
解读UTNet | 用于医学图像分割的混合Transformer架构(文末获取论文)


UTNet:用于医学图像分割的混合Transformer架构,表现SOTA!性能优于ResUNet等网络。
作者单位:罗格斯大学等
1简介
Transformer架构已经在许多自然语言处理任务中取得成功。然而,它在医学视觉中的应用在很大程度上仍未得到探索。在这项研究中,本文提出了UTNet,这是一种简单而强大的混合Transformer架构,它将自注意力集成到卷积神经网络中,以增强医学图像分割。
UTNet在编码器和解码器中应用自注意力模块,以最小的开销捕获不同规模的远程依赖。为此,作者提出了一种有效的自注意力机制以及相对位置编码,将自注意力操作的复杂性从O(n2)显著降低到近似O(n)。还提出了一种新的自注意力解码器,以从编码器中跳过的连接中恢复细粒度的细节。
本文所提的方法解决了Transformer需要大量数据来学习视觉归纳偏差的困境。同时混合层设计允许在不需要预训练的情况下将Transformer初始化为卷积网络。
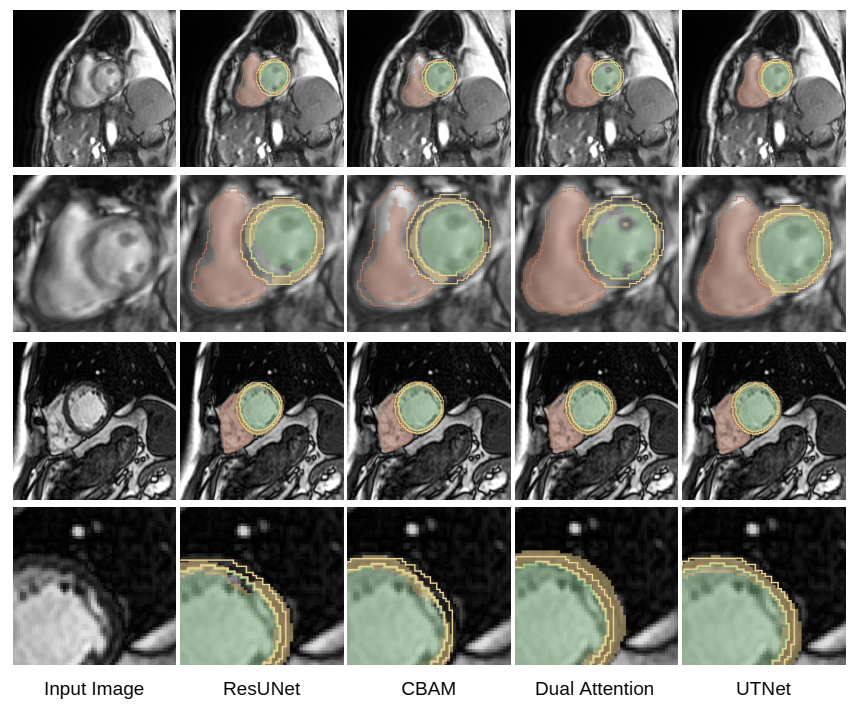
作者通过实验观察到UTNet相对于最先进方法具有卓越分割性能和鲁棒性,有望在其他医学图像分割上很好地泛化。
2本文方法
2.1 Self-Attention机制的回顾
这里就不进行过多的描述了,前面关于Transformer的文章中已经说过很多次了,这里直接贴出Self-Attention的计算公式吧:
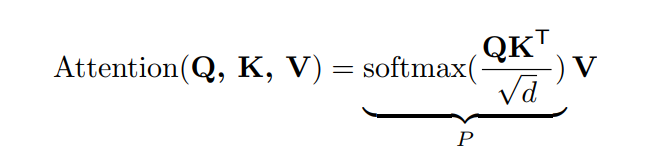
具体细节大家可以参考下面文章的内容:即插即用|卷积与Self-Attention完美融合X-volution插入CV模型将带来全任务涨点。
2.2 Efficient Self-attention Mechanism
由于图像是高度结构化的数据,在局部足迹内的高分辨率特征图中,除边界区域外,大多数像素具有相似的特征。因此,对所有像素之间的注意力计算是非常低效和冗余的。
从理论角度来看,对于长序列,自注意力本质上是低秩的,这说明大部分信息集中在最大的奇异值上。受此启发,作者提出了一种有效的自注意机制,如图所示。
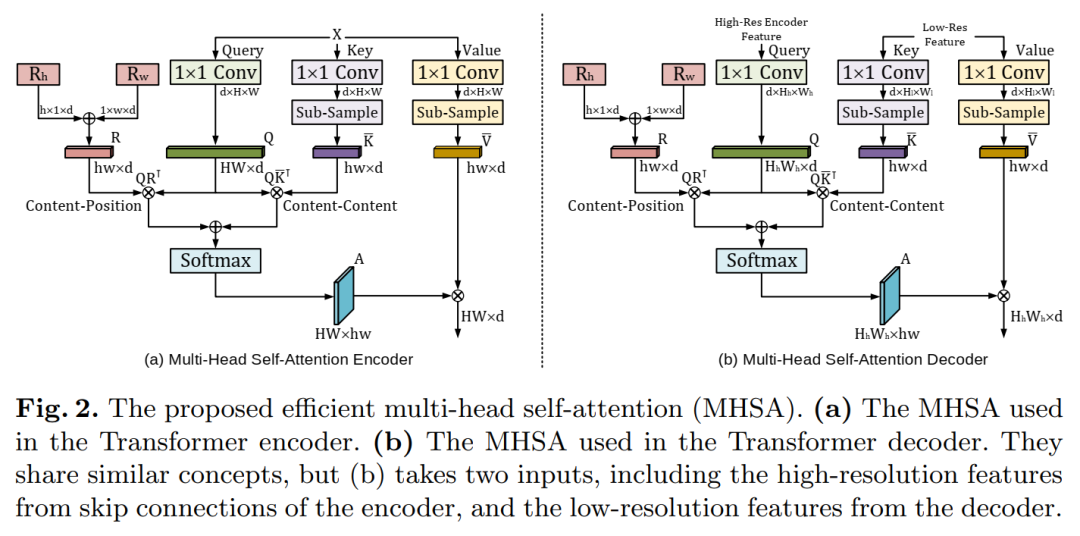
主要的想法是用2个投影来映射keys和values:
映射为低维度嵌入:
,其中k=hw<<n,h,并且w是经过sub-sampling后feature map缩小的尺寸。
efficient self-attention定义如下:
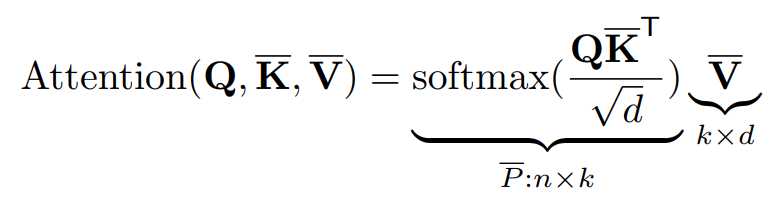
这样,计算复杂度降低到O(nkd)。值得注意的是,低维嵌入的投影可以是任何降采样操作,如平均/最大池化,或strided convolutions。在实现中使用1×1卷积和双线性插值来对特征图进行降采样,reduced size为8。
2.3 Relative Positional Encoding
标准的自注意力模块完全丢弃了位置信息,对于高度结构化的图像内容建模是无效的。以往的研究中的正弦嵌入在卷积层中不具有平移等方差的性质。
因此,作者通过采用了二维相对位置编码添加相对高度和宽度信息。在像素
和像素
:
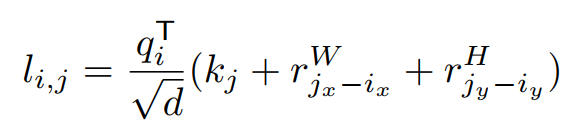
其中
为像素
的query向量,
为像素
的key向量,
和
分别为相对宽度
和相对高度
的可学习嵌入。与efficient self-attention相似,相对宽度和高度是在低维投影后计算的。包含相对位置嵌入的efficient self-attention为:
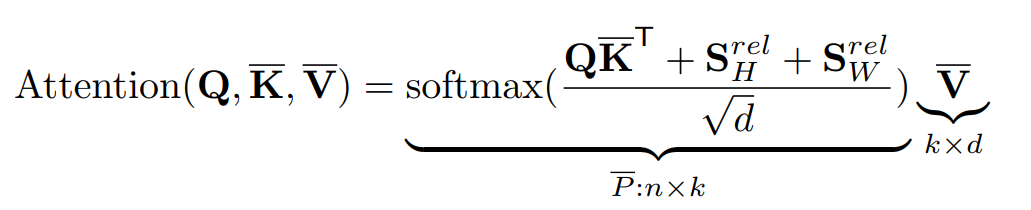
式中,是满足的沿高度和宽度尺寸的相对位置对数矩阵。
2.4 Network Architecture
如图,作者试图将卷积和自注意机制结合在一起。因此,混合架构可以利用卷积图像的归纳偏差来避免大规模的预训练,以及Transformer捕获远距离关系的能力。
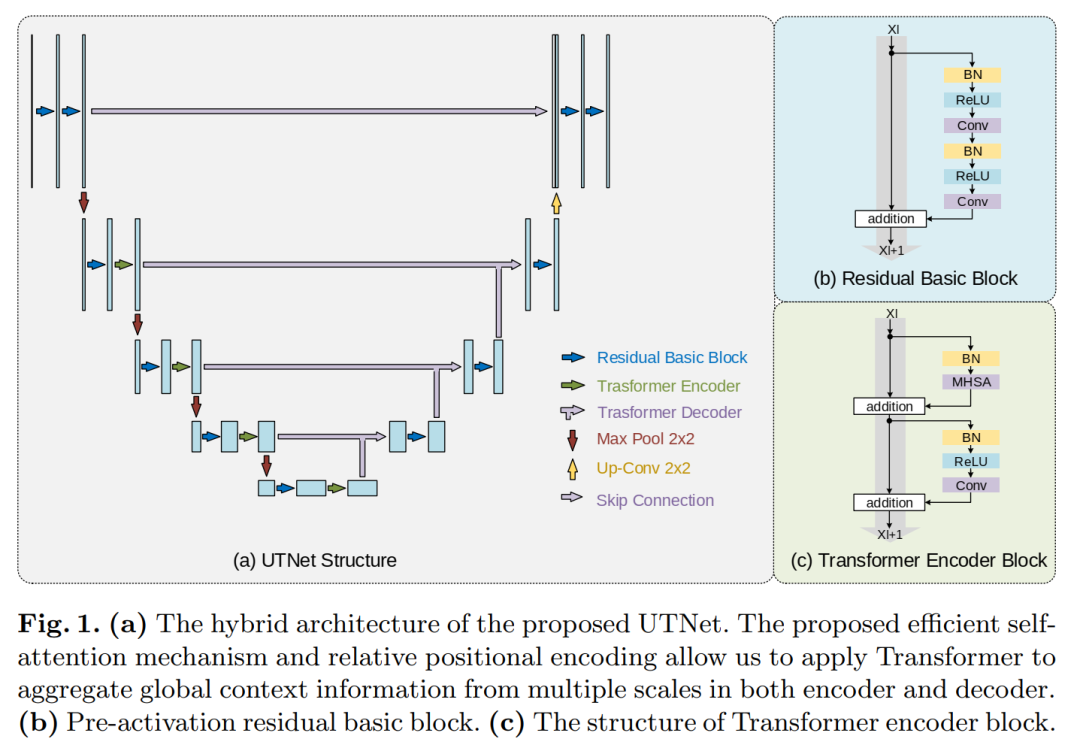
由于错误分割区域通常位于感兴趣区域的边界,高分辨率上下文信息在分割过程中起着至关重要的作用。因此,作者将重点放在提出的自注意模块上,使其能够有效地处理大尺寸特征地图。
3实验
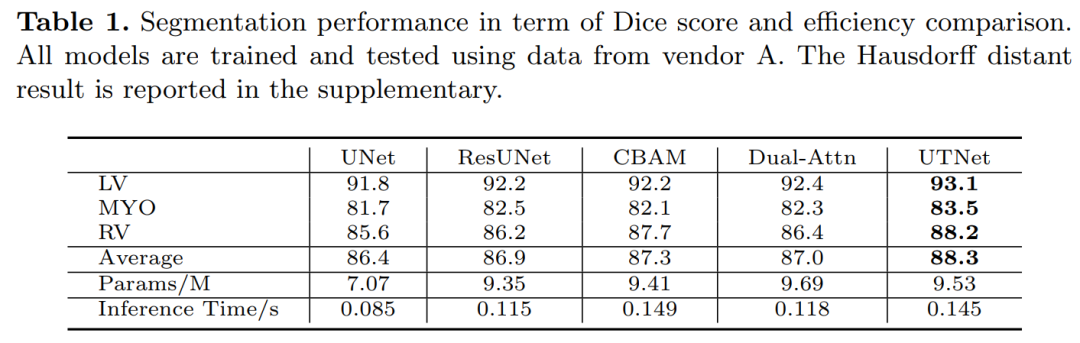
3.1 SOTA结果
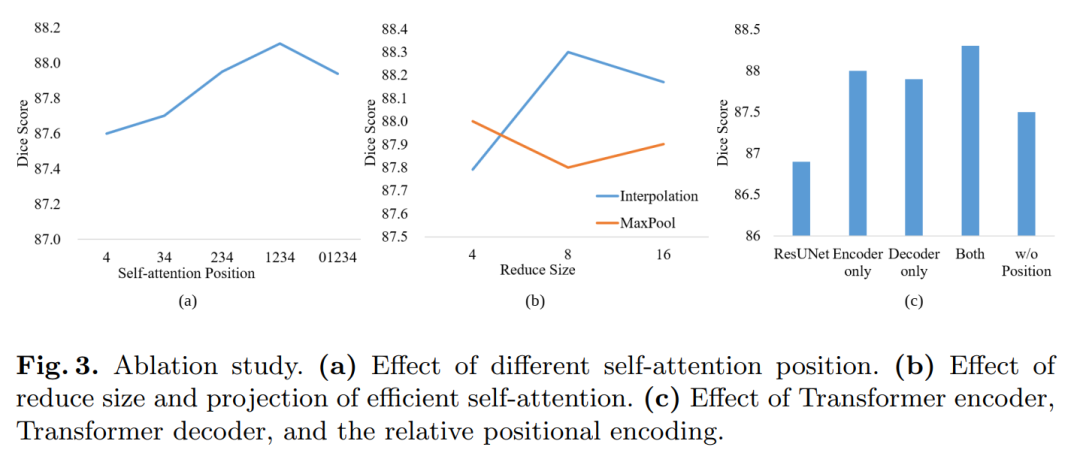
3.2 消融实验
3.3 可视化结果
4参考
[1].UTNet: A Hybrid Transformer Architecture for Medical Image Segmentation
5推荐阅读

简单有效 | 详细解读Interflow用注意力机制将特征更好的融合(文末获取论文)

详细解读PVT-v2 | 教你如何提升金字塔Transformer的性能?(附论文下载)

详细解读 | CVPR 2021轻量化目标检测模型MobileDets(附论文下载)
本文论文原文获取方式,扫描下方二维码
回复【UTNet】即可获取论文
长按扫描下方二维码添加小助手并加入交流群,群里博士大佬云集,每日讨论话题有目标检测、语义分割、超分辨率、模型部署、数学基础知识、算法面试题分享的等等内容,当然也少不了搬砖人的扯犊子
长按扫描下方二维码添加小助手。
可以一起讨论遇到的问题
声明:转载请说明出处
扫描下方二维码关注【集智书童】公众号,获取更多实践项目源码和论文解读,非常期待你我的相遇,让我们以梦为马,砥砺前行!
