BERT是图像预训练未来?字节跳动iBOT刷新十几项SOTA,部分指标超MAE
机器之心编辑部
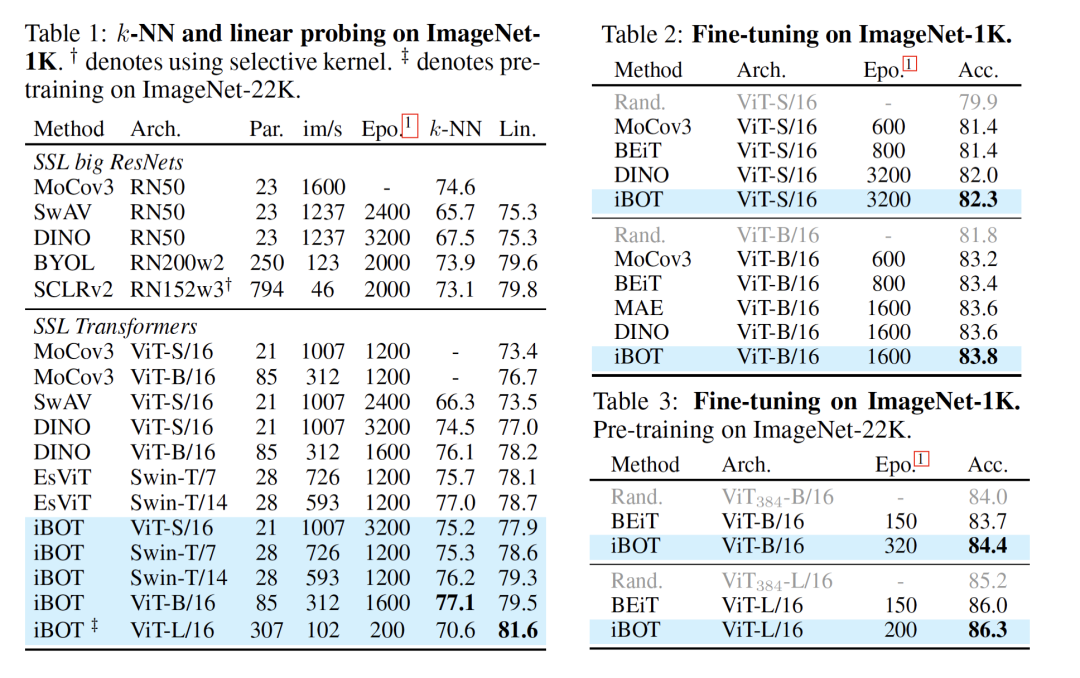
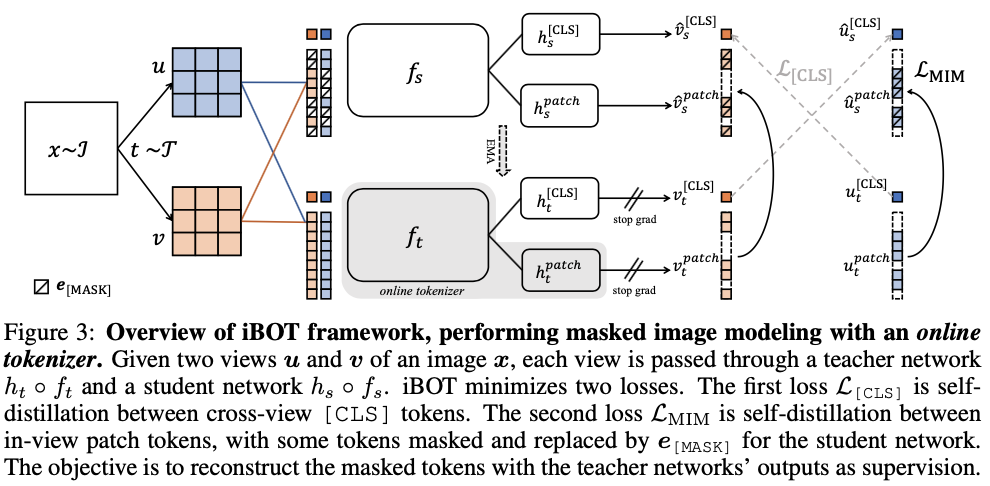
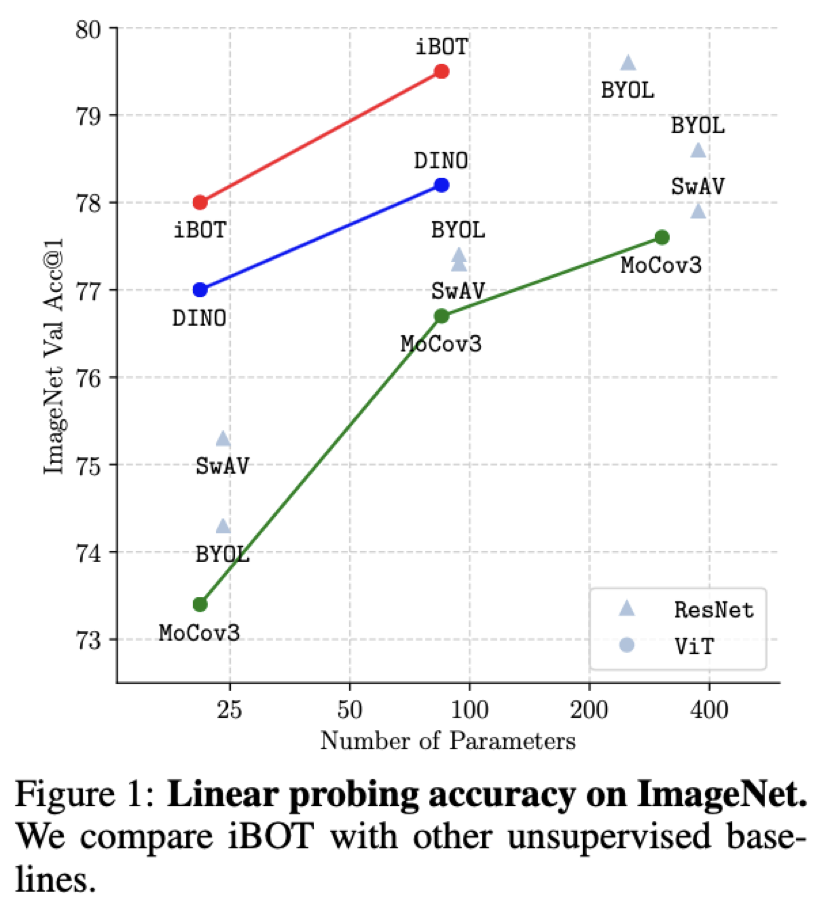
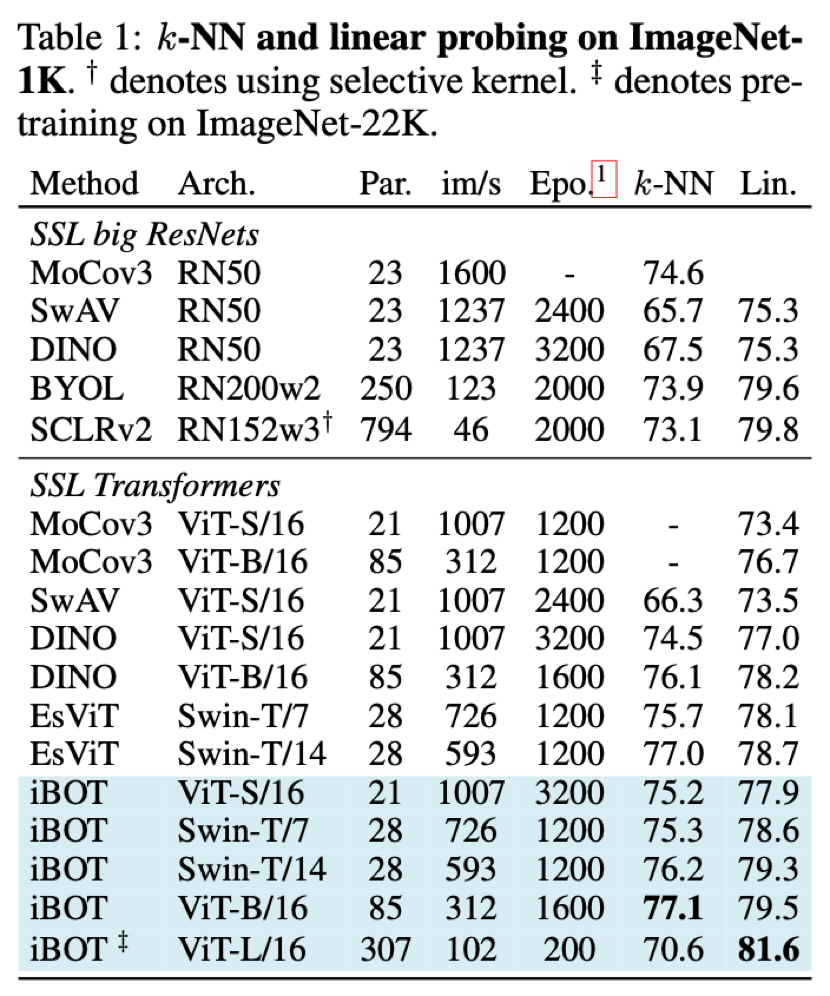
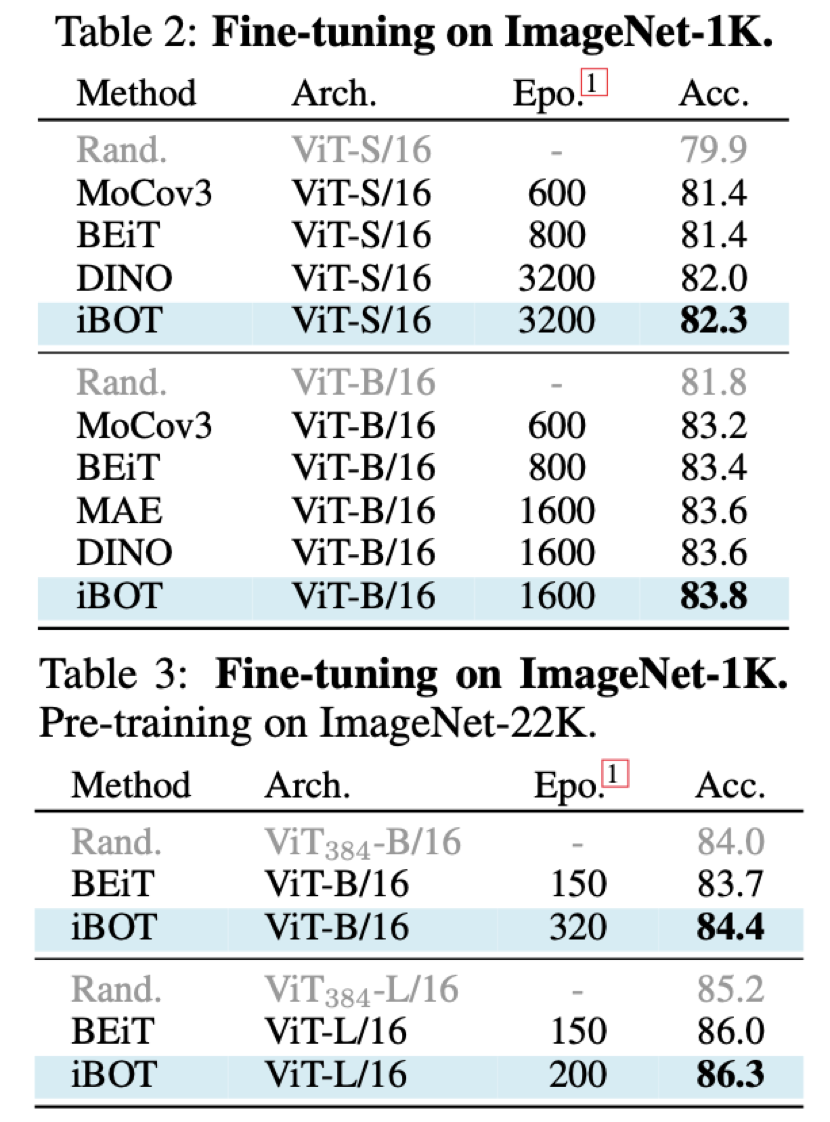
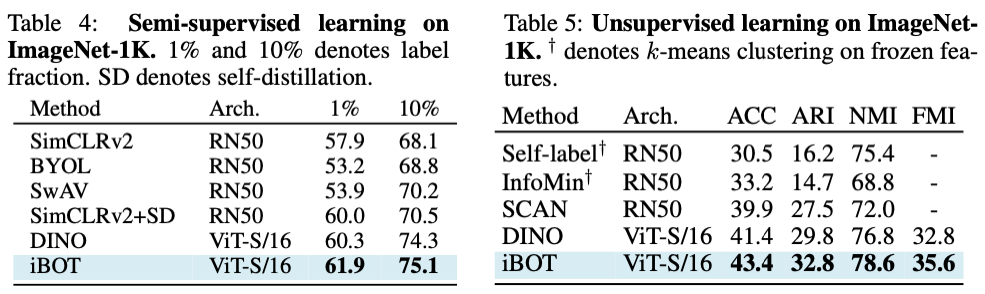
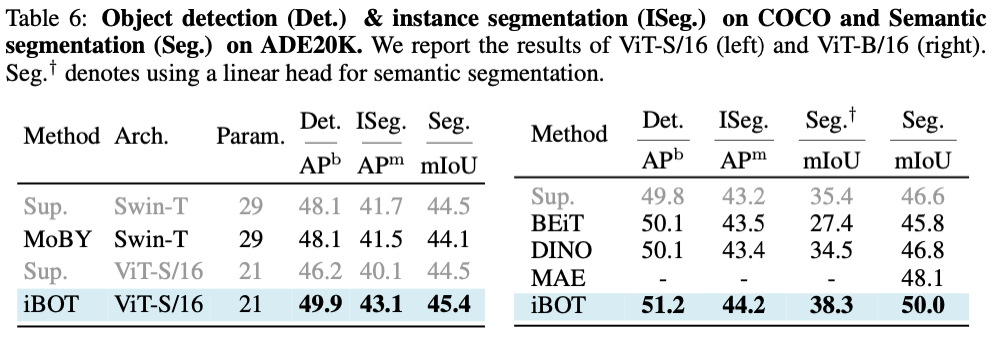
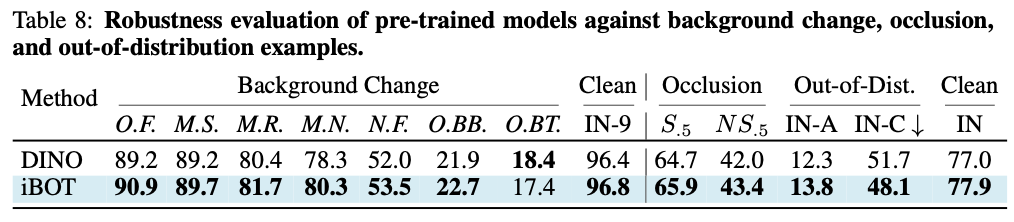
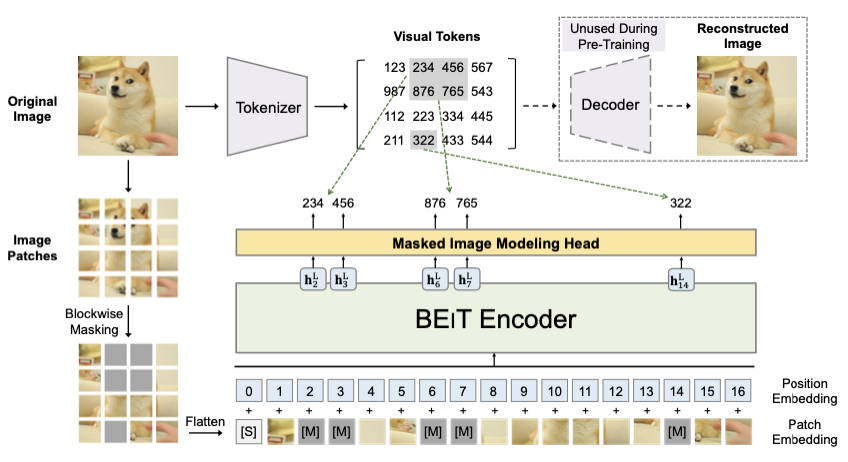
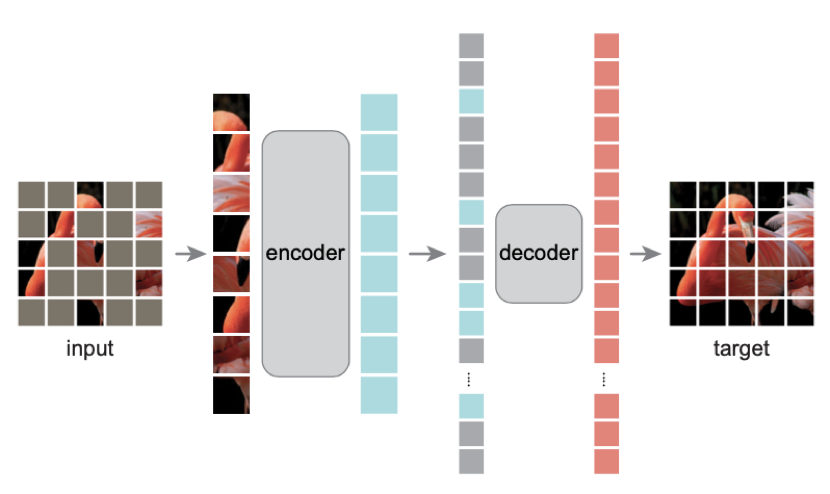
这个新方法在十几类任务和数据集上刷新了 SOTA 结果,在一些指标上甚至超过了 MAE。


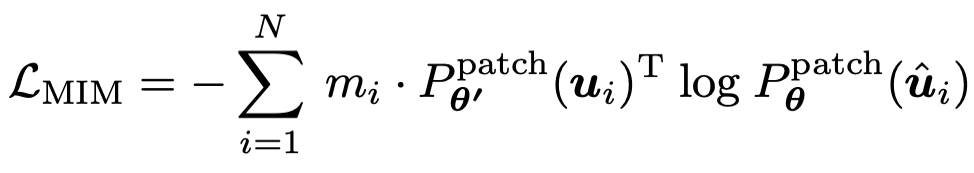

© THE END
转载请联系原公众号获得授权
投稿或寻求报道:content@jiqizhixin.com

点个在看 paper不断!
评论
 下载APP
下载APP机器之心编辑部
这个新方法在十几类任务和数据集上刷新了 SOTA 结果,在一些指标上甚至超过了 MAE。
© THE END
转载请联系原公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
点个在看 paper不断!