
深度学习100问-1:深度学习环境配置有哪些坑?
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

从今天起,开辟一个新的专栏,名字就叫深度学习100问。选取深度学习中典型的100个重大问题并给出详细的解读和笔记。希望以这样一种形式进行个人实践和知识积累,也能给后来的同学以帮助。100问预计今年年底更新完。需要说明的是,这100问并不是入门笔记,想要入门的同学可以参考去年的深度学习60讲系列:
深度学习第一问是关于环境配置的。之前笔者也在深度学习60讲系列中讲到如何配置深度学习开发环境的问题:深度学习笔记15:ubuntu16.04 下深度学习开发环境搭建与配置。但环境配置并不是一路顺利的,总有些奇奇怪怪的问题让人头疼,所以,在第一问中笔者选取了几个典型的环境配置的错误供大家参考。
cuda是nvidia推出的用于自家GPU的并行计算框架,也就是说cuda只能在nvidia的GPU上运行,而且只有当要解决的计算问题是可以大量并行计算的时候才能发挥cuda的作用。
cudnn是nvidia打造的针对深度神经网络的加速库,是一个用于深层神经网络的GPU加速库。如果你要用GPU训练模型,cudnn不是必须的,但是一般会采用这个加速库。
cuda driver即cuda驱动器,是用来支持cuda运行的必备程序。而cudatoolkit则是cuda相关的工具包。
以上四者之间必须有个版本对应和匹配的问题。有时候安装keras GPU版本的时候会默认安装cudatoolikit 10.0,这时候如果你cuda是9.0的版本的话,一般会报个CUDA driver version is insufficient for CUDA的错误。如下所示:
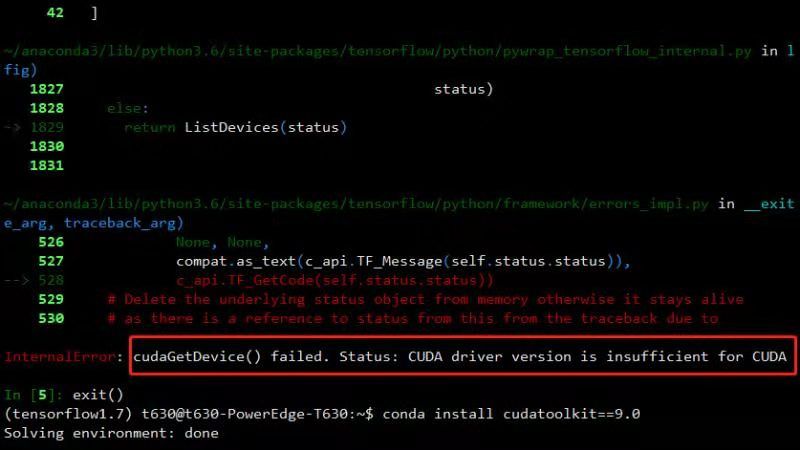
这时候你可能需要降低cudatoolkit的版本:
conda install cudatoolkit==9.0还有一种常见的错误是cuda driver的驱动器跟cuda不匹配。执行nvidia-smi命令会出现如下图错误:
Failed to initialize NVML: Driver/library version mismatchnvidia官方给出了cuda和cuda driver之间版本对应关系:
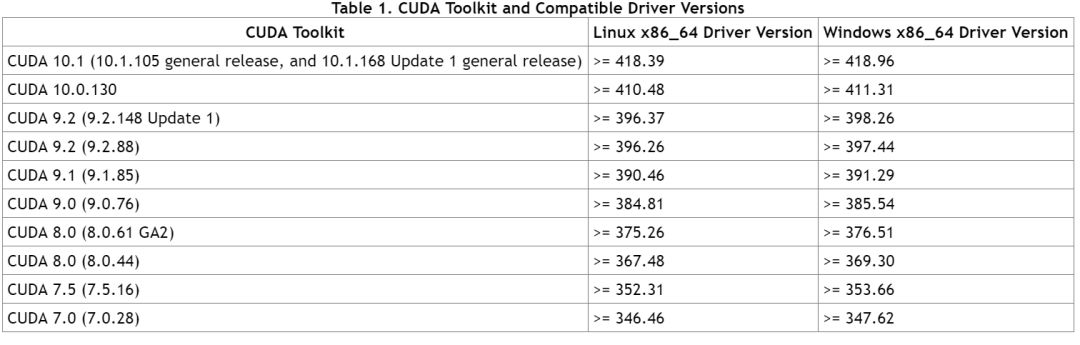
在版本不匹配时,适当降低或者更新驱动器版本即可。另外驱动器版本更新之后可能需要重启系统,当然通过如下方法不用重启也可以更新版本。首先尝试删除nvidia相关的kernel mod。
sudo rmmod nvidia当然这里一般会报个Module nvidia is in use by的错误。不碍事,我们先查看下kernel mod 的依赖情况:
ls mod | grep nvidia 根据根据结果逐一rmmod即可。
sudo rmmod nvidia_uvmsudo rmmod nvidia_modeset
最后再rmmod nvidia即可达到驱动器更新效果。
sudo rmmod nvidianvidia-smi
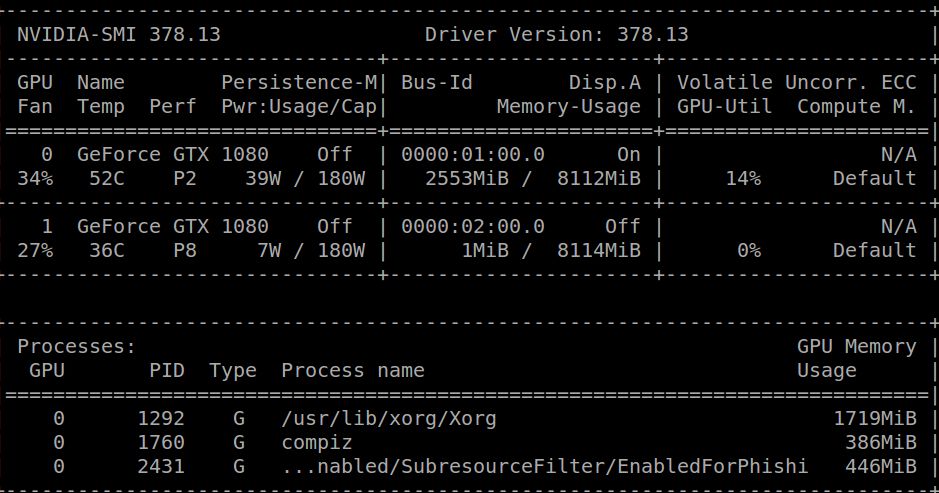
还有一种报错是cudnn版本不匹配的问题:
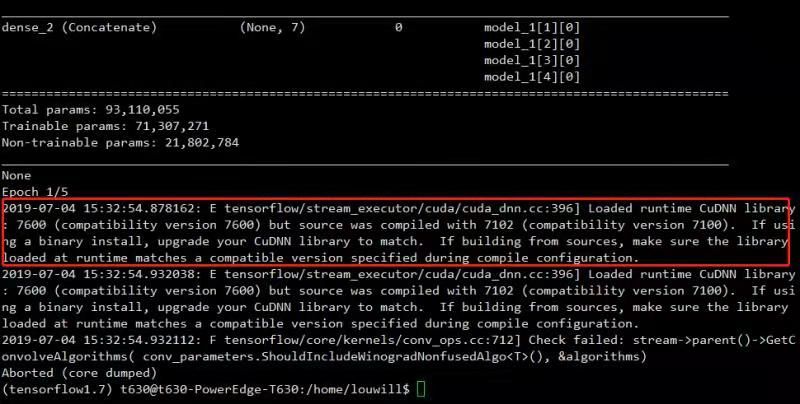
此时直接更新cudnn版本即可。
一般来说,大家在共用实验室GPU服务器的时候为了避免环境污染都会各自建好虚拟环境,在虚拟环境下进行各自的深度学习实验。有些同学喜欢使用jupyter进行交互式实验,或者是使用ipython,这时候你要注意虚拟环境下的ipython和jupyter版本是跟系统全局环境是一致的,跟你当前虚拟环境的python版本不一定一致。举个例子,假设你的系统全局环境的tensorflow是1.13.1版本,当你在虚拟环境下安装的是tensorflow1.14版本,你虚拟环境下的jupyter tensorflow版本不是1.14,而是1.13.1。这一点大家需要注意。
想要在虚拟环境下使用当前环境的jupyter或者ipython会比较麻烦,首先需要卸载系统全局环境下的jupyter和ipython,卸载起来会比较麻烦,具体过程可参考stackoverflow:
https://stackoverflow.com/questions/37061089/trouble-with-tensorflow-in-jupyter-notebook?rq=1虽说按部就班的配环境好像也没啥大问题,但要想让你的TensorFlow和Torch顺利用上GPU跑起来并不是一件那么顺利的事。此时,直接使用nvidia-smi命令并不能表明TensorFlow就能顺利用上GPU。
比如说我们用Keras跑模型时指定了GPU,有时候会报如下错误:
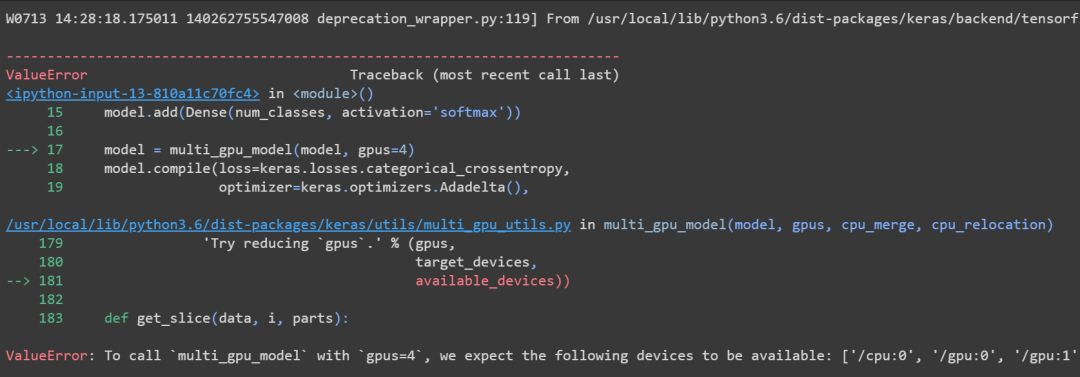
一方面,你的机器可能确实没有那么多GPU,另外一种可能就是你没有安装支持GPU的TensorFlow或者Keras版本。这时候我们可以先来验证下当前的TensorFlow或Keras是否支持GPU。
先来看TensorFlow:
from tensorflow.python.client import device_libprint(device_lib.list_local_devices())
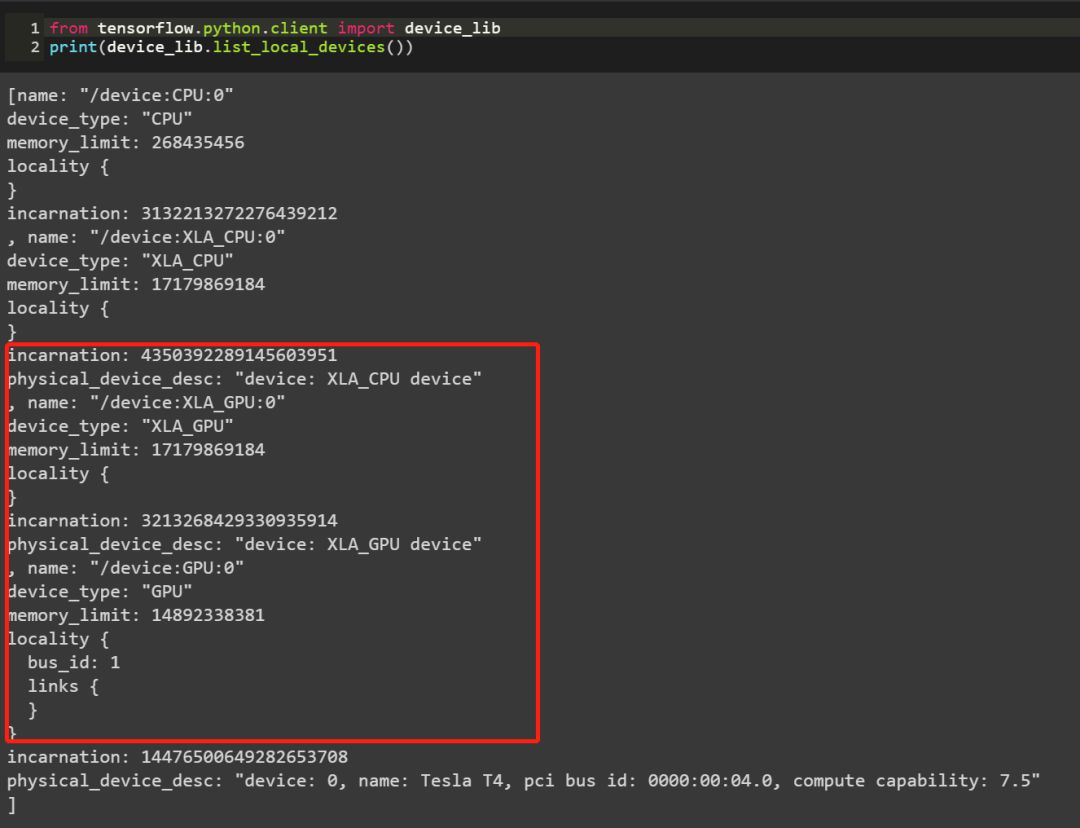
如果输出结果有类似上述包含GPU的信息,那说明你的tensorflow是支持GPU的。再看keras:
from keras import backend as Kprint(K.tensorflow_backend._get_available_gpus())
如果能输出下述包含GPU的信息的话那说明当前的keras版本也是支持GPU的。

Torch的话安装到时候一般都会根据官网的配置要求来:
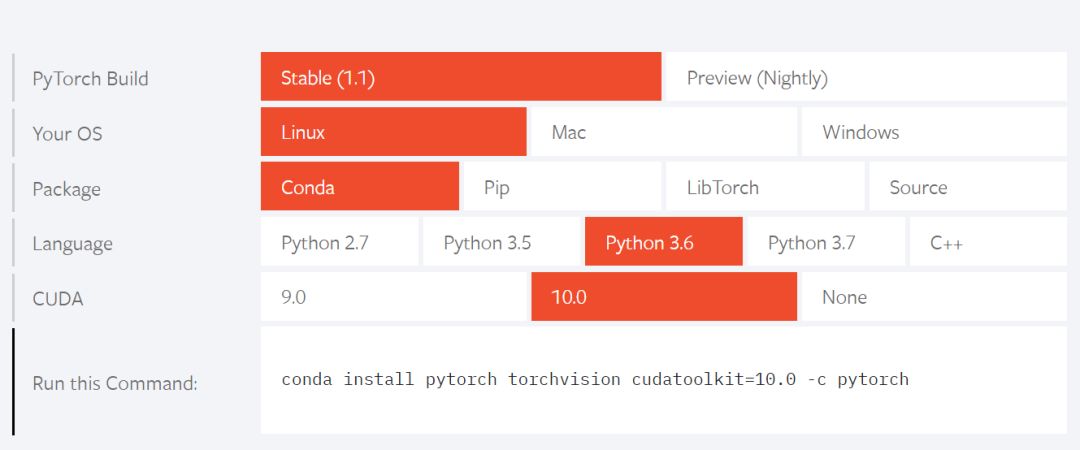
一般安装后输入下列命令即可:
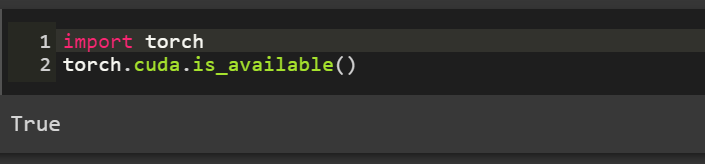
import torchtorch.cuda.is_available()
如果输出为True的话则表明当前的torch是支持GPU加速的。
如果你没有得到上述的输出结果,那么需要重新安装带gpu版本的tensorfow或者keras:
pip install tensorflow-gpuconda install keras-gpu
按照上述过程下来一般就会顺利配置好各深度学习框架版本。
最后,如果大家没有GPU资源又或者嫌配置太糟心,我们还是有免费的GPU可以褥的。一个是谷歌的colab,自动支持GPU,大家可以直接去褥。另外一个是kaggle竞赛平台的kernel,里面也是提供GPU算力的。
colab目前提供的GPU已经由之前K80升级到了Tesla T4:
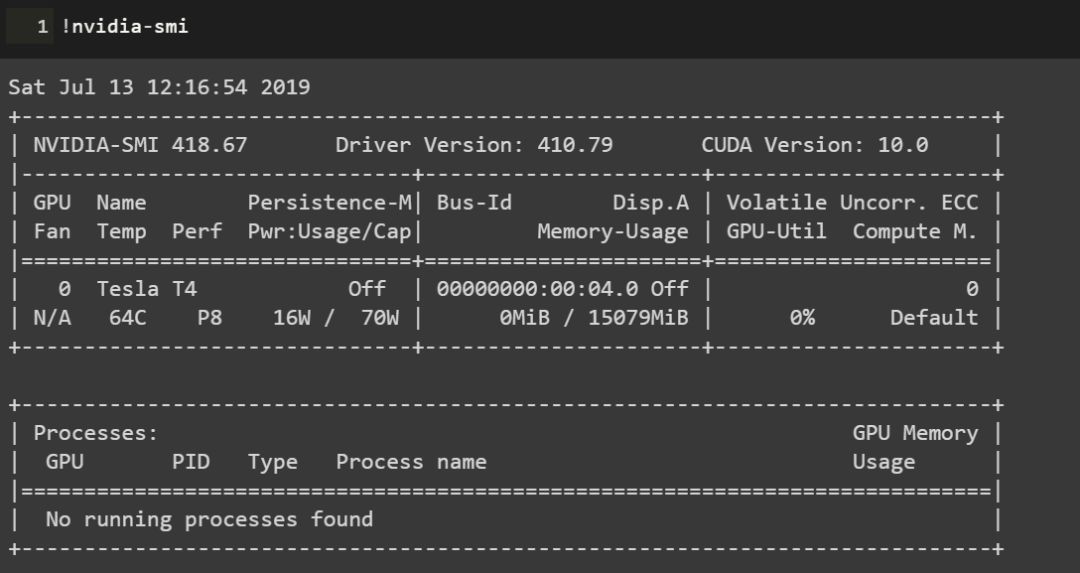
kaggle提供的则是Tesla P100:
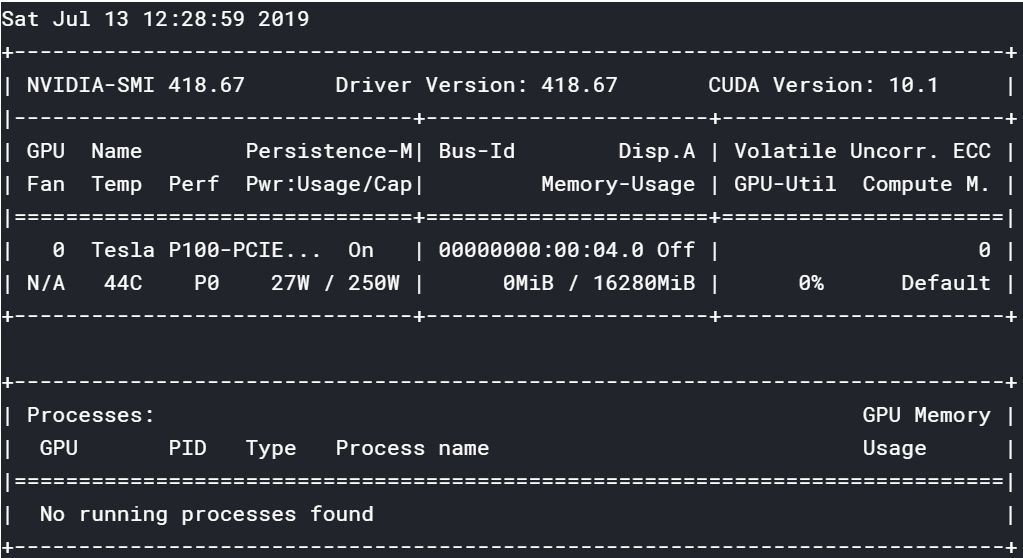
大家可以自行去褥。当然前提可能是大家需要一点点科学上网的方法。
colab地址:
https://colab.research.google.com/notebooks/kaggle地址:
https://www.kaggle.com/nvidia官方文档地址:
https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~