
超详细图解Self-Attention的那些事儿

来源:NewBeenNLP 本文约3000字,建议阅读6分钟
本文教你OKV矩阵轻松理解。
向量的内积是什么,如何计算,最重要的,其几何意义是什么?
一个矩阵
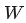 与其自身的转置相乘,得到的结果有什么意义?
与其自身的转置相乘,得到的结果有什么意义?
1. 键值对注意力
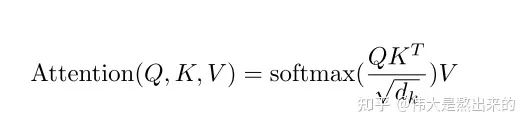
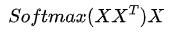
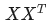 代表什么?
代表什么?
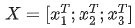 ,其中X 为一个二维矩阵,
,其中X 为一个二维矩阵, 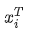 为一个行向量(其实很多教材都默认向量是列向量,为了方便举例请读者理解笔者使用行向量)。对应下面的图,对应"早"字embedding之后的结果,以此类推。
为一个行向量(其实很多教材都默认向量是列向量,为了方便举例请读者理解笔者使用行向量)。对应下面的图,对应"早"字embedding之后的结果,以此类推。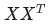 。我们来看看其结果究竟有什么意义
。我们来看看其结果究竟有什么意义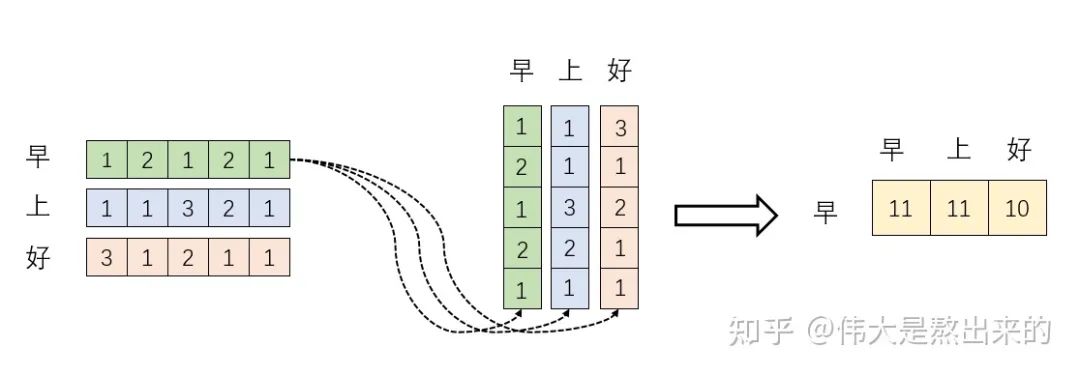 分别与自己和其他两个行向量做内积("早"分别与"上""好"计算内积),得到了一个新的向量。我们回想前文提到的向量的内积表征两个向量的夹角,表征一个向量在另一个向量上的投影。那么新的向量向量有什么意义的?是行向量在自己和其他两个行向量上的投影。我们思考,投影的值大有什么意思?投影的值小又如何?
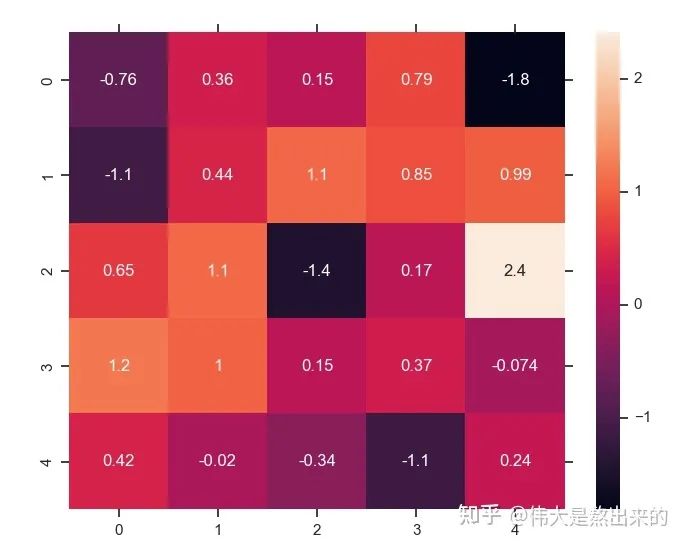
分别与自己和其他两个行向量做内积("早"分别与"上""好"计算内积),得到了一个新的向量。我们回想前文提到的向量的内积表征两个向量的夹角,表征一个向量在另一个向量上的投影。那么新的向量向量有什么意义的?是行向量在自己和其他两个行向量上的投影。我们思考,投影的值大有什么意思?投影的值小又如何?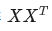 的意义是什么呢? 是一个方阵,我们以行向量的角度理解,里面保存了每个向量与自己和其他向量进行内积运算的结果。
的意义是什么呢? 是一个方阵,我们以行向量的角度理解,里面保存了每个向量与自己和其他向量进行内积运算的结果。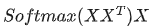 中,的意义。我们进一步,Softmax的意义何在呢?请看下图
中,的意义。我们进一步,Softmax的意义何在呢?请看下图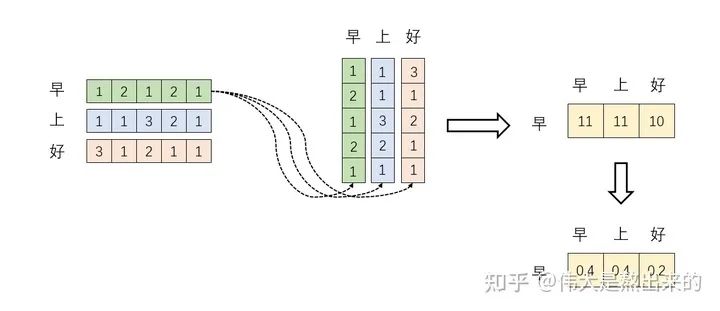
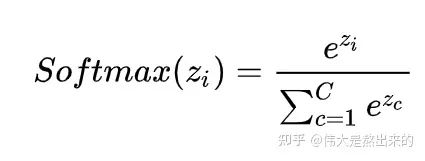
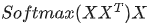 已经理解了其中的一半。最后一个 X 有什么意义?完整的公式究竟表示什么?我们继续之前的计算,请看下图
已经理解了其中的一半。最后一个 X 有什么意义?完整的公式究竟表示什么?我们继续之前的计算,请看下图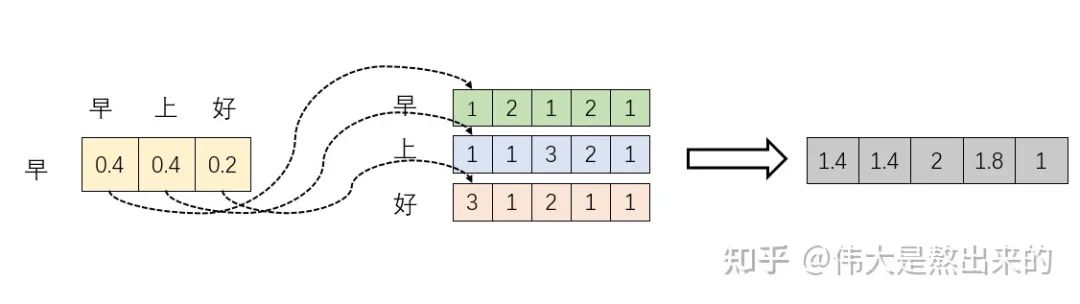
的一个行向量举例。这一行向量与X的一个列向量相乘,表示什么?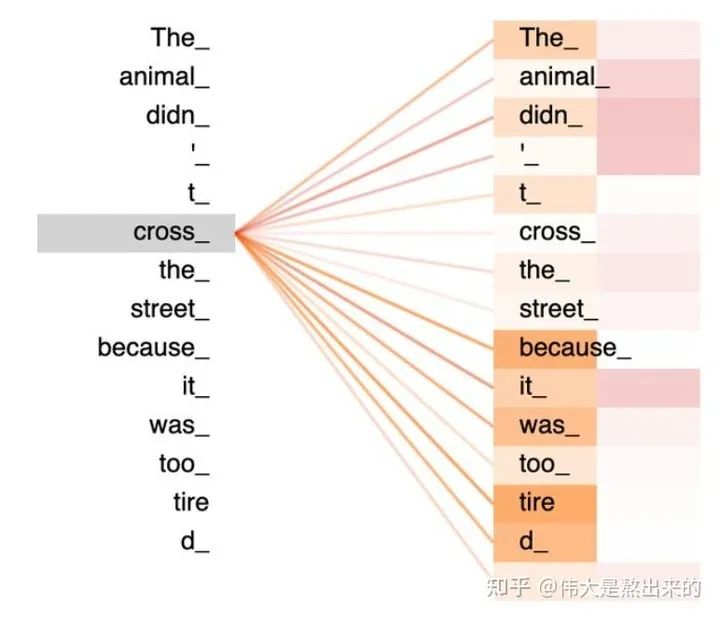
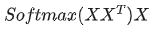 已经有了更深刻的理解。
已经有了更深刻的理解。2. Q K V矩阵
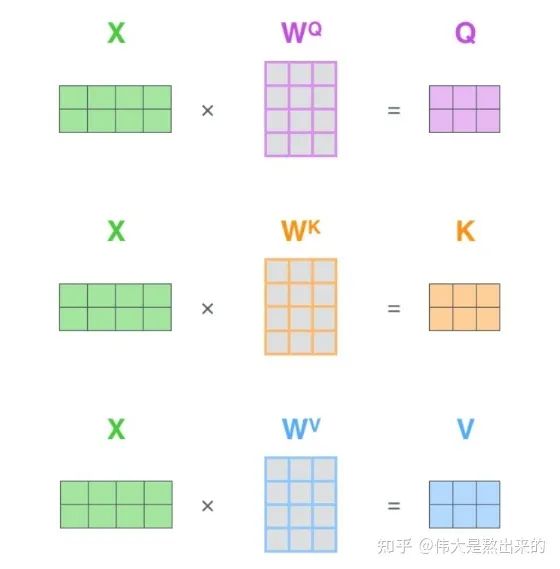
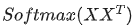 这个矩阵的意义,相信你也理解了所谓查询向量一类字眼的含义。
这个矩阵的意义,相信你也理解了所谓查询向量一类字眼的含义。3. 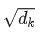 的意义
的意义
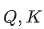 里的元素的均值为0,方差为1,那么
里的元素的均值为0,方差为1,那么 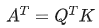 中元素的均值为0,方差为d. 当d变得很大时,A中的元素的方差也会变得很大,如果 A中的元素方差很大,那么
中元素的均值为0,方差为d. 当d变得很大时,A中的元素的方差也会变得很大,如果 A中的元素方差很大,那么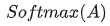 的分布会趋于陡峭(分布的方差大,分布集中在绝对值大的区域)。总结一下就是的分布会和d有关。因此 A中每一个元素除以后,方差又变为1。这使得的分布“陡峭”程度与d解耦,从而使得训练过程中梯度值保持稳定。
的分布会趋于陡峭(分布的方差大,分布集中在绝对值大的区域)。总结一下就是的分布会和d有关。因此 A中每一个元素除以后,方差又变为1。这使得的分布“陡峭”程度与d解耦,从而使得训练过程中梯度值保持稳定。# Muti-head Attention 机制的实现from math import sqrtimport torchimport torch.nnclass Self_Attention(nn.Module):# input : batch_size * seq_len * input_dim# q : batch_size * input_dim * dim_k# k : batch_size * input_dim * dim_k# v : batch_size * input_dim * dim_vdef __init__(self,input_dim,dim_k,dim_v):super(Self_Attention,self).__init__()self.q = nn.Linear(input_dim,dim_k)self.k = nn.Linear(input_dim,dim_k)self.v = nn.Linear(input_dim,dim_v)self._norm_fact = 1 / sqrt(dim_k)def forward(self,x):Q = self.q(x) # Q: batch_size * seq_len * dim_kK = self.k(x) # K: batch_size * seq_len * dim_kV = self.v(x) # V: batch_size * seq_len * dim_vatten = nn.Softmax(dim=-1)(torch.bmm(Q,K.permute(0,2,1))) * self._norm_fact # Q * K.T() # batch_size * seq_len * seq_lenoutput = torch.bmm(atten,V) # Q * K.T() * V # batch_size * seq_len * dim_vreturn output

# Muti-head Attention 机制的实现from math import sqrtimport torchimport torch.nnclass Self_Attention_Muti_Head(nn.Module):# input : batch_size * seq_len * input_dim# q : batch_size * input_dim * dim_k# k : batch_size * input_dim * dim_k# v : batch_size * input_dim * dim_vdef __init__(self,input_dim,dim_k,dim_v,nums_head):super(Self_Attention_Muti_Head,self).__init__()assert dim_k % nums_head == 0assert dim_v % nums_head == 0self.q = nn.Linear(input_dim,dim_k)self.k = nn.Linear(input_dim,dim_k)self.v = nn.Linear(input_dim,dim_v)self.nums_head = nums_headself.dim_k = dim_kself.dim_v = dim_vself._norm_fact = 1 / sqrt(dim_k)def forward(self,x):Q = self.q(x).reshape(-1,x.shape[0],x.shape[1],self.dim_k // self.nums_head)K = self.k(x).reshape(-1,x.shape[0],x.shape[1],self.dim_k // self.nums_head)V = self.v(x).reshape(-1,x.shape[0],x.shape[1],self.dim_v // self.nums_head)print(x.shape)print(Q.size())atten = nn.Softmax(dim=-1)(torch.matmul(Q,K.permute(0,1,3,2))) # Q * K.T() # batch_size * seq_len * seq_lenoutput = torch.matmul(atten,V).reshape(x.shape[0],x.shape[1],-1) # Q * K.T() * V # batch_size * seq_len * dim_vreturn output
评论