
简历写着熟悉 Dubbo,居然连 Dubbo 线程池监控都不知道?

阅读本文大概需要 8 分钟。
来自:网络
Dubbo底层对于线程池的查看
package org.idea.dubbo.monitor.core.collect;
import org.apache.dubbo.common.extension.ExtensionLoader;
import org.apache.dubbo.common.threadpool.manager.DefaultExecutorRepository;
import org.apache.dubbo.common.threadpool.manager.ExecutorRepository;
import java.lang.reflect.Field;
import java.util.concurrent.ConcurrentMap;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.ThreadPoolExecutor;
/**
* @Author idea
* @Date created in 7:04 下午 2022/6/29
*/
public class DubboThreadPoolCollector {
/**
* 获取Dubbo的线程池
* @return
*/
public static ThreadPoolExecutor getDubboThreadPoolInfo(){
//dubbo线程池数量监控
try {
ExtensionLoader<ExecutorRepository> executorRepositoryExtensionLoader = ExtensionLoader.getExtensionLoader(ExecutorRepository.class);
DefaultExecutorRepository defaultExecutorRepository = (DefaultExecutorRepository) executorRepositoryExtensionLoader.getDefaultExtension();
Field dataField = defaultExecutorRepository.getClass().getDeclaredField("data");
dataField.setAccessible(true);
ConcurrentMap<String, ConcurrentMap<Integer, ExecutorService>> data = (ConcurrentMap<String, ConcurrentMap<Integer, ExecutorService>>) dataField.get(defaultExecutorRepository);
ConcurrentMap<Integer, ExecutorService> executorServiceConcurrentMap = data.get("java.util.concurrent.ExecutorService");
//获取到默认的线程池模型
ThreadPoolExecutor threadPoolExecutor = (ThreadPoolExecutor) executorServiceConcurrentMap.get(9090);
return threadPoolExecutor;
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
}
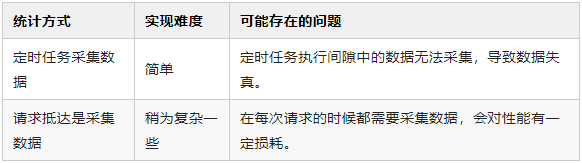
采集数据
后台开启一个定时任务,然后每秒都查询一下线程池的参数信息。 每次有请求抵达provider的时候,就查看一些线程池的参数信息。
package org.idea.dubbo.monitor.core.filter;
import org.apache.dubbo.common.constants.CommonConstants;
import org.apache.dubbo.common.extension.Activate;
import org.apache.dubbo.rpc.*;
import org.idea.dubbo.monitor.core.DubboMonitorHandler;
import java.util.concurrent.ThreadPoolExecutor;
import static org.idea.dubbo.monitor.core.config.CommonCache.DUBBO_INFO_STORE_CENTER;
/**
* @Author idea
* @Date created in 2:33 下午 2022/7/1
*/
@Activate(group = CommonConstants.PROVIDER)
public class DubboRecordFilter implements Filter {
@Override
public Result invoke(Invoker<?> invoker, Invocation invocation) throws RpcException {
ThreadPoolExecutor threadPoolExecutor = DubboMonitorHandler.getDubboThreadPoolInfo();
//请求的时候趣统计线程池,当请求量太小的时候,这块的数据可能不准确,但是如果请求量大的话,就接近准确了
DUBBO_INFO_STORE_CENTER.reportInfo(9090,threadPoolExecutor.getActiveCount(),threadPoolExecutor.getQueue().size());
return invoker.invoke(invocation);
}
}
dubboRecordFilter=org.idea.dubbo.monitor.core.filter.DubboRecordFilter
package org.idea.dubbo.monitor.core.collect;
import org.idea.dubbo.monitor.core.bo.DubboInfoStoreBO;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;
/**
* Dubbo数据存储中心
*
* @Author idea
* @Date created in 11:15 上午 2022/7/1
*/
public class DubboInfoStoreCenter {
private static Map<Integer, DubboInfoStoreBO> dubboInfoStoreBOMap = new ConcurrentHashMap<>();
public void reportInfo(Integer port, Integer corePoolSize, Integer queueLength) {
synchronized (this) {
DubboInfoStoreBO dubboInfoStoreBO = dubboInfoStoreBOMap.get(port);
if (dubboInfoStoreBO != null) {
boolean hasChange = false;
int currentMaxPoolSize = dubboInfoStoreBO.getMaxCorePoolSize();
int currentMaxQueueLength = dubboInfoStoreBO.getMaxCorePoolSize();
if (corePoolSize > currentMaxPoolSize) {
dubboInfoStoreBO.setMaxCorePoolSize(corePoolSize);
hasChange = true;
}
if (queueLength > currentMaxQueueLength) {
dubboInfoStoreBO.setMaxQueueLength(queueLength);
hasChange = true;
}
if (hasChange) {
dubboInfoStoreBOMap.put(port, dubboInfoStoreBO);
}
} else {
dubboInfoStoreBO = new DubboInfoStoreBO();
dubboInfoStoreBO.setMaxQueueLength(queueLength);
dubboInfoStoreBO.setMaxCorePoolSize(corePoolSize);
dubboInfoStoreBOMap.put(port, dubboInfoStoreBO);
}
}
}
public DubboInfoStoreBO getInfo(Integer port){
return dubboInfoStoreBOMap.get(port);
}
public void cleanInfo(Integer port) {
dubboInfoStoreBOMap.remove(port);
}
}
package org.idea.dubbo.monitor.core.config;
import org.idea.dubbo.monitor.core.store.DubboInfoStoreCenter;
/**
* @Author idea
* @Date created in 12:15 下午 2022/7/1
*/
public class CommonCache {
public static DubboInfoStoreCenter DUBBO_INFO_STORE_CENTER = new DubboInfoStoreCenter();
}
上报数据
package org.idea.dubbo.monitor.core.bo;
/**
* @Author idea
* @Date created in 7:17 下午 2022/6/29
*/
public class ThreadInfoBO {
private Integer activePoolSize;
private Integer queueLength;
private long saveTime;
public Integer getActivePoolSize() {
return activePoolSize;
}
public void setActivePoolSize(Integer activePoolSize) {
this.activePoolSize = activePoolSize;
}
public Integer getQueueLength() {
return queueLength;
}
public void setQueueLength(Integer queueLength) {
this.queueLength = queueLength;
}
public long getSaveTime() {
return saveTime;
}
public void setSaveTime(long saveTime) {
this.saveTime = saveTime;
}
@Override
public String toString() {
return "ThreadInfoBO{" +
", queueLength=" + queueLength +
", saveTime=" + saveTime +
'}';
}
}
package org.idea.dubbo.monitor.core.report;
import com.alibaba.fastjson.JSON;
import org.idea.dubbo.monitor.core.bo.DubboInfoStoreBO;
import org.idea.dubbo.monitor.core.bo.ThreadInfoBO;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.CommandLineRunner;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import static org.idea.dubbo.monitor.core.config.CommonCache.DUBBO_INFO_STORE_CENTER;
/**
* @Author idea
* @Date created in 12:13 下午 2022/7/1
*/
public class DubboInfoReportHandler implements CommandLineRunner {
@Autowired
private IReportTemplate reportTemplate;
private static final Logger LOGGER = LoggerFactory.getLogger(DubboInfoReportHandler.class);
public static ExecutorService executorService = Executors.newFixedThreadPool(1);
public static int DUBBO_PORT = 9090;
@Override
public void run(String... args) throws Exception {
executorService.submit(new Runnable() {
@Override
public void run() {
while (true) {
try {
Thread.sleep(10000);
DubboInfoStoreBO dubboInfoStoreBO = DUBBO_INFO_STORE_CENTER.getInfo(DUBBO_PORT);
ThreadInfoBO threadInfoBO = new ThreadInfoBO();
threadInfoBO.setSaveTime(System.currentTimeMillis());
if(dubboInfoStoreBO!=null){
threadInfoBO.setQueueLength(dubboInfoStoreBO.getMaxQueueLength());
threadInfoBO.setActivePoolSize(dubboInfoStoreBO.getMaxCorePoolSize());
} else {
//这种情况可能是对应的时间段内没有流量请求到provider上
threadInfoBO.setQueueLength(0);
threadInfoBO.setActivePoolSize(0);
}
//这里是上报器上报数据到redis中
reportTemplate.reportData(JSON.toJSONString(threadInfoBO));
//上报之后,这里会重置map中的数据
DUBBO_INFO_STORE_CENTER.cleanInfo(DUBBO_PORT);
LOGGER.info(" =========== Dubbo线程池数据上报 =========== ");
} catch (Exception e) {
e.printStackTrace();
}
}
}
});
}
}
org.idea.dubbo.monitor.core.report.IReportTemplate
package org.idea.dubbo.monitor.core.report;
/**
* 上报模版
*
* @Author idea
* @Date created in 7:10 下午 2022/6/29
*/
public interface IReportTemplate {
/**
* 上报数据
*
* @return
*/
boolean reportData(String json);
}
package org.idea.dubbo.monitor.core.report.impl;
import org.idea.dubbo.monitor.core.report.IReportTemplate;
import org.idea.qiyu.cache.redis.service.IRedisService;
import org.springframework.stereotype.Component;
import javax.annotation.Resource;
import java.time.LocalDate;
import java.util.concurrent.TimeUnit;
/**
* @Author idea
* @Date created in 7:12 下午 2022/6/29
*/
@Component
public class RedisTemplateImpl implements IReportTemplate {
@Resource
private IRedisService redisService;
private static String queueKey = "dubbo:threadpool:info:";
@Override
public boolean reportData(String json) {
redisService.lpush(queueKey + LocalDate.now().toString(), json);
redisService.expire(queueKey + LocalDate.now().toString(),7, TimeUnit.DAYS);
return true;
}
}
数据展示
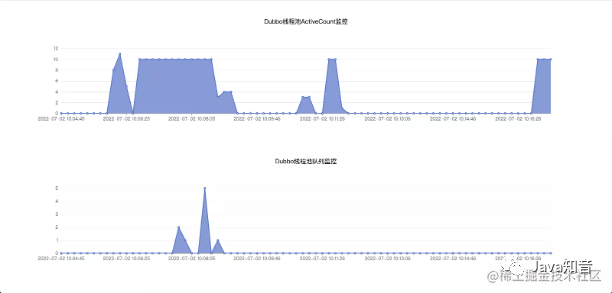
推荐阅读:
Lombok原理和同时使⽤@Data和@Builder 的坑
互联网初中高级大厂面试题(9个G) 内容包含Java基础、JavaWeb、MySQL性能优化、JVM、锁、百万并发、消息队列、高性能缓存、反射、Spring全家桶原理、微服务、Zookeeper......等技术栈!
⬇戳阅读原文领取! 朕已阅

评论