
深度学习领域有哪些瓶颈?
点击左上方蓝字关注我们

转载自 | 深度学习与计算机视觉
链接 | https://www.zhihu.com/question/40577663/answer/902429604

一、深度学习缺乏理论支撑
大多数文章的idea都是靠直觉提出来的,背后的很少有理论支撑。通过实验验证有效的idea,不一定是最优方向。就如同最优化问题中的sgd一样,每一个step都是最优,但从全局来看,却不是最优。
没有理论支撑的话,计算机视觉领域的进步就如同sgd一样,虽然有效,但是缓慢;如果有了理论支撑,计算机视觉领域的进步就会像牛顿法一样,有效且迅猛。
CNN模型本身有很多超参数,比如设置几层,每一层设置几个filter,每个filter是depth wise还是point wise,还是普通conv,filter的kernel size设置多大等等。
这些超参数的组合是一个很大的数字,如果只靠实验来验证,几乎是不可能完成的。最后只能凭直觉试其中一部分组合,因此现在的CNN模型只能说效果很好,但是绝对还没达到最优,无论是效果还是效率。
以效率举例,现在resnet效果很好,但是计算量太大了,效率不高。然而可以肯定的是resnet的效率可以提高,因为resnet里面肯定有冗余的参数和冗余的计算,只要我们找到这些冗余的部分,并将其去掉,效率自然提高了。一个最简单而且大多人会用的方法就是减小各层channel的数目。
如果一套理论可以估算模型的capacity,一个任务所需要模型的capacity。那我们面对一个任务的时候,使用capacity与之匹配的模型,就能使得效果好,效率优。
二、领域内越来越工程师化思维
因为深度学习本身缺乏理论,深度学习理论是一块难啃的骨头,深度学习框架越来越傻瓜化,各种模型网上都有开源实现,现在业内很多人都是把深度学习当乐高用。
面对一个任务,把当前最好的几个模型的开源实现git clone下来,看看这些模型的积木搭建说明书(也就是论文),思考一下哪块积木可以改一改,积木的顺序是否能调换一样,加几个积木能不能让效果更好,减几个积木能不能让效率更高等等。
思考了之后,实验跑起来,实验效果不错,文章发起来,实验效果不如预期,重新折腾一遍。
这整个过程非常的工程师化思维,基本就是凭感觉trial and error,深度思考缺位。很少有人去从理论的角度思考模型出了什么问题,针对这个问题,模型应该做哪些改进。
举一个极端的例子,一个数据实际上是一次函数,但是我们却总二次函数去拟合,发现拟合结果不好,再用三次函数拟合,三次不行,四次,再不行,就放弃。我们很少思考,这个数据是啥分布,针对这样的分布,有没有函数能拟合它,如果有,哪个函数最合适。
深度学习本应该是一门科学,需要用科学的思维去面对她,这样才能得到更好的结果。
三、对抗样本是深度学习的问题,但不是深度学习的瓶颈
我认为对抗样本虽然是深度学习的问题,但并不是深度学习的瓶颈。机器学习中也有对抗样本,机器学习相比深度学习有着更多的理论支撑,依然没能把对抗样本的问题解决。
之所以我们觉得对抗样本是深度学习的瓶颈是因为,图像很直观,当我们看到两张几乎一样的图片,最后深度学习模型给出两种完全不一样的分类结果,这给我们的冲击很大。
如果修改一个原本类别是A的feature中某个元素的值,然后使得svm的分类改变为B,我们会觉得不以为然,“你改变了这个feature中某个元素的值,它的分类结果改变很正常啊”。
https://www.zhihu.com/question/40577663/answer/413331053
我们已经有海量的数据,海量的算力,但我们却难以训练大型的深度网络模型(GB 到 TB 级别的模型),因为 BP 难以大规模并行化。数据并行不够,用模型并行后加速比就会大打折扣。即使在加入诸多改进后,训练过程对带宽的要求仍然太高。
这就是为什么 nVidia 的 DGX-2 只有 16 块 V100,但就是要卖到 250 万。因为虽然用少得多的钱就可以凑出相同的总算力,但很难搭出能高效运用如此多张显卡的机器。

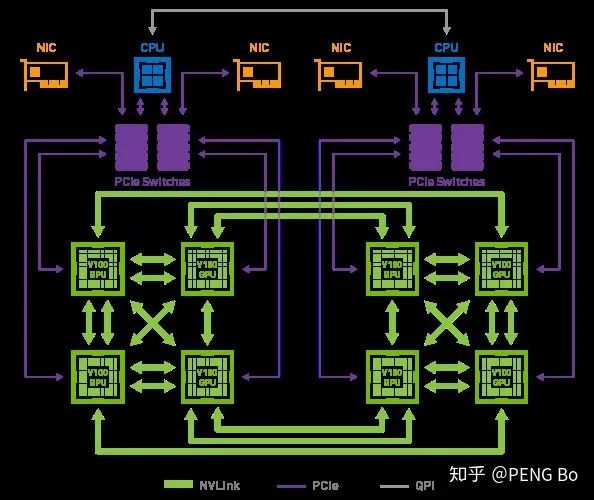
如果什么时候深度学习可以无脑堆机器就能不断提高训练速度(就像挖矿可以堆矿机),从而可以用超大规模的多任务网络,学会 PB EB 级别的各类数据,那么所能实现的效果很可能会是令人惊讶的。
那么我们看现在的带宽:https://en.wikipedia.org/wiki/List_of_interface_bit_rates
2011年出了PCI-E 3.0 x16,是 15.75 GB/s,现在消费级电脑还是这水平,4.0还是没出来,不过可能是因为大家没动力(游戏对带宽要求没那么高)。
NVLink 2.0是 150 GB/s,对于大型并行化还是完全不够的。
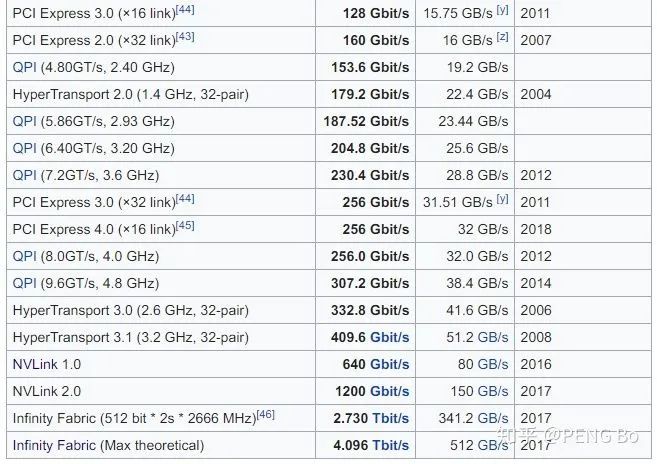
很好,那么,这就来到了最奇怪的问题,我想这个问题值得思考:
AI芯片花了这么大力气还是带宽受限,那么人脑为何没有受限于带宽?
我的想法是:
人脑的并行化做得太好了,因此神经元之间只需要kB级的带宽。值得AI芯片和算法研究者学习。 人脑的学习方法比BP粗糙得多,所以才能这样大规模并行化。 人脑的学习方法是去中心化的,个人认为,更接近 energy-based 的方法。 人脑的其它特点,用现在的迁移学习+多任务学习+持续学习已经可以模仿。 人脑还会用语言辅助思考。如果没有语言,人脑也很难快速学会复杂的事情。
https://www.zhihu.com/question/40577663/answer/1974793135
1. 对标注数据依赖性大
这也是为什么前期数据不足或冷启动阶段,深度学习模型效果差强人意的地方。相比人类而言,模型在学习新事物时需要更多的事例。
虽然近期有了一些 low-resource 甚至 zero-resource 工作(例如对话生成的两篇论文[1-2]),总体来说这些方法仅适用于某些特定领域,难以直接推广。
2. 模型具有领域依赖性,难以直接迁移
或者模型仅在论文数据集上表现良好,在其余数据中无法复现类似效果。这些都是非常常见的问题,
提升模型的迁移能力是深度学习非常有价值的课题,可以大幅减少数据标注带来的成本。好比我一个同学玩跑跑卡丁车很老练,现在新出了QQ飞车手游,他开两局就能触类旁通,轻松上星耀和车神,而不需要从最原始的漂移练起。
虽然NLP预训练+微调的方式缓解了这一问题,但深度学习可迁移性还有待进一步增强。
3. 巨无霸模型对资源要求高
因为大模型的参数量在呈指数增长趋势:BERT(1.1亿)、T5(110亿)、GPT3(1500亿)、盘古(2000亿)...开发高性能小模型是深度学习另一个很有价值的方向。
庆幸的是,在NLP领域已经有了一些不错的轻量化工作,例如TinyBERT[3],FastBERT[4]等。
4. 模型欠缺常识和推理能力
将来的某天,深度学习模型除了能写诗、解方程、下围棋,还能回答家长里短的常识性问题,才真正算是拥有了“智能”。
5. 应用场景有限
虽然NLP有很多子领域,但是目前发展最好的方向依旧只有分类、匹配、翻译、搜索几种,大部分任务的应用场景依然受限。
6. 缺少高效的超参数自动搜索方案
7. 部分paper仅以比赛SOTA为导向
当然这里并不是说这种方法不好,只是我们做研究时不应该只以刷榜为唯一目标。因为很多时候为了提升小数点后那0.XX%的分数真的意义不大,难以对现有的深度学习发展带来任何益处。
这也解释了面试官询问“如何在某比赛中获得了不错的成绩”,听到“多模集成”等堆模型的方式上分就反感。因为实际场景受限于资源、时间等因素,一般不会这么干。
8. 可解释性不强

对一些模型学到的特征可视化(CNN、Attention等),或许可以帮助我们理解模型是怎样学习的。此前,机器学习领域也有利用降维技术(t-SNE等)来理解高维特征分布的方法。
更多深度学习可解释性研究可以参考[6]。
最近,2018图灵奖获得者 Bengio, LeCun 和 Hinton 受ACM邀请共聚一堂,回顾了深度学习的基本概念和一些突破性成果,也讲述了深度学习未来发展面临的挑战。
https://www.zhihu.com/question/40577663/answer/224699031
深度学习,深是表象,不是目的。Universal approximation theorem 理论证明只需要一个隐层就可以拟合任意函数,可见重点不在深。深度学习与传统机器学习相比:深度学习就是在学习表示。也就是说,通过精心设计的分层结构学习到数据的本质特征(表示)。
说到瓶颈,深度学习也算是机器学习的一种,它也会有机器学习本身的瓶颈。例如对数据依赖性很强。是数据的“行为智能”而非真的有自主意识的人工智能。这些问题上面的答案都说了不少。
除此之外,它还有一些特有的瓶颈。
比如特征结构难以改变。对于数据的格式(尺寸、长短、颜色通道、文本词典格式等等)要求苛刻。训练好的feature extractor不是那么容易迁移到其他task上。 它非常的不稳定。例如在NLP的任务中,做文本生成(QA)、图像标注之类的工作时,有时候生成的内容让你拍案叫绝。但经常也会是匪夷所思。所以它的不可控性导致在工程应用中不是很广泛。很多牺牲recall保precision的应用都没法用深度学习去搞,否则容易出危险。相比之下rule based的方法要可靠得多。至少出问题了能debug一下。
它难以hotfix,出了问题基本靠重新调参训练。在应用过程中会遇上很多潜在困难。
深度模型的优化过于依赖个人经验。世界三大玄学:西方占星、东方周易、深度学习。
模型结构越来越复杂,不同系统之间越来越难以整合。就好像一直在培养超级士兵,但他们之间语言不通,没法组成一个超级军队。
敏感信息问题。训练模型使用的数据如果没有脱敏,是有可能通过一些方法把敏感信息给试出来。
攻击问题。现在已经证实对抗样本(Adversarial Sample)的存在。创建一些对抗样本能直接干掉现有的算法。不过感觉对抗样本的生成是由于特征抽取并没有学习到数据的流型特征而引发的。或者说,一定程度的overfit带来了这个问题,
不过目前来说最大的问题还是对海量数据的需求。由于需要学习真实分布,而我们的数据仅仅是从真实分布中采样得到的一小部分。想要让模型真的逼近真实分布,那就要尽可能多的数据。数据量需求上来了,问题有很多:数据从哪来?数据存在哪?如何洗数据?谁来标数据?如何在大量数据上训练?如何在成本(设备、数据)和效果之间trade off?
由第8条扩展。需要海量数据的深度学习真的就是“人工智能”吗?反正我是不信。人脑可以用有限的知识归纳,而非只是用人为设计的指导方针来指挥机器学习到特征空间的分布。所以真正的人工智能,对数据和运算的需求应该并没有那么大!(这条其实也是机器学习的问题)
https://www.zhihu.com/question/40577663/answer/311095389
Dropout/BN/Residual这些创新也好trick也罢,至少能编一个有眉有颜的直观解释糊弄一下,在截然不同的场景和任务下也有成功的应用。去年这种级别的新的好用的trick基本没见着。炼丹师的人口越来越庞大,通用性的trick却没有被发掘出来,说明领域已经到了一个瓶颈,好摘的桃子已经被摘光了。
结构的潜力已经被挖光了么?还是我们没有找到更具有通用性和代表性的任务来作为新的trick的温床?这些都是DL研究需要回答的问题。现在看起来形式并不乐观,传统的DL研究依赖的改几根线多加几个layer,针对一个特定任务跑个分的范式,现在要发出高质量的paper是越来越困难了。
个人的看法是,如果DL想要真正带上人工智能的帽子,那就要去做智能改干的事情,现在人为的按照应用场景分成NLP/CV/ASR,粗暴的去拟合终究有上限,和人类获得智能的方式也并没有共同点。
https://www.zhihu.com/question/40577663/answer/224656397
图像分类问题。此时x一般就是一个宽度*高度*通道数的图像数值矩阵,y就是分类的类别。 语音识别问题。x为语音采样信号,y为语音对应的文字。 机器翻译。x就是源语言的句子,y就是目标语言的句子。
模型容量大,参数多 端到端(end-to-end)
一、训练f的效率还不算高
在训练效率上还有一个缺点是样本的利用率不高。举个小小的例子:图片鉴黄。对于人类来说,只需要看几个“训练样本”,就可以学会鉴黄,判断哪些图片属于“色情”是非常简单的一件事。但是,训练一个深度学习的鉴黄模型却往往需要成千上万张正例+负例的样本,例如雅虎开源的yahoo/open_nsfw。总的来说,和人类相比,深度学习模型往往需要多得多的例子才能学会同一件事。这是由于人类已经拥有了很多该领域的“先验知识”,但对于深度学习模型,我们却缺乏一个统一的框架向其提供相应的先验知识。
那么在实际应用中,如何解决这两个问题?对于训练时间长的问题,解决办法是加GPU;对于样本利用率的问题,可以通过增加标注样本来解决。但无论是加GPU还是加样本,都是需要钱的,而钱往往是制约实际项目的重要因素。
二、拟合得到的f本身的不可靠性
一个比较典型的例子是“对抗生成样本”。如下所示,神经网络以60%的置信度将原始图片识别为“熊猫”,当我们对原始图像加入一个微小的干扰噪声后,神经网络却以99%的置信度将图片识别为“长臂猿”。这说明深度学习模型并没有想象得那么可靠。

三、f可以实现“强人工智能”吗
https://www.zhihu.com/question/40577663/answer/225319588
2、深度学习在应对表格类数据的时候并没有明显优势,目前比较擅长的领域是计算机视觉,自然语言处理和语音识别。在表格数据情境下,大家更愿意使用xgboost等模型。
3、理论支撑薄弱,几乎没有人对深度学习的数学基础做工作。大家一窝蜂地拿着模型水论文。
4、接上条,调参基本陷入了炼丹模式,深度学习调参已经是一门玄学。
5、硬件资源消耗大,GPU已经是必备,但是价格高昂,因此深度学习也称为富人的游戏。
6、部署落地仍然困难,特别是移动应用场景下。
7、无监督学习仍然是困难,深度学习训练目前基本都基于梯度下降去极小化损失函数,因此需要有标签。而对大量数据贴标签成本很高。当然也有无监督学习网络正在迅猛发展,不过严格意义上说,GAN和VAE等都属于自监督学习。
看到评论中有质疑第一条的,我发表一下自己的看法:一个比较强的学习器一般都不会担心欠拟合的问题。神经网络拥有大量参数,只要有足够多的训练轮数,理论上可以完全拟合训练集。但是这并不是我们想要的,这样的模型泛化能力会非常差。而造成这一结果的原因就是,数据量太少,不足以代表整个数据背后的分布情况。此种情况下,神经网络几乎是不加辨别的强行拟合上了训练集这个数据子集的分布,导致了过拟合。
https://www.zhihu.com/question/40577663/answer/224756448
1.end-to-end training
2.universal approximation
缺点是对其中间拟合过程我们几乎没有任何control,所有我们想让其学习到的东西只能通过大量的数据,更复杂的网络(inception module, more layers),限定更多constraint(dropout, regularization),期望它最后学习到了等同于我们认知的判断。
举个具体的例子,我们想判断一直图像是不是人脸。
其中一个笼统的判断标准是,这张图像上是否涵盖2只眼睛,1个鼻子,1个嘴巴,以及他们之间的位置信息是否符合几何逻辑。这也正是传统dpm的思路,虽然以上每一步(subtask)都有可能出错,致使overall performance不会特别好。但是相对来讲每一个subtask都只需要较少的训练数据,中间结果都会比较直观,最后的结果符合我们人类的判断标准。
但是这件事由深度学习来做,你除了少数几个“认知”(prior knowledge)可以通过网络结构来定义(例如cnn实际上是默认feature的local coherent+position invariant的特性),其他的认知只能通过大量的数据来让网络自己去学习。一些简单的元素如脸的大小,位置,旋转你还可以通过data augmentation来模拟,但对于肤色,背景图案,头发的因素,就要靠找额外数据开扩充网络对问题的认知了。但即使是这样,我们也无法确定网络总结了哪些高层次的知识,当我拿给他一张训练数据里没有的二郎神的图像,它会做出怎样的判断。
这也正是为什么数据是深度学习里最重要的一项。当你数据不够多样的时候,它可能只学习到一些比较hacky的trivial solution;但是当数据足够全面的时候,它更有可能总结出比单纯鼻子眼睛更有表达力的特征,只是我们无法理解而已。
END
整理不易,点赞三连↓