
Flink+Alink,当大数据遇见机器学习!
👆关注“博文视点Broadview”,获取更多书讯

以下内容节选自《Flink实战派》一书!

--正文--
大数据技术和人工智能(机器学习)的结合,使利用数据价值的技术有了新的突破。
在通常情况下,大数据技术与机器学习是互相促进、相依相存的关系。
01
大数据和机器学习之间的关系
机器学习不仅需要合理、适用和先进的算法,还需要依赖足够好和足够多的数据。
大数据可以提高机器学习模型的精确性。
数据的数据量越多,质量越高,机器学习的效率和准确性就越高。机器学习是大数据分析的一个重要方向(方式)。
大数据技术深度结合人工智能将是未来发展的一个重要方向。
大数据实时计算框架Flink结合基于Flink的机器学习库Alink,是目前非常优秀的“大数据+人工智能”解决方案。
Flink可以为Alink提供数据预处理、特征识别、样本计算和模型训练等基础功能。
Alink基于Flink,可以为Flink提供机器学习算法库。
Flink还可以和目前主流的人工智能框架(如PyTorch、TensorFlow、Kubeflow)结合。
02
Flink是什么?
业界认为,Flink是最好的数据流计算引擎。
为了便于理解Flink是什么,下面以迭代的方法进行定义。
Flink是一个开源的分布式大数据处理引擎与计算框架。
Flink是一个对无界数据流和有界数据流进行统一处理的、开源的分布式大数据处理引擎与计算框架。
Flink是一个能进行有状态或无状态计算的、对无界数据流和有界数据流进行统一处理且开源的分布式大数据处理引擎与计算框架。
Flink可以进行的数据处理包括实时数据处理、特征工程、历史数据(有界数据)处理、连续数据管道应用、机器学习、图表分析、图计算、容错的数据流处理。
Flink在大数据架构中的位置如下图所示。
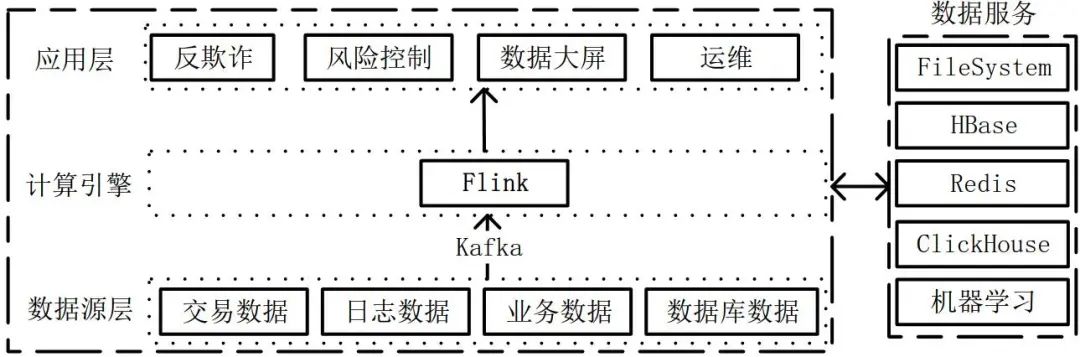
由上图可以看出,在大数据架构中,Flink用于提供数据计算服务。
Flink先获取数据源的数据,然后进行转换和计算等,最后输出计算结果。
03
Flink的应用场景
Flink的应用场景如下。
事件驱动:利用到来的事件触发计算、状态更新或其他外部动作。比如反欺诈、实时风险控制、异常检测、基于规则的报警、业务流程监控、Web应用。
数据分析:从原始数据中提取有价值的信息和指标。比如电信网络质量监控、移动应用中的产品更新及实验评估和分析、实时数据即席分析、大规模图分析。
数据管道:数据管道和ETL(提取、转换、加载)作业的用途相似,都可以转换、丰富数据,并将其从某个存储系统移动到另一个存储系统中。但数据管道是以持续流模式运行的,而非周期性触发。比如实时查询索引构建、持续ETL作业。
04
认识Alink
Alink是阿里巴巴计算平台事业部PAI团队研发的基于Flink的机器学习框架。
Alink于2019年11月正式开源。
Alink提供了丰富的算法组件,是业界首个同时支持批/流算法的机器学习框架。
开发者利用Alink可以一键搭建覆盖数据处理、特征工程、模型训练、模型预测的算法模型开发的全流程。Alink的名称取自相关名称(Alibaba、Algorithm、AI、Flink、Blink)的结合。
05
Flink的整体架构
Flink包含部署层、执行引擎层、核心API层和领域库层。下图是Flink 1.11版本架构所包含的组件。
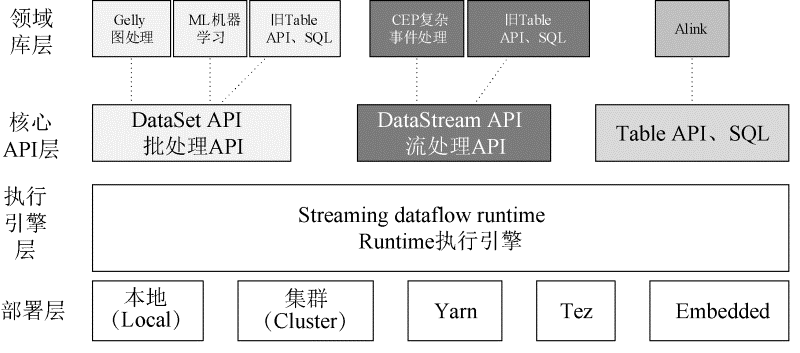
(1)部署层
Flink支持本地(Local)模式、集群(Cluster)模式等。
(2)执行引擎层
执行引擎层是核心API的底层实现,位于最低层。执行引擎层提供了支持Flink计算的全部核心实现。
执行引擎层的主要功能如下。
分布式流处理。
从作业图(JobGraph)到执行图(ExecutionGraph)的映射、调度等。
为上层的API层提供基础服务。
构建新的组件或算子。
执行引擎层的特点包括以下几点:灵活性高,但开发比较复杂;表达性强,可以操作状态、Time等。
(3)核心API层
核心API层主要对无界数据流和有界数据流进行处理,包括DataStream API和DataSet API,以及实现了更加抽象但是表现力稍差的Table API、SQL。
DataStream API:用于处理无界数据,或者以流处理方式来处理有界数据。
DataSet API:用于对有界数据进行批处理。用户可以非常方便地使用Flink提供的各种算子对分布式数据集进行处理。DataStream API和DataSet API是流处理应用程序和批处理应用程序的接口,程序在编译时生成作业图。在编译完成之后,Flink的优化器会生成不同的执行计划。根据部署方式的不同,优化之后的作业图将被提交给执行器执行。
Table API、SQL:用于对结构化数据进行查询,将结构化数据抽象成关系表,然后通过其提供的类SQL语言的DSL对关系表进行各种查询。
(4) 领域库层
Flink还提供了用于特定领域的库,这些库通常被嵌入在API中,但不完全独立于API。这些库也因此可以继承API的所有特性,并与其他库集成。
在API层之上构建的满足特定应用的实现计算框架(库),分别对应面向流处理和面向批处理这两类。
面向流处理支持:CEP(复杂事件处理)、基于SQL-like的操作(基于Table的关系操作)。
面向批处理支持:FlinkML(机器学习库)、Alink(新开源的机器学习库)、Gelly(图计算)。

▼
更多实战派,给你一样的精彩!


▊《Flink实战派》
龙中华 著
版本较新:针对Flink 1.11版本和Alink 1.2版本。
体例科学:采用“知识点+实例”的形式编写。
实例丰富:47个基础实例 + 1个项目实例。
跨界整合:①讲解了4种开发Flink应用程序的API,即DataSet API、DataStream API、Table API和SQL相关知识;②讲解了状态处理器API、复杂事件处理库,以及常用的消息中间件Kafka;③讲解了大数据和人工智能的结合,以及机器学习框架Alink。
编排讲究:本书涉及的术语尽量做到有迹可循,每一个术语都尽可能在前面的章节中有所描述。章节递进关系清楚,内容顺序合理,从头到尾逻辑连贯。
(京东限时活动,快快扫码抢购吧!)
如果喜欢本文 欢迎 在看丨留言丨分享至朋友圈 三连 热文推荐
▼点击阅读原文,查看本书详情~