
【从零开始学深度学习编译器】十,TVM的整体把握
0x0. 前言
大概4个月前开始接触TVM,虽然是0经验开始看,但目前对TVM的IR以及Pass,Codegen,Scheduler等也有了一些基础的认识。所以这篇文章的目的是梳理一下TVM的整体架构,复盘一下自己学到了什么,以及为想学习TVM的小伙伴们提供一个整体思路。「从零开始学深度学习编译器」这个专题的文章和实验代码都被我汇总放到了https://github.com/BBuf/tvm_learn这个仓库中,当然是希望「大力点一下Star了」,感激不尽。仓库目录如下:

0x1. TVM的整体架构
首先看一下TVM的完整架构图,然后照着这个架构图来说明。
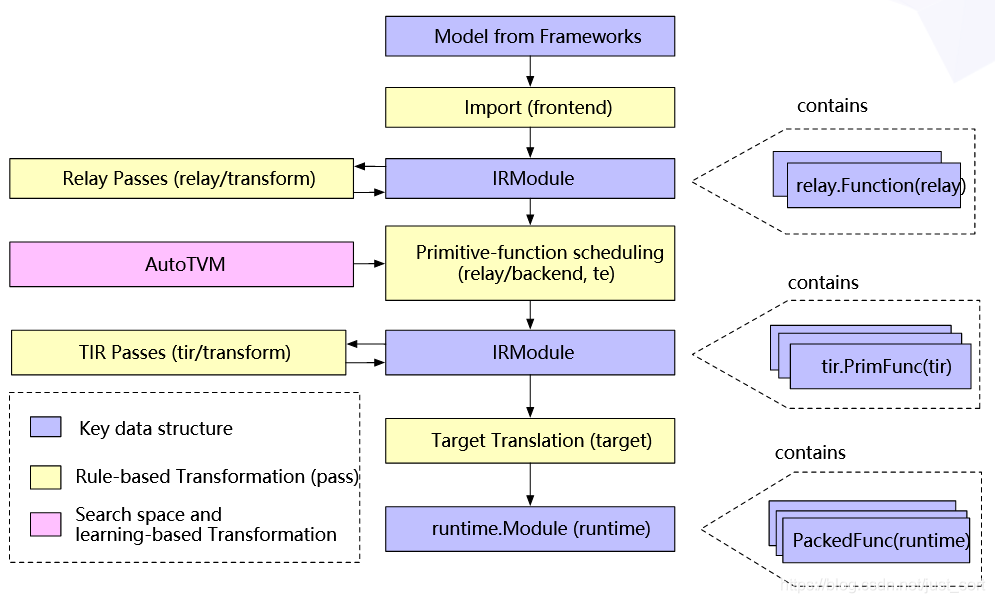
最上层的Model from Frameworks以及Import(fronted)就是我们之前讲过的将各种深度学习框架的计算图转换为Relay IR,即【从零开始学TVM】三,基于ONNX模型结构了解TVM的前端 中讲到的。然后我们可以看到TVM中的IR分为两层,上层是面向前端的Relay IR,下层是面向LLVM的底层IR(也可以叫Tir)。
虽然TVM从设计上抽象了Relay IR和Tir两个层次,但是从实现上来讲,它们底层都是借助Object元类实现统一的AST Node表示,并借助IRModule来贯穿上下层的IR表示。这一点我们可以从include/tvm/ir/module.h对IRModuleNode的定义中发现:
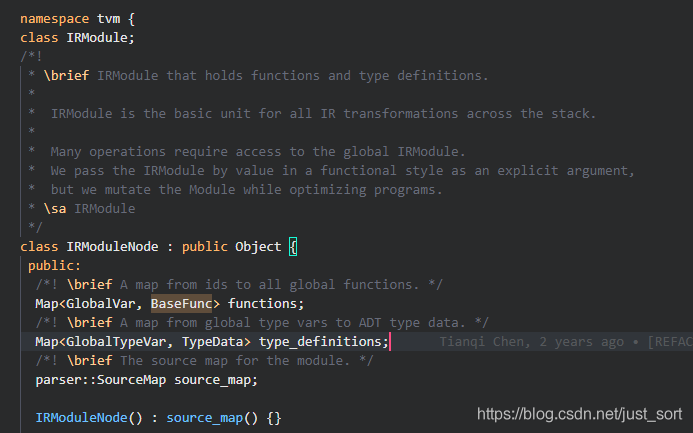
之前在【从零开始学深度学习编译器】七,万字长文入门TVM Pass中讲解Relay AST树结构的时候提到过在include/tvm/relay/expr.h这里定义了Relay表达式树的节点,有ConstantNode、VarNode、TupleNode、CallNode、LetNode、IfNode等等。这些节点实际上都继承了ExprNode这个统一节点表示类,而这个类也是从Object类派生出来的。所以虽然TVM抽象了两个层次的IR,但实际实现上有共同之处,并非是两种单独存在的IR。
接下来,简要介绍一下架构图中的关键组成部分:
这个图结构里面有两种「关键节点」。一是
Import,这是TVM的前端组件将各种深度学习框架的模型导入到TVM的IRModule中。二是Transform,可以将一个IRModule等价转换成另外一个功能相同的IRModule,达到优化的效果,并且这种转换可以分为独立于硬件存在以及和硬件相关的两种。IRModule:它是functions的集合,其中包含两种最关键的Function集合,即relay::Function和tir::PrimFuc。上层
relay::Function继承自BaseFunction,relay::Function对应一个end2end的模型,可以理解为一个支持控制流,递归,以及复杂数据结构的计算图。下层
tir::PrimFunc也继承自BaseFunction,tir::PrimFunc包含了一些底层threading,vector/tensor的指令。通常为模型中的一个OP执行单元。Target Translation编译器将IRModule变换为目标硬件上可执行的格式(即代码生成),生成的代码被封装为运行时。Passes:pass是对计算图的一些优化和转换,比如常量折叠,算符融合,死代码消除等等。在编译阶段,一个
relay::Function可能会被lower成多个tir::PrimFunc。
这里以一个例子来直观了解一下IRModule长什么样子:
import tvm
from tvm import relay
import numpy as np
from tvm.contrib import graph_executor
# build model
n = 2
x = relay.var("x", shape=(n,), dtype='float32')
y = relay.nn.softmax(x)
net = relay.Function([x], y)
# build and lowering
module = tvm.IRModule.from_expr(net)
lib = relay.build(module, "llvm")
dev = tvm.cpu(0)
input = tvm.nd.array(np.random.uniform(size=[n]).astype('float32'), dev)
m = graph_executor.GraphModule(lib["default"](dev))
# set inputs
m.set_input("x", input)
# execute
m.run()
# get outputs
tvm_output = m.get_output(0)
print(module)
# def @main(%x: Tensor[(2), float32]) {
# nn.softmax(%x)
# }
我们再来看一下IR Transorform包含哪些内容。
Relay Transform
Relay的Transform就是我们之前介绍的TVM的硬件无关的Pass,例如常规的constant folding、dead-code elimination以及张量计算相关的一些特殊Pass如transformation,scaling factor folding。
在Relay优化pipline的后期,会运行一个FuseOps Pass来将一个端到端的funtion例如MobileNet切分成一些sub-function子段如conv2d-relu,这个感觉叫子图划分更好。
在跑完硬件无关的Pass之后,TVM会将relay::Function lower成多个tir::PrimFunc,然后针对每个tir::PrimFunc进行编译和优化。对于某些特殊的后端,也可以不走Tir,直接使用外部代码生成器生成目标后端代码。
在Relay/Backend层做运行结构的调用,会分成几种情况:
如果模型是静态shape,没有控制流,则lower到graph runtime。 如果模型是动态shape,有控制流,可以使用「virtual machine backend」 将来计划支持直接将子图级别的程序转换为executable and generated primitive functions的级别。
上述几种模式都会封装成一个统一的接口:runtime.Module。
Tir Transform
Tir Transform主要包含Tir级别的各种Pass,这部分的主要功能是lower,不过也有一些optimization。比如将访问多维数据扁平化为一维指针访问、针对特定的后端进行intrinsics扩展、或者根据运行时调用约定装饰函数(方便后续call);注意这个阶段保留了一些底层优化没有做,而是交给了下游的LLVM或者CUDA C编译器来进行,比如寄存器分配等等。
Relay的Pass是如何实现的
TVM的Pass是通过遍历AST,修改node来实现的,通过TVM_REGISTER_GLOBAL宏来注册和暴露支持的Pass。详细介绍可以看【从零开始学深度学习编译器】八,TVM的算符融合以及如何使用TVM Pass Infra自定义Pass 。对于开发者来说可能更关注如何自己新增一个Pass,TVM官方文档中给了一个常量折叠的例子。由于TVM的IR和AST类似,所以给TVM新增Pass主要包含以下步骤。
新增一个 AST Traversers,用来确定哪些node是需要修改的。在常量折叠中,实现了ConstantChecker,通过map结构的memo_记录哪些node是常量node。这个Pass只设计两个node的函数重载,即ConstantNode和TupleNode。新增一个 Expression Mutators,用于修改和替换满足条件的node。在常量折叠Pass中只有三种node涉及折叠,即LetNode,TupleItemNode和CallNode,因此需要重载这三个node的函数。
TVM的Pass设计思想和架构在【从零开始学深度学习编译器】七,万字长文入门TVM Pass 这里有讲到,其中还翻译了TVM Pass Infrastructure文档。TVM Pass整体上继承了许多LLVM Pass的设计思想,目标是实现如下效果:
可以灵活的排布pass,支持用户随意的定制pass pipeline。 提供友好的pass debug体验。 避免用户手动处理pass之间的依赖。 简化开发者新增pass的流程,支持在Python端自定义Pass。
TVM的Pass实现上可以分为Module Level Pass,Function Level Pass以及Sequential Level Pass。其中Module Level Pass基于全局信息进行优化,可以删减Function,如defuse_ops pass。Function Level Pass对Module中的每个Function进行优化,只有局部信息,例如公共子表达式消除。Sequential Pass顺序执行一系列的Pass。
AutoTVM
上面介绍的Pass都是确定性的变换,不管是哪种Pass还是IR lower。TVM的设计目标之一就是希望支持生成不同平台的高性能张量化代码,所以TVM采用了一种在scheduler形成的搜索空间中,使用机器学习算法找到最优化选择的方案。
TVM有许多典型的scheduler,感兴趣可以移步https://zhuanlan.zhihu.com/p/94846767 。基于这些小粒度的scheduler,TVM定义了一个程序变换可执行操作的集合,叫做调度原语(scheduling primitives),比如循环变化(split, unrool...),内联,向量化。这个阶段同时引入了target的概念,将一些target的特性考虑在内来进行搜索,比如target的寄存器可以同时处理多少个数据就决定了这部分代码向量化的行为。
接下来就是不断的跑程序,记录性能,调整调度选择,在最后执行程序时,对于某一段子图程序来说,将从log文件中选择最优的性能对应的调度方案来进行执行。
但TVM的搜索时间很长,并且在一些模型上不一定能取得好的效果,后来学者们提出了Ansor,缓解了搜索空间不足以及搜索时间过长的问题。感兴趣的小伙伴可以看一下我这篇对Ansor翻译和调研的文章Ansor论文阅读笔记&&论文翻译 。
Target Translation
这里时将Tir进一步转换为目标后端对应的可执行文件。对于X86和Arm CPU,TVM使用LLVM IR Builder在内存中构建llvm ir。还可以生成源代码级别的语言,比如生成CUDA C或者OpenCL的源码。另外还支持直接从Relay Function到特定后端的Codegen(这部分我还没使用过,感兴趣可以看看TVM源码的Codegen部分是怎么做的)。
Runtime Execution
在Runtime阶段主要有runtime.Module,runtime.PackedFunc以及runtime.NDArray三个核心元素。其中runtime.NDArray封装了执行期Tensor的结构,runtime.PackedFunc是后端生成的函数,类似于深度学习框架中的核函数,runtime.Module是封装编译DSO的核心单元,它包含了很多PackedFunc,可以根据name来获取。
我们在上面介绍IRModule长什么样子的示例中,通过lib["default"]加载这个runtime.Module的默认核函数,最后基于TVM的graph runtime机制来执行这个核函数获得推理结果。
0x2. TVM的Executor
上面最后一点提到了TVM的graph runtime,正好在这里介绍一下TVM的Executor。我们可以从tvm/python/tvm/relay/build_module.py这个文件中了解TVM执行期的几种模式:
def create_executor(kind="debug", mod=None, device=None, target="llvm"):
"""Factory function to create an executor.
Example
-------
.. code-block:: python
import tvm.relay
import numpy as np
x = tvm.relay.var("x", tvm.relay.TensorType([1], dtype="float32"))
expr = tvm.relay.add(x, tvm.relay.Constant(tvm.nd.array(np.array([1], dtype="float32"))))
tvm.relay.create_executor(
kind="vm", mod=tvm.IRModule.from_expr(tvm.relay.Function([x], expr))
).evaluate()(np.array([2], dtype="float32"))
# returns `array([3.], dtype=float32)`
Parameters
----------
kind : str
The type of executor. Avaliable options are `debug` for the
interpreter, `graph` for the graph executor, and `vm` for the virtual
machine.
mod : :py:class:`~tvm.IRModule`
The Relay module containing collection of functions
device : :py:class:`Device`
The device to execute the code.
target : :py:class:`tvm.Target`
The corresponding context
Returns
-------
executor : :py:class:`~tvm.relay.backend.interpreter.Executor`
"""
if mod is None:
mod = IRModule()
if device is not None:
assert device.device_type == _nd.device(str(target), 0).device_type
else:
device = _nd.device(str(target), 0)
if isinstance(target, str):
target = Target(target)
if kind == "debug":
return _interpreter.Interpreter(mod, device, target)
if kind == "graph":
return GraphExecutor(mod, device, target)
if kind == "vm":
return VMExecutor(mod, device, target)
raise RuntimeError("unknown execution strategy: {0}".format(kind))
从上面的代码中我们可以知道,Relay的解释器(interpreter)可以执行Relay的表达式,但是一般只用来debug。这是因为解释器是通过遍历AST来执行程序,而遍历的过程是十分低效的。另外基于解释器的执行模式无法友好的支持Dynamic Code。例如动态scheduler,动态Tensor shape,以及控制流。
考虑执行效率,TVM引入了graph runtime技术,提供了一种快速执行机制,但仅仅支持部分Relay程序,我理解指的是静态Tensor Shape以及没有控制流的程序。
为了解决动态Tensor shape和控制流的问题,TVM还抽象了一层Relay Virtual Machine Executor。具体解释可以看https://zhuanlan.zhihu.com/p/354995641。但是TVM的动态Tensor shape支持应该也只是支持了一些典型的推理场景,不支持训练。
0x3. TVM的组件
TVM中一些基础组件的交互图如下:
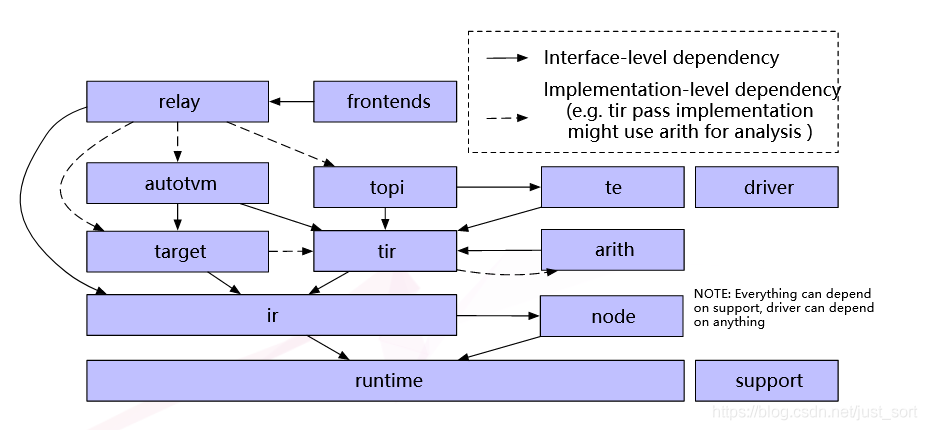
下面分别介绍一下这些组件:
Support:TVM的一些通用组件,比如socketing,logging等。 Frontends:TVM的前端,完成各种深度学习框架的计算图到Relay IR的转化。 Relay:这是一个high-level 计算图的描述,它有自己的IR表示,用这些IR表示来描述神经网络结构。上面介绍的一些硬件无关的Pass也是基于Relay IR完成的。 AutoTVM/Ansor:可选的自动调优模块。 Topi:这是一个Tensor计算库,里边包含了很多神经网络通用的算子,比如矩阵乘法,点乘,卷积等。我们可以通过这些topi算子来进行计算。 Tir:相对于Relay IR,这个层次的IR更接近底层和硬件实现。 Te:Te表示Tensor Expression,用户可以通过调用te中的函数来构建Tir。(这意味着TVM允许用户直接通过Te来写神经网络) Node:node是在IR的基础上增加了一些新的特性,可以允许用户对一些函数进行访问,这样就可以实现更复杂的表达函数。 Driver:基于硬件的驱动。 Arith:这个和Tir有关,可以在Tir优化时进行一些分析。 Runtime:runtime封装了图结构的转化,优化,代码生成,以及程序在硬件上的执行,为客户提供一个API接口完成所有的编译过程。
注意一下这个组件交互图中的箭头,「虚线箭头表示组件之间在实现level上有依赖,比如Tir pass在实现上必须依赖arith来分析。而实线箭头表示两个组件在前端level上有依赖关系」,比如Relay IR是依赖于Tir的,因为我们讲过Relay IR会被lower成Tir。
在前后端的交互上,TVM将所有的核心数据结构都暴露到了Python前端,这使得它具有足够的灵活性和易用性。具体体现为:
所有的核心对象都可以通过Python API直接构造和操作,比如IR Module。 支持在前端自定义组合Pass。 可以通过TVM的API直接操作IR,支持Python端写Pass。
0x4. TVM的代码生成流程
了解了TVM的基本组件以及整体架构之后,有必要再了解一下TVM的代码生成流程,具体请看【从零开始学深度学习编译器】九,TVM的CodeGen流程 。
0x5. 参考
https://www.zhihu.com/column/c_1388629436179378176
https://www.cnblogs.com/CocoML/p/14643355.html
https://github.com/apache/tvm
欢迎关注GiantPandaCV, 在这里你将看到独家的深度学习分享,坚持原创,每天分享我们学习到的新鲜知识。( • ̀ω•́ )✧
有对文章相关的问题,或者想要加入交流群,欢迎添加BBuf微信: