
PyTorch 51.BatchNorm和Dropout层的不协调现象
点击上方“视学算法”,选择加"星标"或“置顶”
重磅干货,第一时间送达
作者 | 科技猛兽@知乎(已授权)
来源 | https://zhuanlan.zhihu.com/p/276154597
编辑 | 极市平台
导读
本文从model.eval()和torch.no_grad()开始讲起,细说batchnorm 和dropout 层在训练和测试时的差别,最后详细阐述BN和Dropout共同使用时会出现的问题。
1 从model.eval()和torch.no_grad()开始讲起
这两个是不一样的:
model.eval() 主要是用在模型前向过程中,通过设置成eval 模型,告诉所有层你在 eval 模式,其中涉及到 batchnorm 和 dropout 层,这些层在训练和测试的表现是不一样的,比如 dropout 在训练中可能是0-1间的数,但在eval模式则为不使用dropout层。
torch.no_grad() 会关闭自动求导引擎的, 因此能节省显存,和加速。
model.train() 用于在训练阶段,model.eval()用在验证和测试阶段,他们的区别是对于Dropout和Batch Normlization层的影响。在train模式下,dropout网络层会按照设定的参数p设置保留激活单元的概率(保留概率=p); batchnorm层会继续计算数据的mean和var等参数并更新。在val模式下,dropout层会让所有的激活单元都通过,而batchnorm层会停止计算和更新mean和var,直接使用在训练阶段已经学出的mean和var值。
#训练阶段
for epoch in range(max_epoch):
model.train()
dataiter = iter(dataloader)
for step in range(step_per_epoch):
data= next(dataiter) #假设包含有 images,label数据
# 因为images ,labels是输入数据,我们可以使用with torch.no_grad()停止对他们的求导
# 当然不使用也是可以的,使用的化可以加快gpu速度和减少占有
with torch.no_grad():
images = data[0]
label = data[1]
#测试阶段
model.eval()
with torch.no_grad():
....
#在测试阶段使用with torch.no_grad()可以对整个网络都停止自动求导,可以大大加快速度,也可以使用大的batch_size来测试
#当然,也可以不使用with torch.no_grad
2 细说batchnorm 和 dropout 层在训练和测试时的差别
Batch Normalization
BN,Batch Normalization,就是在深度神经网络训练过程中使得每一层神经网络的输入保持相近的分布。
BN训练和测试时的参数是一样的嘛?
对于BN,在训练时,是对每一批的训练数据进行归一化,也即用每一批数据的均值和方差。
而在测试时,比如进行一个样本的预测,就并没有batch的概念,因此,这个时候用的均值和方差是全量训练数据的均值和方差,这个可以通过移动平均法求得。
对于BN,当一个模型训练完成之后,它的所有参数都确定了,包括均值和方差,gamma和bata。
BN训练时为什么不用全量训练集的均值和方差呢?
因为在训练的第一个完整epoch过程中是无法得到输入层之外其他层全量训练集的均值和方差,只能在前向传播过程中获取已训练batch的均值和方差。那在一个完整epoch之后可以使用全量数据集的均值和方差嘛?
对于BN,是对每一批数据进行归一化到一个相同的分布,而每一批数据的均值和方差会有一定的差别,而不是用固定的值,这个差别实际上也能够增加模型的鲁棒性,也会在一定程度上减少过拟合。
但是一批数据和全量数据的均值和方差相差太多,又无法较好地代表训练集的分布,因此,BN一般要求将训练集完全打乱,并用一个较大的batch值,去缩小与全量数据的差别。
Dropout
Dropout 是在训练过程中以一定的概率的使神经元失活,即输出为0,以提高模型的泛化能力,减少过拟合。
Dropout 在训练和测试时都需要吗?
Dropout 在训练时采用,是为了减少神经元对部分上层神经元的依赖,类似将多个不同网络结构的模型集成起来,减少过拟合的风险。
而在测试时,应该用整个训练好的模型,因此不需要dropout。
Dropout 如何平衡训练和测试时的差异呢?
Importantly, the test scheme is quite different from the train.
During training, the information flow goes through the dynamic sub-network. At test time, the neural responses are scaled by the Dropout retain ratio.
At test time for Dropout, one should scale down the weights by multiplying them by a factor of p. As introduced in (Srivastava et al., 2014), another way to achieve the same effect is to scale up the retained activations by multiplying by** **at training time and not modifying the weights at test time.
Dropout,在训练时以一定的概率使神经元失活,实际上就是让对应神经元的输出为0
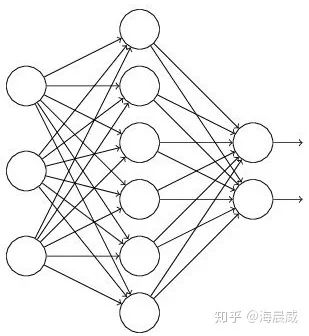
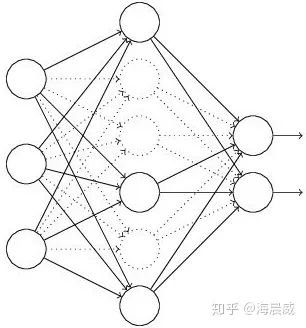
假设失活概率为 p ,就是这一层中的每个神经元都有p的概率失活,如下图的三层网络结构中,如果失活概率为0.5,则平均每一次训练有3个神经元失活,所以输出层每个神经元只有3个输入,而实际测试时是不会有dropout的,输出层每个神经元都有6个输入,这样在训练和测试时,输出层每个神经元的输入和的期望会有量级上的差异。
因此在训练时还要对第二层的输出数据除以(1-p)之后再传给输出层神经元,作为神经元失活的补偿,以使得在训练时和测试时每一层输入有大致相同的期望。
dropout部分参考:
https://blog.csdn.net/program_developer/article/details/80737724
3 进入正题,BN和Dropout共同使用时会出现的问题
BN和Dropout单独使用都能减少过拟合并加速训练速度,但如果一起使用的话并不会产生1+1>2的效果,相反可能会得到比单独使用更差的效果。
相关的研究参考论文:
https://arxiv.org/abs/1801.05134
接下来详细地解释一下这个问题:
我们假设你在Batch Normalization的时候有好多个mini-batch,这些mini-batch有各自的:
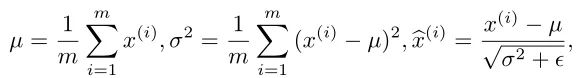
假设有B个吧。
我们把这B个mini-batch的 的期望值设为 。同样的道理,把这B个mini-batch的 的期望值设为 。
在训练的时候,当B每增加1时,我们就执行一次这样的赋值:
这样在前向传播时,BN的第一步就变成了:
Dropout在训练时有:
Dropout在测试时有:
我们假设:
则有训练时:
测试时:
你会发现算到这地方不一样了,这不一样代表什么含义呢?
在训练结束的时候,BN层会保存一个** ** ,它认为:
但是,在测试的时候:
这就有:
这就带来了严重的偏差。
于是1道面试题出来了:这个偏差的根源在哪里?
一句话:训练和测试的方差偏移(Variance Shift)。
更严重的是,这只是一层的偏差。随着网络的逐步加深,偏差会越来大。
而且,这个偏差是在测试时产生的,你的网络没法消除它!
怎么解决?
直接令 ,不用Dropout。相当于废话。
还可以怎么解决?本文给出了2种解法:
在所有 BN 层后使用 Dropout。因为Dropout是带来方差偏移的根本原因。 把Dropout改为一种更加稳定的形式。
具体是什么意思?
想办法做出一种Dropout,可以克服方差偏移。
当 很小的时候:
在训练的时候给每一个样本加上一个均匀分布在[0,1]之间的噪声,使得:
这样一来:
当 很小时, 。这个问题即得到解决。
其实对于这个问题的理解你看到这里就已经足够了,但是如果依然觉得意犹未尽的话下面还有一段:
其实上面我们分析的都是下图a的情况:
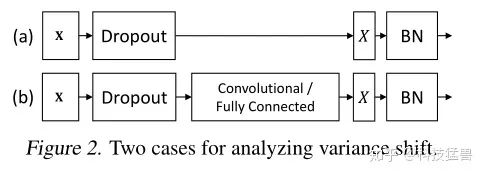
但实际上图b的情况更常见一些,那就再分析下图b,多了个全连接层:
和上一种情况的最大区别是什么?
就是 由1维的 ,1维的 变成了多维的 。这些 之间,这些 并不是独立的,这就意味着你需要求他们之间的协方差了。把 看做一个整体:
式中:
接下来我们分析测试时方差偏移成什么样子了:
式中:
现在应该把刚才算出来的这个 与 相除了。
但现在还缺少一个 与 的关系,这个关系并不难算:
所以: 。
现在计算:
式中,
若使得 ,则有:
:Dropout作用减小。
:全连接层channel增大。

如果觉得有用,就请分享到朋友圈吧!

点个在看 paper不断!