练集和测试集比例为7:3。两个库中模型参数均采用相同参数(训练100棵最大深度为5的决策树,构建随机森林)。基于测试集对多分类结果预测准确率进行评估,得到结果对比如下:
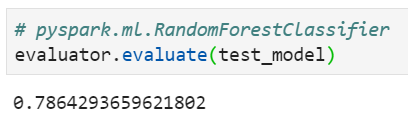
spark机器学习中的随机森林分类器准确率

sklearn中的随机森林分类器准确率
sklearn中随机森林分类器评分要更高一些,更进一步深入的对比分析留作后续探索。
相关阅读: