
Mobile-Former | MobileNet+Transformer轻量化模型(精度速度秒杀MobileNet)


微软提出Mobile-Former,MobileNet和Transformer的并行设计,可以实现局部和全局特征的双向融合,在分类和下游任务中,性能远超MobileNetV3等轻量级网络!
作者单位:微软, 中科大
1背景
最近,Vision Transformer(ViT)展示了全局处理的优势,与cnn相比实现了显著的性能提升。然而,当将计算预算限制在1G FLOPs内时,增益维特减少。如果进一步挑战计算成本,基于depthwise和pointwise卷积的MobileNet和它的扩展仍然占据着一席之地(例如,少于300M的FLOPs图像分类),这又自然而然地提出了一个问题:
如何设计有效的网络来有效地编码局部处理和全局交互?
一个简单的想法是将卷积和Vision Transformer结合起来。最近的研究表明,将卷积和Vision Transformer串联在一起,无论是在开始时使用卷积,还是将卷积插入到每个Transformer块中都是有益的。
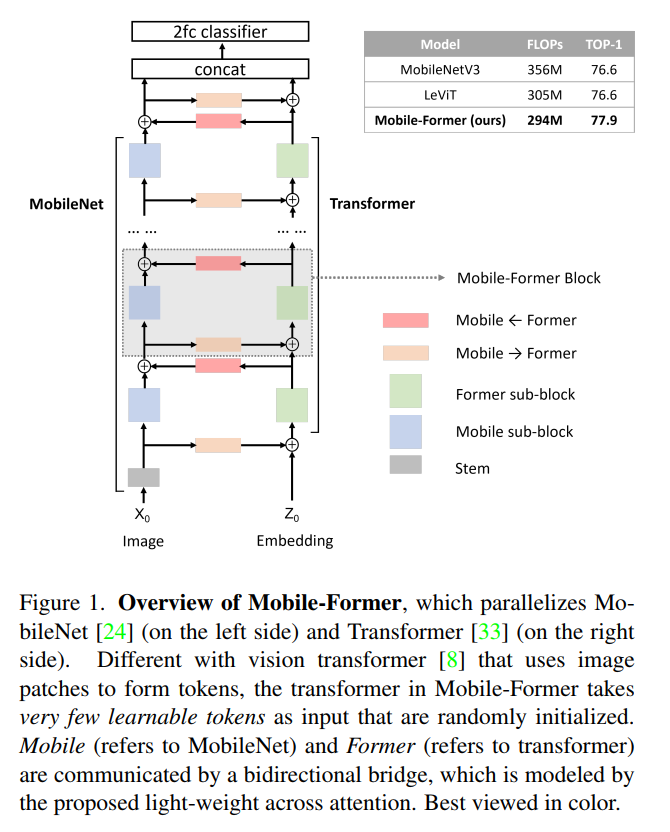
图1
在本文中,作者将设计范式从串联向并联转变,提出了一种新的MobileNet和Transformer并行化,并在两者之间建立双向桥接(见图)。将其命名为Mobile-Former,其中Mobile指MobileNet, Former指transformer。Mobile以图像为输入堆叠mobile block(或inverted bottleneck)。它利用高效的depthwise和pointwise卷积来提取像素级的局部特征。前者以一些可学习的token作为输入,叠加multi-head attention和前馈网络(FFN)。这些token用于对图像的全局特征进行编码。
Mobile-Former是MobileNet和Transformer的并行设计,中间有一个双向桥接。这种结构利用了MobileNet在局部处理和Transformer在全局交互方面的优势。并且该桥接可以实现局部和全局特征的双向融合。与最近在视觉Transformer上的工作不同,Mobile-Former中的Transformer包含非常少的随机初始化的token(例如少于6个token),从而导致计算成本低。
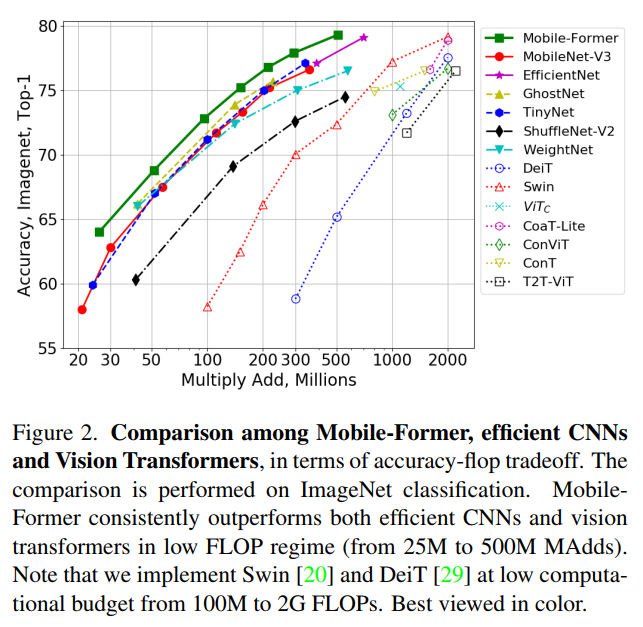
结合提出的轻量级交叉注意力对桥接进行建模,Mobile-Former不仅计算效率高,而且具有更强的表示能力,在ImageNet分类上从25M到500MFLOPs的低 FLOPs机制下优于MobileNetV3。例如,它在294M FLOPs下实现了77.9%的top-1准确率,比MobileNetV3提高了1.3%,但节省了17%的计算量。在转移到目标检测时,Mobile-Former 比MobileNetV3高8.6 AP。
2相关工作
2.1 轻量化CNN模型
mobilenet提出了一种在inverted bottleneck结构中使用depthwise和pointwise卷积对局部处理建模的有效方法。使用group卷积和channel shuffle来简化pointwise卷积的shuffle。此外,MicroNet提出了micro-factorized 卷积,优化了inverted bottleneck和group卷积的组合,在极低的FLOPs下实现了可靠的性能。其他有效的操作包括傅里叶变换、GhostNet中的线性变换,以及在AdderNet中使用廉价的加法替代大规模乘法。此外,还研究了不同的体系结构。MixConv探索了混合多个核大小,Sandglass inverted residual block的结构。EfficientNet和TinyNet研究深度、宽度和分辨率的复合缩放。
2.2 Vision Transformers
最近,ViT及其后续在多个视觉任务上取得了令人印象深刻的表现。原始的ViT需要在大型数据集(如JFT-300M)上进行训练才能表现良好。后来,DeiT通过引入几个重要的训练策略,证明了在较小的ImageNet-1K数据集上可以获得良好的性能。为实现高分辨率图像的ViT,提出了几种分层Transformer。
例如,Swin提出了在局部窗口内计算自注意力的移位窗口方法,CSWin通过引入十字形窗口自注意力进一步改进了该方法。T2T-ViT通过递归聚合相邻的token逐步将图像转换为token从而可以很好地建模局部结构。HaloNet开发了两种注意力扩展(blocked local attention和attention downsampling)从而提高了速度、内存使用以及准确性。
2.3 CNNs与ViT结合
近研究结果表明,卷积与Transformer相结合在预测精度和训练稳定性上都有提高。
通过在ResNet的最后3个bottleneck block中使用全局自注意力替换空间卷积,BoTNet在实例分割和目标检测方面有了显著的改进。
通过引入门控位置自注意力(GPSA),ConViT通过soft卷积归纳偏差改进了ViT。
CvT在每个multi-head attention之前引入了depthwise/pointwise卷积。
LeViT和ViTC使用convolutional stem (stacking
convolutions)代替patchify stem。LeViT和ViTC在低FLOP状态下有明显改善。在本文中作者提出了一个不同的设计,并行MobileNet和Transformer之间的双向交叉注意力。本文的方法既高效又有效,在低FLOP状态下优于高效CNN和ViT变种。
3Mobile-Former
Mobile-Former将MobileNet和transformer并行化,并通过双向交叉注意力将两者连接起来(见图1)。Mobile-former中,Mobile(简称MobileNet)以一幅图像作为输入
,采用inverted bottleneck block提取局部特征。前者(指transformer)以可学习参数(或token)作为输入,记为
,其中d和M分别为token的维数和数量。这些token被随机初始化,每个token表示图像的全局先验。这与Vision Transformer(ViT)不同,在ViT中,token线性地投射局部图像patch。这种差异非常重要,因为它显著减少了token的数量从而产生了高效的Former。
3.1 Low Cost Two-Way Bridge
作者利用cross attention的优势融合局部特性(来自Mobile)和全局token(来自Former)。这里为了降低计算成本介绍了2个标准cross attention计算:
在channel数较低的MobileNet Bottlneck处计算cross attention;
在Mobile position数量很大的地方移除预测
,但让他们在Former之中。
将局部特征映射表示为x,全局token表示为z。它们被分割为
和
表示有H个头的多头注意力。从局部到全局的轻量级cross attention定义如下:
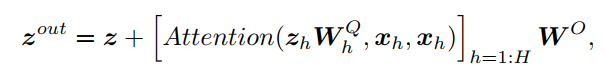
其中
是第h个head的query投影矩阵,
用于将多个head组合在一起,Attention(
)是query Q、key K和value V上的标准自注意力函数,如下所示:
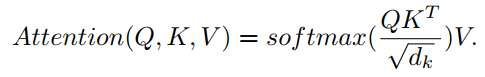
注意,全局特性
是query,而局部feat x是key和value。
和
应用于全局token z上。这个cross attention如图3(Mobile
Former)所示。
以类似的方式,从全局到局部的cross attention计算如下:
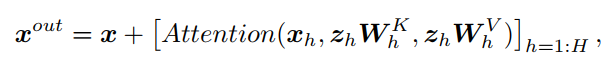
其中
和
是key和value的投影矩阵。在这里,局部feat x是query,而全局feat z是key和value。这种cross attention的图表如图3(Mobile
Former)所示。
3.2 Mobile-Former Block
Mobile-Former可以解耦为Mobile-Former块的堆栈(见图1)。每个块包括Mobile sub-block、Former sub-block和双向桥接(Mobile
Former和Mobile
Former)。Mobile-Former块的细节如图3所示。
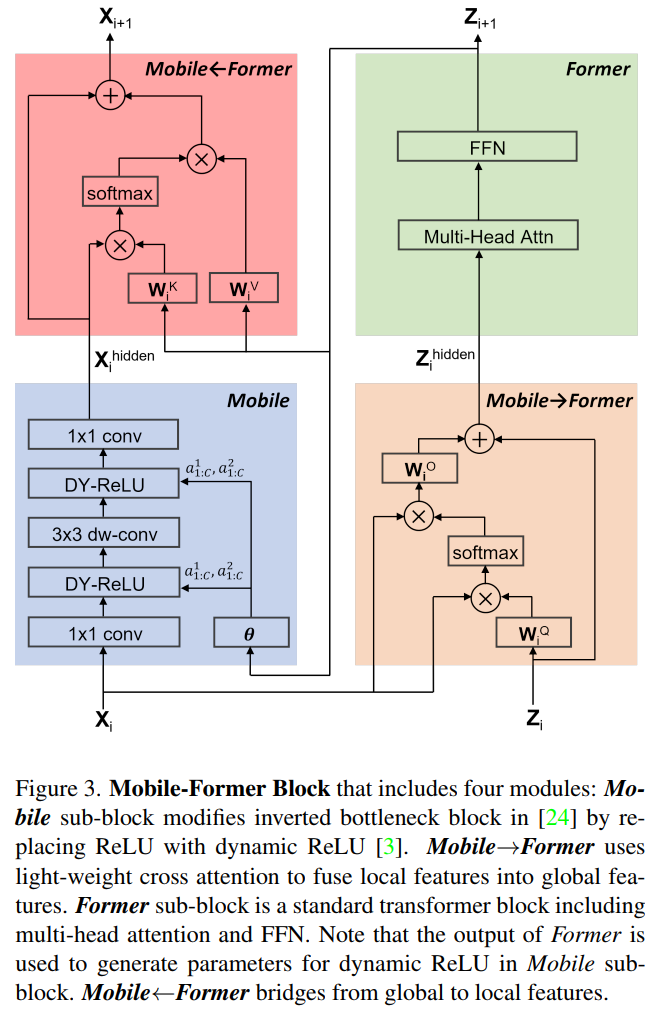
图3
1 输入和输出
Mobile-Former块有2个输入:
局部特征图
,具有C通道和L空间位置(L=hw,其中h和w为特征图的高度和宽度);
全局token
,其中M和d分别是token的数量和维数。
Mobile-Former块输出更新后的局部特征映射为
和全局token
,用作下一个(i+1)块的输入。注意,全局token的数量和维度在所有块中都是相同的。
2 Mobile sub-block
Mobile sub-block以feature map
为输入。与MobileNet中的inverted bottleneck block略有不同,在第一次pointwise卷积和
深度卷积后用dynamic ReLU代替ReLU作为激活函数。
与原来的dynamic ReLU不同,在平均池化特征上使用两个MLP层生成参数,而在前者输出的第一个全局token上使用2个MLP层(图3中的θ)保存平均池化。注意,对于所有块,深度卷积的核大小是
。将Mobile sub-block的输出表示为
,作为Mobile Former的输入(见图3),其计算复杂度为O(2LEC^2 + 9LEC),其中L为空间位置数,E为通道展开比,C为展开前通道数。
3 Former sub-block
Former sub-block是带有多头注意(MHA)和前馈网络(FFN)的标准transform block。在这里,作者遵循ViT使用后层标准化。为了节省计算,作者在FFN中使用的扩展比为2而不是4。
Former sub-block之间处理是双向交叉注意力,即(Mobile
Former和Mobile
Former)(见图3)。其复杂性为O(M^2d + Md^2)。第1项涉及到计算query和key的点积,以及根据注意力值聚合值。第2项涉及到线性投影和FFN。由于Former只有几个token(m6),所以第1项M^2d是可以忽略的。
4 Mobile
Former
采用所提出的轻量cross attention(式1)将局部特征
融合到全局token
。与标准自注意力相比去掉了key
和value
(在局部特征上)的投影矩阵,以节省计算量(如图3所示)。其计算复杂度为O(LMC + MdC),其中第1项涉及计算局部特征和全局特征之间的cross attention以及为每个全局token聚合局部特征,第2项是将全局特征投影到局部特征C的同一维度并在聚合后返回到维度d的复杂性。
5 Mobile
Former
在这里cross attention(公式3)位于移动方向的相反方向。它融合了全局token
和局部特征
。局部特征
是query,全局token
是key和value。因此,保留key
和value的投影矩阵
,但在query
时去掉投影矩阵以节省计算,如图3所示。计算复杂度为O(LMC + MdC)。
6 计算复杂度
Mobile-Former块的4个支柱有不同的计算成本。Mobile sub-block消耗的计算量最多(O(2LEC^2 + 9LEC)),它与空间位置数L呈线性增长,与局部特征c中通道数呈二次增长。Former sub-block和双向Bridge具有较高的计算效率,消耗小于所有Mobile-Former模型总计算量的20%。
3.3 网络配置说明
1 架构
表1显示了在294M FLOPs上的Mobile-Former架构,它以不同的输入分辨率堆叠11个Mobile-Former块。所有Mobile-Former区块都有6个维度为192的全局token。它以
卷积作为stem开始,随后是lite bottleneck block在stage-1。lite bottleneck block使用
深度卷积来扩展channel数量,并使用pointwise卷积来压缩channel数量。分类head对局部特征应用平均池化,与第一个全局token连接,然后通过2个完全连接的层(层之间使用h-swish)。
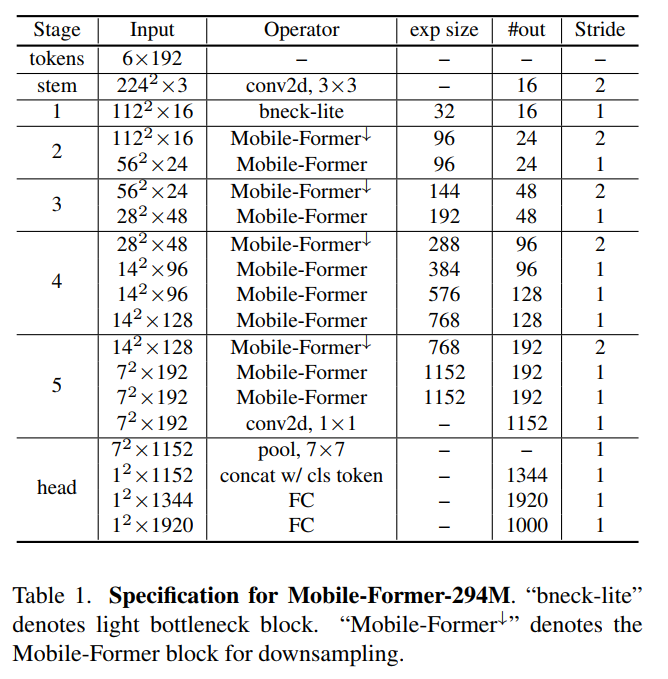
2 Downsample Mobile-Former Block
staget 2-5有一个Mobile-Former块的downsample变体(表示为Mobile-Former
)来处理空间下采样。在Mobile-former
中,只有Mobile sub block中的卷积层从3层(点向!深度向!点向)改变为4层(pointwise
depth
pointwise),其中第一个深度卷积层有stride=2。channel的数量在每个深度卷积中扩展,并压缩在接下来的pointwise卷积中。这节省了计算,因为2个代价高昂的pointwise卷积在下采样后以较低的分辨率执行。
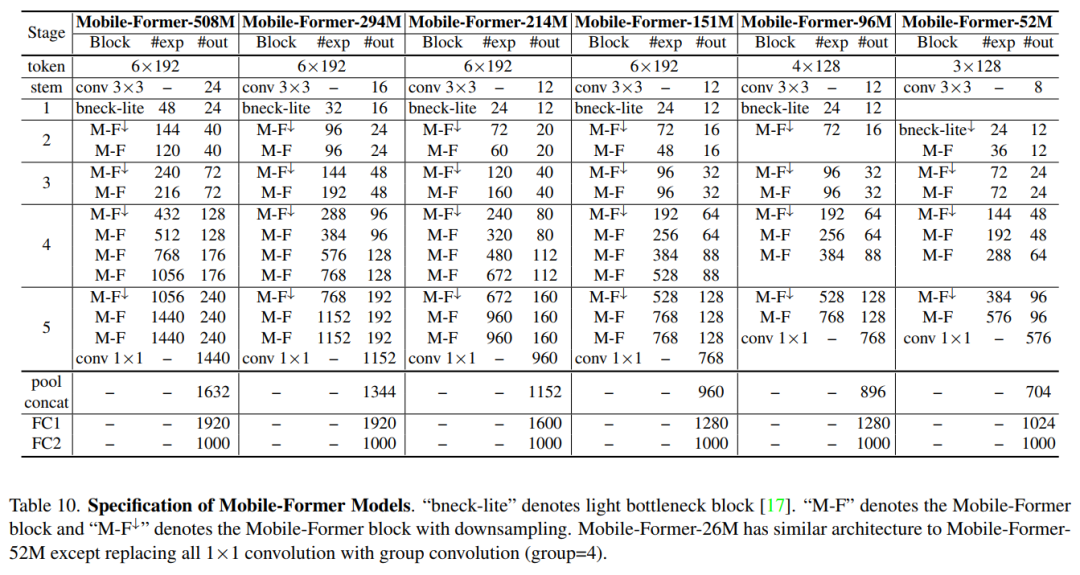
3 Mobile-Former变体
Mobile-Former有7个不同计算成本的模型,从26M到508M FLOPs。它们的结构相似,但宽度和高度不同。作者遵循[36]来引用我们的模型的FLOPs,例如Mobile-Former-294M, Mobile-Former-96M。这些Mobile-Former模型的网络架构细节如下表。
4Mobile-Former的可解释性
为了理解Mobile和Former之间的协作,作者将cross attention形象化在双向桥上(Mobile
Former和Mobile
Former)(见图4、5、6)。使用ImageNet预训练的MobileFormer-294M,其中包括6个全局token和11个Mobile-Former块。作者观察到3种有趣的现象:
第1点:
lower level token的注意力比higher level token更多样化。如图4所示,每一列对应一个token,每一行对应相应的多头交叉注意中的一个头。注意,在Mobile
Former(左半部分)中,注意力是在像素上标准化的,显示每个token的聚焦区域。相比之下,Mobile
Former中的注意力是在token上标准化的,比较不同token在每个像素上的贡献。显然,第3和第5区块的6个token在Mobile
Former和Mobile
Former中都有不同的cross attention模式。在第8块中可以清楚地观察到token之间类似的注意力模式。在第12区块,最后5个token的注意力模式非常相似。注意,第1个token是进入分类器头部的class token。最近关于ViT的研究也发现了类似的现象。

第2点:
全局token的重点区域从低到高级别逐渐变化。图5显示了Mobile
Former中第1个token的像素交叉注意力。这个token开始关注局部特性,例如边缘/角(在第2-4块)。然后对像素连通区域进行了更多的关注。有趣的是,聚焦区域在前景(人和马)和背景(草)之间转换。最后,定位识别度最高的区域(马身和马头)进行分类。

第3点:
Mobile
Former的中间层(例如第8块)出现了前景和背景的分离。图6显示了特征图中每个像素在6个token上的cross attention。显然,前景和背景被第一个token和最后一个token分开。这表明,一些全局token学习有意义的原型,聚类相似的像素。

局限性
Mobile-Former的主要限制是模型大小。这有2个原因:
首先,由于Mobile,Former和bridge都有各自的参数,因此并行设计在参数共享方面效率不高;虽然Former由于token数量少,计算效率高,但它并不节省参数的数量。
其次,在执行ImageNet分类任务时,Mobile-Former在分类头(2个全连接层)中消耗了很多参数。例如,Mobile-Former-294M在分类头中花费了40% (11.4M中的4.6M)参数。当从图像分类切换到目标检测任务时,由于去掉了分类头,模型大小问题得到了缓解。
5实验
5.1 ImageNet Classification
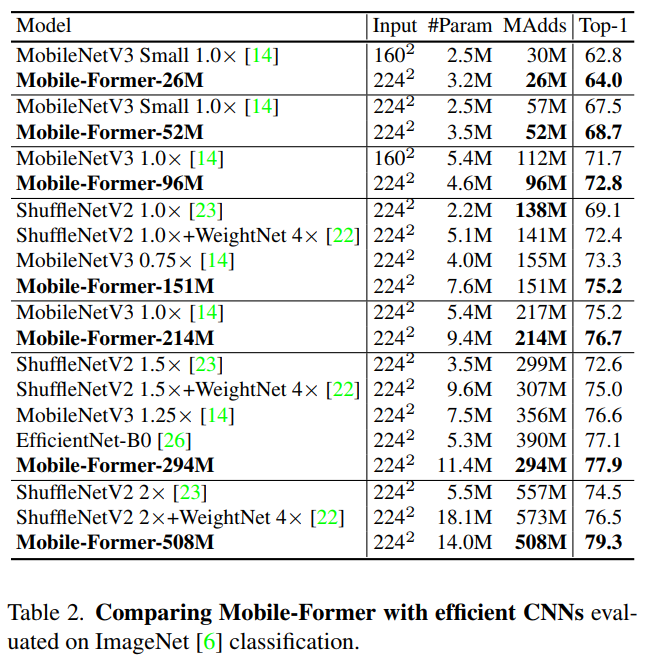
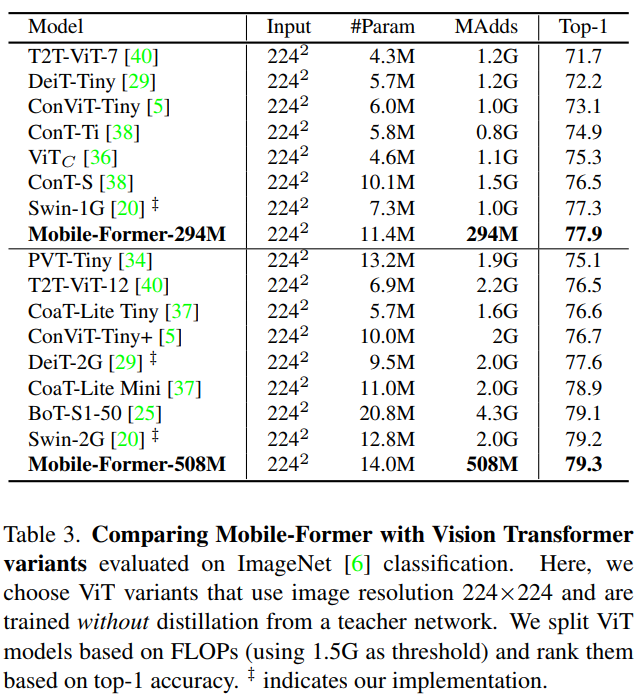
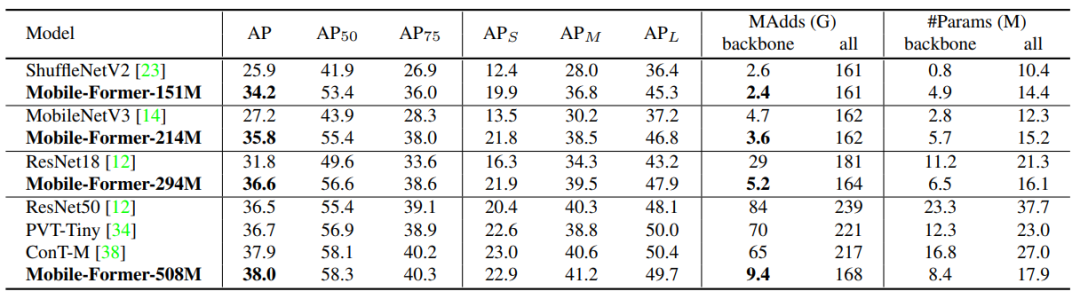
5.2 Object Detection
6参考
[1].Mobile-Former: Bridging MobileNet and Transformer
7推荐阅读
面向自动驾驶的点云处理技术总结(从理论到工业级部署)

牛津大学提出PSViT | Token池化+Attention Sharing让Transformer模型不在冗余!!!

YOffleNet | YOLO V4 基于嵌入式设备的轻量化改进设计
长按扫描下方二维码添加小助手并加入交流群,群里博士大佬云集,每日讨论话题有目标检测、语义分割、超分辨率、模型部署、数学基础知识、算法面试题分享的等等内容,当然也少不了搬砖人的扯犊子
长按扫描下方二维码添加小助手。
可以一起讨论遇到的问题
声明:转载请说明出处
扫描下方二维码关注【集智书童】公众号,获取更多实践项目源码和论文解读,非常期待你我的相遇,让我们以梦为马,砥砺前行!
