
ECCV2020图像分割开源论文合集

极市导读
本文整理了ECCV2020目前开源的分割方向的全部论文,涵盖实例分割、语义分割、点云分割、目标跟踪与分割以及视频目标分割等多个方向,并对每一篇论文进行了简要介绍,文末附论文打包下载。
实例分割
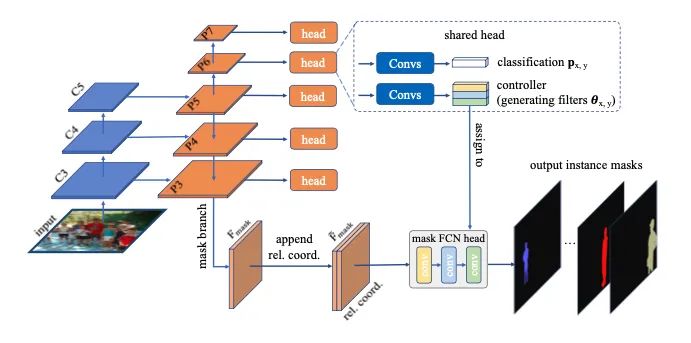
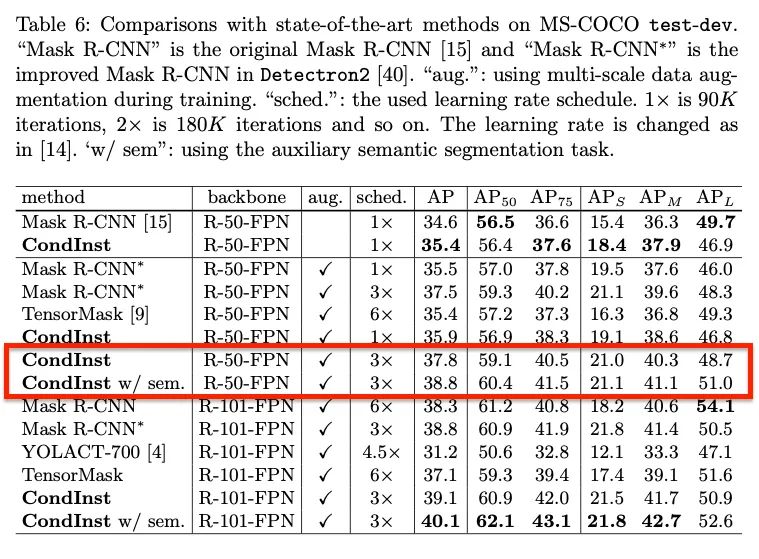
【1】Conditional Convolutions for Instance Segmentation(Oral)
作者|Zhi Tian, Chunhua Shen, Hao Chen
机构|阿德莱德大学
代码|https://git.io/AdelaiDet
介绍:本文提出了一个简单而有效的实例分割框架CondInst。效果最好的实例分割方法(例如Mask R-CNN)依靠ROI操作(比如ROIPool或ROIAlign)来获取最终的实例掩码。相反,本文从新的角度解决实例分割问题。采用基于实例的动态实例感知网络替代以ROI作为固定权重网络的输入。CondInst具有两个优点:(1)通过全卷积网络进行实例分割,无需进行ROI裁剪和特征对齐;(2)由于动态生成条件卷积的能力大大提高,因此mask head可以非常紧凑(例如3个卷积层,每个仅具有8个通道),从而获得明显更快inference。该方法在准确性和inference速度上都实现更高的性能。
【2】Fashionpedia: Ontology, Segmentation, and an Attribute Localization Dataset
作者|Menglin Jia, Mengyun Shi, Mikhail Sirotenko, Yin Cui, Claire Cardie , Bharath Hariharan, Hartwig Adam, Serge Belongie
机构|康奈尔大学;谷歌
代码|https://fashionpedia.github.io/home/
本文专注于具有属性本地化的实例分割任务,统一了实例分割和细粒度属性的可视分类。建议的任务既需要定位对象,又需要描述其属性。Fashionpedia由两部分组成:(1)由时尚专家建立的本体,包含27个主要服装类别,19个服装部件以及294个细粒度属性及其关系;(2)由日常和名人事件时尚图片组成的数据集细分蒙版及其相关的细粒度属性。本文提出了一种新颖的Attribute-Mask R-CNN模型来联合执行实例分割和局部属性识别,并为任务提供了一种新颖的评估指标。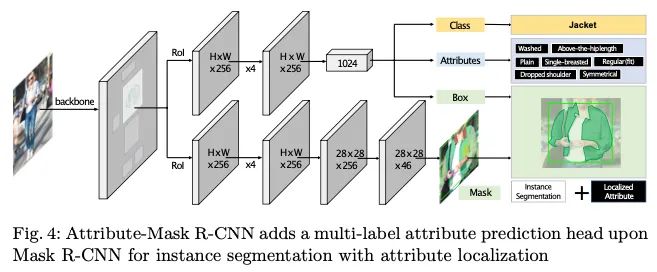
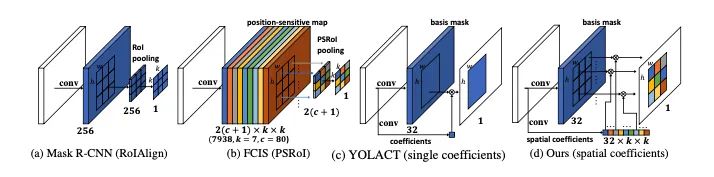
【3】SipMask: Spatial Information Preservation for Fast Image and Video Instance Segmentation
作者|Jiale Cao, Rao Muhammad Anwer, Hisham Cholakkal, Fahad Shahbaz Khan, Yanwei Pang, Ling Shao
机构|天津大学;Mohamed bin Zayed University of Artificial Intelligence;Inception Institute of Artificial Intelligence
代码|https://github.com/JialeCao001/SipMask
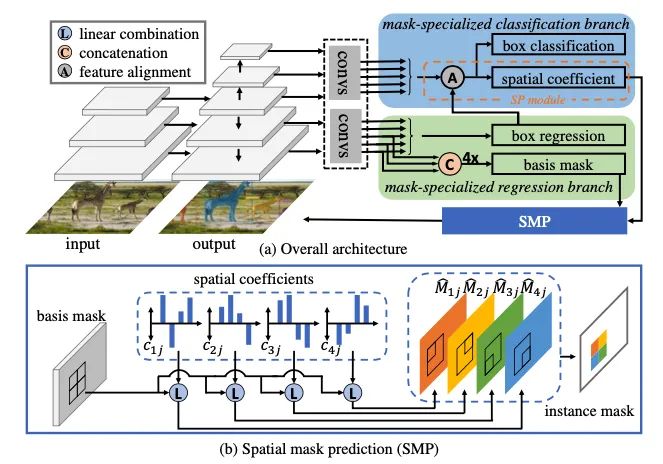
介绍:本文提出了一种快速单阶段实例分割方法SipMask,通过将实例的蒙版预测与检测到的边界框的不同子区域分开来保留实例特定的空间信息。提出了一个新颖的轻量级空间保存(SP)模块,为边界框内的每个子区域生成单独的一组空间系数,从而改善了蒙版预测。它还可以精确描绘空间上相邻的实例。此外,我们引入了蒙版对齐权重损失和特征对齐方案,以更好地将蒙版预测与对象检测相关联。在COCO上,SipMask优于现有的单阶段方法。与最先进的单级TensorMask相比,SipMask的绝对增益为1.0%(mask AP),同时提供了四倍的加速比。就实时功能而言,在类似的设置下,SipMask的绝对增益要优于YOLACT,其绝对增益为3.0%(mask AP),而在Titan Xp上以可比的速度运行。将SipMask用于实时视频实例分割,在YouTube-VIS数据集上取得了不错的结果。
【4】Commonality-Parsing Network across Shape and Appearance for Partially Supervised Instance Segmentation
作者|Qi Fan, Lei Ke, Wenjie Pei, Chi-Keung Tang, Yu-Wing Tai
机构|香港科技大学;哈尔滨工业大学深圳研究院
代码|https://github.com/fanq15/CPMask
介绍:部分监督实例分割旨在对有限的带掩码注释的数据类别执行学习,从而消除昂贵且详尽的掩码注释。现有方法通常采用学习从检测到分割的传递函数,或学习用于对新颖类别进行分割的聚类形状先验的方式。本文则建议学习潜在的与类无关的共性,这些共性可以从带掩码的类别扩展到新颖的类别。具体来说,本文分析两种类型的共性:1)通过对实例边界预测执行监督学习而获得的形状共性;2)通过对特征图像素之间的成对亲和力建模来捕获外观共同性,以优化实例与背景之间的可分离性。结合形状和外观的共性,本文模型在部分监督设置和小样本设置方面均明显优于最新方法。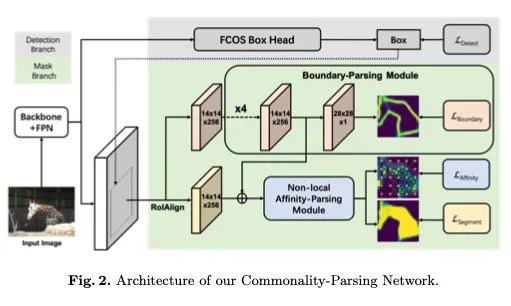
【5】The Devil is in Classification: A Simple Framework for Long-tail Instance Segmentation
作者|Tao Wang, Yu Li, Bingyi Kang, Junnan Li, Junhao Liew, Sheng Tang, Steven Hoi, Jiashi Feng
机构|新加坡国立大学;中国科学院计算技术研究所
代码|https://github.com/twangnh/SimCal
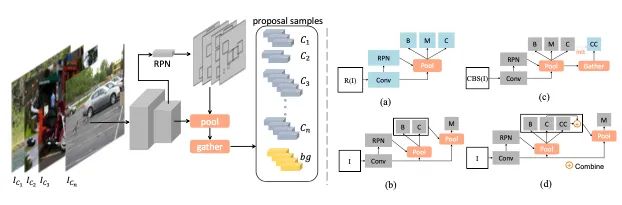
介绍:大多数现有的对象实例检测和细分模型只能在相当均衡的基准上很好地工作,而在长尾的现实数据集中出现性能下降。本文系统地研究了最新的two-stage实例分割模型Mask R-CNN在长尾LVIS数据集上的性能下降,并揭示主要原因:object proposals的分类不正确。因此本文考虑了各种用于改善长尾分类性能的技术,可以增强实例分割结果。本文提出了一个简单的校准框架,以采用双层类平衡采样方法更有效地减轻分类头偏差,极大地提高了在LVIS数据集和文章采样的COCO-LT数据集上尾类的实例分割性能。
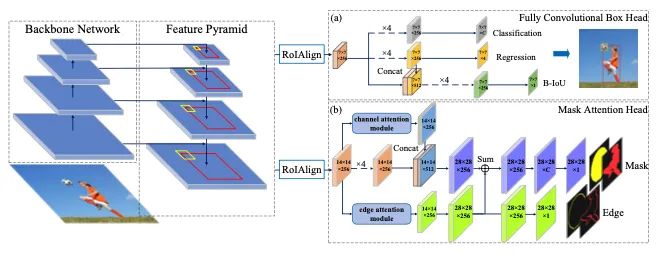
【6】Supervised Edge Attention Network for Accurate Image Instance Segmentation
作者|Xier Chen, Yanchao Lian, Licheng Jiao, Haoran Wang, YanJie Gao, Shi Lingling
机构|西安电子科技大学
代码|https://github.com//IPIU-detection/SEANet
介绍:有效地保持蒙版边界完整对实例分割很重要。在此任务中,许多工作片段实例都是基于框头的边界框,这意味着检测的质量也会影响蒙版的完整性。为了解决这个问题,本文提出了一个完全卷积的box head和一个在mask head中的监督边缘注意模块。box head包含一个新的IoU预测分支。它学习对象特征和检测到的边界框之间的关联,以提供更准确的边界框进行分割。边缘关注模块利用关注机制来突出对象并抑制背景噪声,并设计了一个有监督的分支来引导网络精确地关注实例的边缘。
语义分割
【7】Unsupervised Domain Adaptation for Semantic Segmentation of NIR Images through Generative Latent Search
作者|Prashant Pandey, Aayush Kumar Tyagi, Sameer Ambekar, Prathosh AP
机构|印度理工学院
代码|https://github.com/ambekarsameer96/GLSS
介绍:本文将皮肤分割问题归结为与目标无关的无监督域自适应(UDA)问题,使用来自可见范围红色通道的数据来开发NIR图像上的皮肤分割算法。提出一种与目标无关的分割方法,在源域中搜索目标图像的“最近克隆”并将其用作仅在源域上训练的分割网络中的代理。本文证明了“最近克隆”的存在,并提出了一种基于变分推理的深度生成模型潜在空间上的优化算法。通过NIR域中两个新创建的皮肤分割数据集上的最新UDA分割方法,证明了NIR皮肤分割方法的有效性。
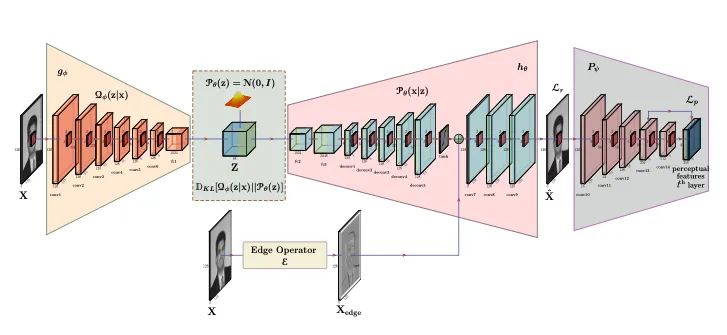
【8】Classes Matter: A Fine-grained Adversarial Approach to Cross-domain Semantic Segmentation
作者|Haoran Wang, Tong Shen, Wei Zhang, Ling-Yu Duan, Tao Mei
机构|ETH;京东;北京大学
代码|https://github.com/JDAI-CV/FADA
介绍:尽管在监督语义分割方面取得了很大进展,但在野外部署模型时通常会观察到性能大幅下降。域自适应方法通过对齐源域和目标域来解决此问题。但大多数现有方法忽略了目标域中底层的类级别数据结构。为了充分利用源域中的监督,本文提出了一种细粒度的对抗学习策略,用于类级别的特征对齐,同时保留了跨域语义的内部结构。本文所提出的方法在三个经典领域适应任务上进行了有效性评估,即GTA5 Cityscapes, SYNTHIA Cityscapes, Cityscapes Cross-City。性能的大幅提高表明该方法优于其他基于全局特征对齐和基于类对齐的对应方法。
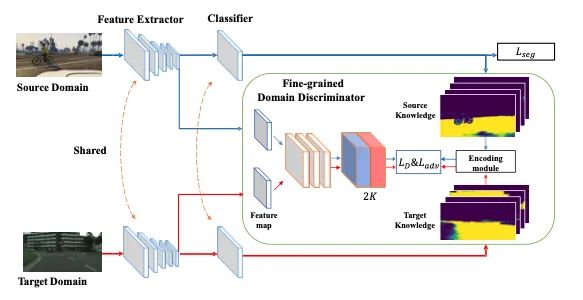
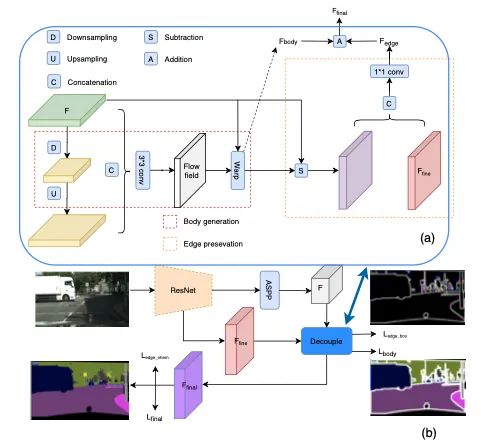
【9】Improving Semantic Segmentation via Decoupled Body and Edge Supervision
作者|Xiangtai Li, Xia Li, Li Zhang, Guangliang Cheng, Jianping Shi, Zhouchen Lin, Shaohua Tan, Yunhai Tong
机构|北京大学;之江实验室;哈佛大学;商汤科技
代码|https://github.com/lxtGH/DecoupleSegNets
介绍:本文提出了一种语义分割的新范式。通过学习流场使图像特征变形,以使对象部分更加一致。通过显式采样不同部分(身体或边缘)像素,在去耦监督下进一步优化了生成的身体特征和残留边缘特征。我们表明,具有各种基准或骨干网络的建议框架可获得更好的对象内部一致性和对象边界。在包括Cityscapes,CamVid,KIITI和BDD在内的四个主要道路场景语义分割基准上的大量实验表明,本文提出的方法建立了新的技术水平,同时保持了较高的推理效率。
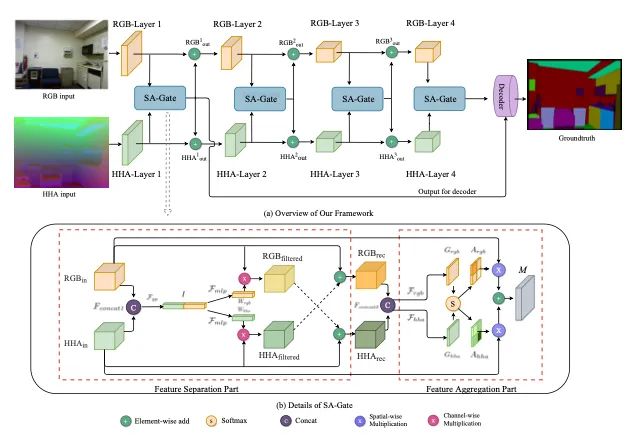
【10】Bi-directional Cross-Modality Feature Propagation with Separation-and-Aggregation Gate for RGB-D Semantic Segmentation
作者|Xiaokang Chen, Kwan-Yee Lin, Jingbo Wang, Wayne Wu, Chen Qian, Hongsheng Li, Gang Zeng
机构|北京大学;香港中文大学;商汤科技
代码|https://charlescxk.github.io/
介绍:深度信息是RGB-D图像语义分割中的有用提示,它可以为RGB表示提供几何上的对应。大多数现有工作仅假设深度测量准确且与RGB像素良好对齐,并将该问题建模为交叉模式特征融合以获得更好的特征表示以实现更准确的分割。但是,这可能不会导致令人满意的结果,因为实际的深度数据通常比较嘈杂,这可能会随着网络的深入而降低准确性。本文提出了一个统一而有效的跨模态引导编码器,不仅可以有效地重新校准RGB特征响应,还可以通过多个阶段提取准确的深度信息,并交替汇总两个重新校准的表示。本文提出的体系结构的关键是新颖的“分离与聚合门控”操作,该操作在交叉模态聚合之前共同过滤和重新校准两种表示形式。同时,一方面引入了双向多步传播策略,以帮助在两种模态之间传播和融合信息,另一方面,在长期传播过程中保持它们的特异性。此外,本文提出的编码器可以轻松地注入到以前的编码器-解码器结构中,以提高其在RGB-D语义分割上的性能。
点云分割
【11】SqueezeSegV3: Spatially-Adaptive Convolution for Efficient Point-Cloud Segmentation
作者|Chenfeng Xu, Bichen Wu, Zining Wang, Wei Zhan, Peter Vajda, Kurt Keutzer, Masayoshi Tomizuka
机构|加州大学伯克利分校;Facebook
代码|https://github.com/chenfengxu714/SqueezeSegV3
介绍:LiDAR点云分割是许多应用程序中的重要问题。对于大规模点云分割,常见方法是投影3D点云以获得2D LiDAR图像并使用卷积对其进行处理。尽管常规RGB和LiDAR图像之间存在相似之处,本文首次发现LiDAR图像的特征分布在不同图像位置会急剧变化。由于卷积滤波器会拾取仅在图像中特定区域有效的局部特征,因此使用标准卷积来处理此类LiDAR图像存在问题,将导致网络的容量未得到充分利用,分割性能下降。为了解决这一问题,本文采用空间自适应卷积(SAC)根据输入图像对不同位置采用不同的滤波器。并使用SAC构建了用于LiDAR点云分割的SqueezeSegV3,在SemanticKITTI基准上以至少2.0%的mIoU优于所有先前发布的方法。
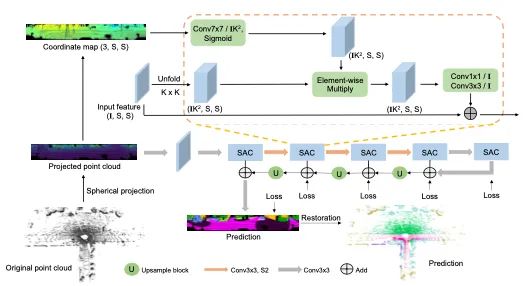
目标跟踪与分割
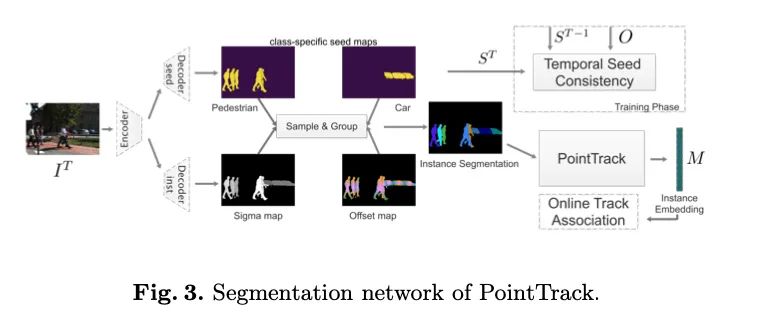
【12】Segment as Points for Efficient Online Multi-Object Tracking and Segmentation(Oral)
作者|Zhenbo Xu, Wei Zhang, Xiao Tan, Wei Yang, Huan Huang, Shilei Wen, Errui Ding, Liusheng Huang
机构|中国科学技术大学;百度
代码|https://github.com/detectRecog/PointTrack
简介:当前的多目标跟踪和分割方法遵循“tracking-by-detection”范例,并采用卷积进行特征提取。受固有感受野影响,基于卷积的特征提取不可避免地将前景特征和背景特征混合在一起,从而在后续实例关联中产生歧义。本文提出了一种有效的方法:将紧凑的图像表示转换为无序的2D点云表示,从而基于分割学习实例嵌入。此外,多种信息数据模态被转换为点状表示,以丰富点状特征。PointTrack以接近实时的速度(22 FPS)大大超越了所有最新技术,包括3D跟踪(MOTSA高5.4%,MOTSFusion快18倍) )。与此同时,本文针对目前MOTS数据集缺少拥挤场景的问题,构建了一个具有更高实例密度的MOTS数据集:APOLLO MOTS。
视频目标分割
【13】Learning What to Learn for Video Object Segmentation
作者|Goutam Bhat, Felix Järemo Lawin, Martin Danelljan, Andreas Robinson, Michael Felsberg, Luc Van Gool, Radu Timofte
机构|ETH;Linko ̈ping University
代码|https://github.com/visionml/pytracking
介绍:视频对象分割(VOS)是一个极富挑战性的问题,因为目标对象仅在推理过程中由第一帧参考掩码定义。如何捕获和利用这些有限的信息来准确地分割目标的问题仍然是一个基础研究问题。为了解决这个问题,本文引入端到端可训练的VOS架构,集成了可区分小样本学习器。旨在通过最小化第一帧中的分割误差来预测目标的强大参数模型。该方法在大规模YouTube-VOS 2018数据集上获得了81.5的总得分,相对过去的最佳结果提高了2.6%。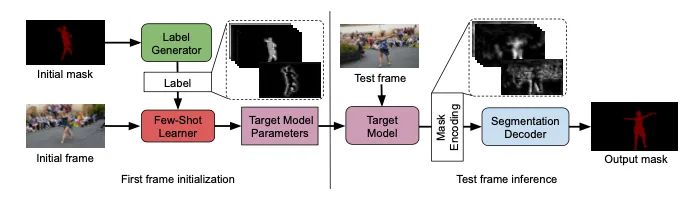
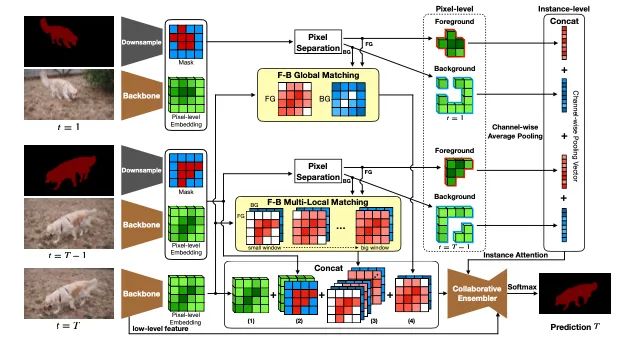
【14】Collaborative Video Object Segmentation by Foreground-Background Integration
作者|Zongxin Yang, Yunchao Wei, Yi Yang
机构|悉尼科技大学;百度
代码|https://github.com/z-x-yang/CFBI
介绍:本文研究了嵌入学习的原理,以解决具有挑战性的半监督视频对象分割。与仅使用前景对象的像素探索嵌入学习的以前的做法不同,本文认为应该同等对待背景,因此建议使用前景背景集成(CFBI)方法进行协作视频对象分割。CFBI隐式强加了从目标前景对象及其对应的背景中嵌入的特征以进行对比,从而相应地提高了分割结果。通过前景和背景的嵌入,CFBI可以在像素和实例水平上执行参考序列与预测序列之间的匹配过程,从而使CFBI能够适应各种对象比例。在DAVIS 2016,DAVIS 2017和YouTube-VOS进行实验,CFBI的性能(J&F)分别达到89.4%,81.9%和81.4%,优于其他所有最新技术。
【15】URVOS: Unified Referring Video Object Segmentation Network with a Large-Scale Benchmark
作者|Seonguk Seo, Joon-Young Lee, Bohyung Han
机构|首尔大学;Adobe
代码|https://github.com/skynbe/Refer-Youtube-VOS
介绍:本文提出了一个统一的参照视频目标分割网络(URVOS)。URVOS将视频和引用表达式作为输入,并估计整个视频帧中给定语言表达式引用的对象蒙版。通过使用单个深层神经网络以及两个注意模型的适当组合,共同执行基于语言的对象分割和掩码传播,解决了具有挑战性的问题。此外,本文构建了第一个大规模的参考视频目标分割数据集Refer-Youtube-VOS。
打包下载
推荐阅读
七夕“CV侠侣”的投票活动圆满结束,获奖名单如下:
人气第一名-七夕最具人气“CV侠侣”:03号,枫叶寻寻获得拍立得一部
人气第二名-七夕最具人气“CV侠侣”:08号,丛晓峰获得星空灯一个
人气第三名-七夕最具人气“CV侠侣”:07号,你的答案获得定制马克杯一对
优质投稿奖-七夕最具创意“CV侠侣”:01号,晨风获得智能蓝牙投影键盘一个
祝贺以上获奖选手,感谢大家积极参与,一起期待极市的下次福利活动吧!
