
【机器学习】在大数据上使用PySpark进行K-Means
编译 | VK
来源 | Towards Data Science

如果你不熟悉K Means聚类,我建议你阅读下面的文章。本文主要研究数据并行和聚类,大数据上的K-Means聚类。
https://towardsdatascience.com/unsupervised-learning-techniques-using-python-k-means-and-silhouette-score-for-clustering-d6dd1f30b660
关于聚类
聚类是一种无监督的学习技术,简而言之,你处理的是数据,没有任何关于目标属性或因变量的信息。
聚类的一般思想是在数据中发现一些内在的结构,通常被称为相似对象的簇。该算法研究数据以识别这些簇,使得簇中的每个成员更接近簇中的另一个成员(较低的簇内距离),而远离不同簇中的另一个成员(较高的簇间距离)。
聚类适合哪里?
你们大多数人都熟悉现实生活中的这些例子:
客户细分-广泛用于目标营销 图像分割-识别景观 推荐引擎
背景
K-Means聚类,使用欧氏距离形式的相似性度量,通常被称为分裂聚类或分区聚类。
K均值的基本思想是从每个数据点都属于一个簇,然后根据用户输入K(或聚类数)将它们分成更小的簇。每个簇都有一个称为质心的中心。质心总数总是等于K。该算法迭代地寻找数据点并将它们分配给最近的簇。
一旦所有数据点被分配到各自的质心(这里代表每个簇),质心值将被重新计算,过程将重复,直到簇达到收敛标准。
质心只不过是每个簇的新平均值(例如,由客户A、B、C组成的簇,平均支出为100、200、300,篮子大小为10、15和20,质心分别为200和15)。收敛准则是衡量簇的稳定性的一个指标,即任意两次迭代之间的簇内距离在给定的阈值范围内不变。
Pypark有什么不同吗
在我们讨论为什么PySpark不是基于Sklearn的算法之前,让我们先讨论一下PySpark中的过程有什么不同。
在使用PySpark构建任何聚类算法时,都需要执行一些数据转换。让我们先理解数据,用于分析的数据可以在这里找到。
https://www.kaggle.com/arjunbhasin2013/ccdata
数据
该数据集由超过6个月的9K名活跃信用卡持卡人及其交易和账户属性组成。其想法是制定一个客户细分的营销策略。

使用Pypark
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName(‘Clustering using K-Means’).getOrCreate()
data_customer=spark.read.csv('CC General.csv', header=True, inferSchema=True)
data_customer.printSchema()

属性可以分为三大类。客户信息(主键为CUST_ID)、帐户信息(余额、余额频率、购买、信用额度、使用期限等)和交易(购买频率、付款、预付现金等)。
data_customer=data_customer.na.drop()
所考虑的所有属性都是数字或离散数字,因此我们需要使用向量汇编器(Vector Assembler)将它们转换为特征。向量汇编器是一种转换器,它将一组特征转换为单个向量列,通常称为特征数组,这里的特征是列。
customer id不会用于聚类。我们首先使用.columns提取所需的列,将其作为输入传递给Vector Assembler,然后使用transform将输入列转换为一个称为feature的向量列。
from pyspark.ml.feature import VectorAssembler
data_customer.columns
assemble=VectorAssembler(inputCols=[
'BALANCE',
'BALANCE_FREQUENCY',
'PURCHASES',
'ONEOFF_PURCHASES',
'INSTALLMENTS_PURCHASES',
'CASH_ADVANCE',
'PURCHASES_FREQUENCY',
'ONEOFF_PURCHASES_FREQUENCY',
'PURCHASES_INSTALLMENTS_FREQUENCY',
'CASH_ADVANCE_FREQUENCY',
'CASH_ADVANCE_TRX',
'PURCHASES_TRX',
'CREDIT_LIMIT',
'PAYMENTS',
'MINIMUM_PAYMENTS',
'PRC_FULL_PAYMENT',
'TENURE'], outputCol='features')
assembled_data=assemble.transform(data_customer)
assembled_data.show(2)

既然所有的列都被转换成一个单一的特征向量,我们就需要对数据进行标准化,使它们具有可比的规模。例如,BALANCE可以是10-1000,而BALANCE_FREQUENCY可以是0-1。
欧几里德距离总是在大尺度上受到更大的影响,因此对变量进行标准化是非常重要的。
from pyspark.ml.feature import StandardScaler
scale=StandardScaler(inputCol='features',outputCol='standardized')
data_scale=scale.fit(assembled_data)
data_scale_output=data_scale.transform(assembled_data)
data_scale_output.show(2)
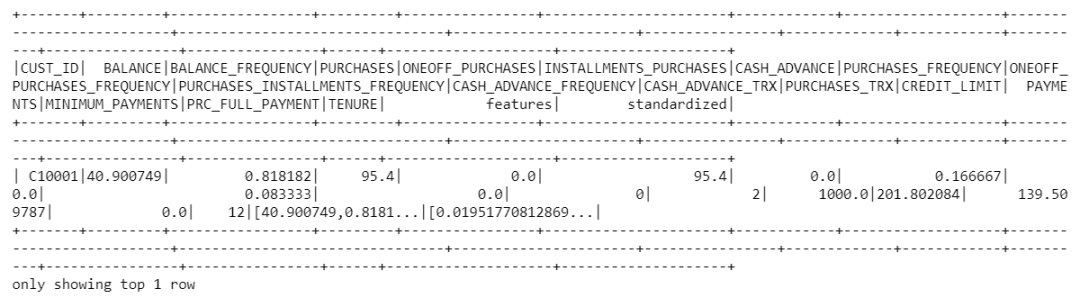
既然我们的数据已经标准化了,我们就可以开发K均值算法了。
K-means是最常用的聚类算法之一,用于将数据分簇到预定义数量的聚类中。
spark.mllib包括k-means++方法的一个并行化变体,称为kmeans||。KMeans函数来自pyspark.ml.clustering,包括以下参数:
k是用户指定的簇数 maxIterations是聚类算法停止之前的最大迭代次数。请注意,如果簇内距离的变化不超过上面提到的epsilon值,迭代将停止,而不考虑最大迭代次数 initializationMode指定质心的随机初始化或通过k-means||初始化(类似于k-means++) epsilon决定k-均值收敛的距离阈值 initialModel是一簇可选的群集质心,用户可以将其作为输入提供。如果使用此参数,算法只运行一次,将点分配到最近的质心
train(k=4, maxIterations=20, minDivisibleClusterSize=1.0, seed=-1888008604)是默认值。
from pyspark.ml.clustering import KMeans
from pyspark.ml.evaluation import ClusteringEvaluator
silhouette_score=[]
evaluator = ClusteringEvaluator(predictionCol='prediction', featuresCol='standardized', \
metricName='silhouette', distanceMeasure='squaredEuclidean')
for i in range(2,10):
KMeans_algo=KMeans(featuresCol='standardized', k=i)
KMeans_fit=KMeans_algo.fit(data_scale_output)
output=KMeans_fit.transform(data_scale_output)
score=evaluator.evaluate(output)
silhouette_score.append(score)
print("Silhouette Score:",score)
可视化分数。注意,以前版本的K Means有computeScore,它计算聚类内距离的总和,但在spark3.0.0中被弃用。
轮廓分数使用ClusteringEvaluator,它测量一个簇中的每个点与相邻簇中的点的接近程度,从而帮助判断簇是否紧凑且间隔良好
# 可视化轮廓分数
import matplotlib.pyplot as plt
fig, ax = plt.subplots(1,1, figsize =(8,6))
ax.plot(range(2,10),silhouette_score)
ax.set_xlabel(‘k’)
ax.set_ylabel(‘cost’)
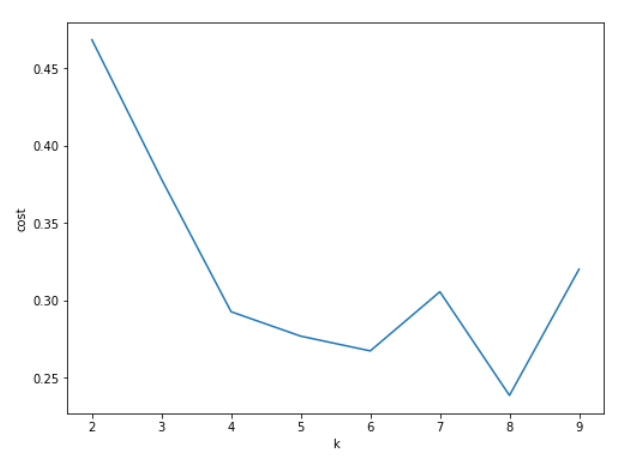
我更喜欢用K=7,在那里可以观察到轮廓分数的局部最大值。什么值的K是好的没有正确的答案。
我们可以使用描述性统计和其他图表来检查,这点在SkLearn和PCA上实现更方便。我们中的大多数人更喜欢研究肘部图,而不是轮廓分数,但PySpark有它的优点。
为什么是Pypark?
PySpark在执行K均值聚类时使用数据并行或结果并行的概念。
假设你需要为墨尔本节礼日活动开展有针对性的营销活动,并且你希望接触到具有不同购买属性的20万客户。想象一下在本地系统上运行K Means的多次迭代。对于K=5,需要计算的距离度量数为5 x 200K=1百万。100万个这样的度量需要计算30次才能满足收敛标准,即3000万个距离(欧几里德距离)。处理这样的场景需要大量的计算能力和时间。
数据并行性
数据并行所做的是,通过将数据集划分为更小的分区,从一开始就创建并行性。另一方面,结果并行是基于目标聚类的。例如:
D=记录数{X1,X2,…,Xn}
k=簇数
P=处理器数{P1,P2,…,Pm}
C=初始质心{C1,C2,…,Ck}
数据D被P个处理器分割。每个处理器处理一簇记录(由spark配置决定)。初始质心值C在每个处理器之间共享 现在每个处理器都有质心信息。处理器计算它们的记录到这些质心的距离,并通过将数据点分配到最近的质心来形成局部聚类 完成步骤2后,主进程将存储P个处理器上每个聚类的记录总数和计数,以供将来参考 一旦一次迭代完成,来自处理器的信息被交换,主进程计算更新的质心并再次在P个处理器之间共享它们,即,主进程更新质心,并与处理器重新共享信息 这个过程不断迭代直到收敛。一旦满足收敛条件,主进程就收集本地簇并将它们组合成一个全局聚类
想象一下,将20万条记录分成3个处理器,每个处理器有约70万条记录。这就是分布式处理的用武之地,以减少数据量,同时确保完整的结果。
结果并行性
例如:
D=记录数{X1,X2,…,Xn}
k=簇数
P=处理器数{P1,P2,…,Pm}
C=初始质心{C1,C2,…,Ck}
数据D被P个处理器分割,然后在每个处理器内排序。每个处理器处理一组记录(由spark配置决定) 初始质心值C被初始化,并在这些处理器中的每一个处理器之间进行分割/共享(即,与所有质心值在所有处理器之间共享的数据并行性不同,这里,我们将一个质心值传递给一个处理器) 现在每个处理器都有一个中心。计算这些点到这些质心的距离。对于处理器中的数据点:如果它们更接近处理器的质心,则将它们分配给该簇,否则如果它们更接近属于其他处理器的质心,则将数据点移动到新处理器 重复,直到收敛。
有用的链接
https://spark.apache.org/docs/latest/mllib-clustering.html https://spark.apache.org/docs/latest/api/python/pyspark.mllib.html#pyspark.mllib.clustering.KMeansModel https://spark.apache.org/docs/latest/api/python/pyspark.ml.html#pyspark.ml.evaluation.ClusteringEvaluator https://spark.apache.org/docs/latest/api/python/_modules/pyspark/ml/evaluation.html
感谢阅读。
往期精彩回顾
本站qq群851320808,加入微信群请扫码: