
从 ClickHouse 到 ByteHouse:实时数据分析场景下的优化实践
近日,字节跳动旗下的企业级技术服务平台火山引擎正式对外发布了 ByteHouse。在打造 ClickHouse 企业版 ByteHouse 的过程中,我们经过了多年的探索与沉淀,今天和大家分享字节跳动过去使用 ClickHouse 的两个典型应用于优化案例。
推荐系统实时指标
能同时查询聚合指标和明细数据; 能支持多达几百列的维度和指标,且场景灵活变化,会不断增加; 可以高效地按 ID 过滤数据; 需要支持一些机器学习和统计相关的指标计算(比如 AUC)。
能更快地观察算法模型,没有预计算所导致的高数据时延; ClickHouse 既适合聚合查询,配合跳数索引后,对于明细点查性能也不错; 字节自研的 ClickHouse 支持 Map 类型,支持动态变更的维度和指标,更加符合需求; BitSet 的过滤 Bloom Filter 是比较好的解决方案,ClickHouse 原生就有 BF 的支持; 字节自研的 ClickHouse 引擎已经通过 UDF 实现了相关的能力,而且有比较好的扩展性。

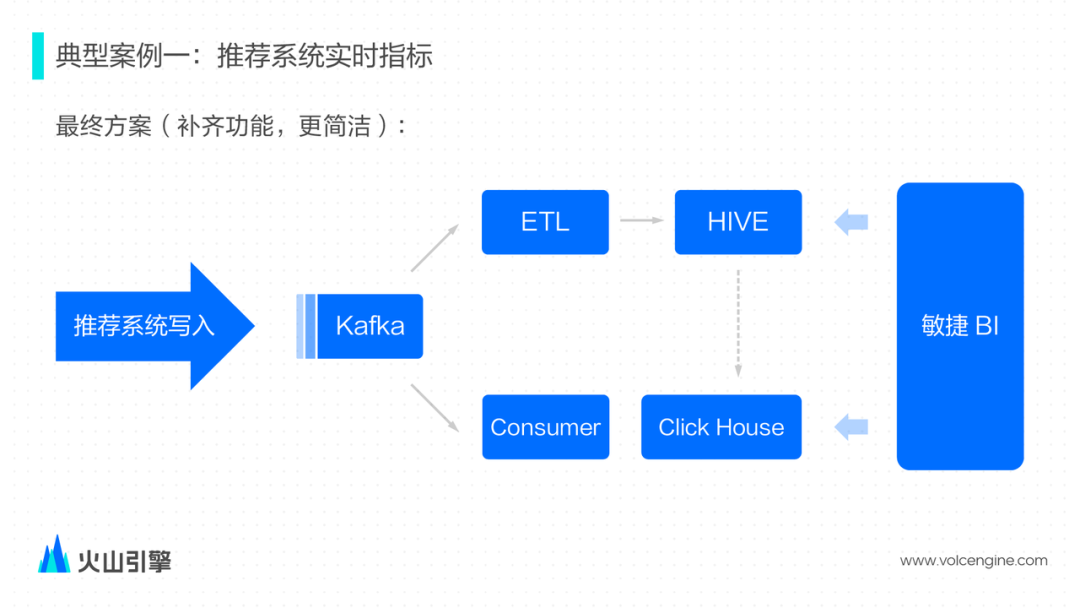
数据由推荐系统直接产生,写入 Kafka——为了弥补缺少 Flink 的 ETL 能力,推荐系统做了相应配合,修改 Kafka Topic 的消息格式直接适配 ClickHouse 表的 schema; 敏捷 BI 平台也适配了一下实时的场景,可以支持交互式的查询分析; 如果实时数据有问题,也可以从 Hive 把数据导入至 ClickHouse 中,除此之外,业务方还会将 1% 抽样的离线数据导入过来做一些简单验证,1% 抽样的数据一般会保存更久的时间。
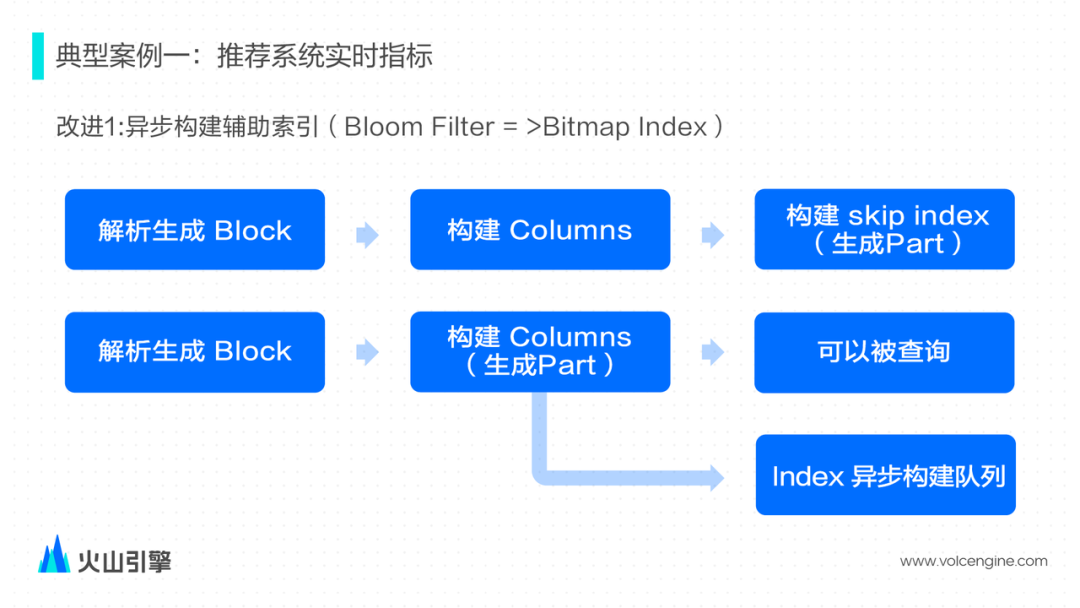
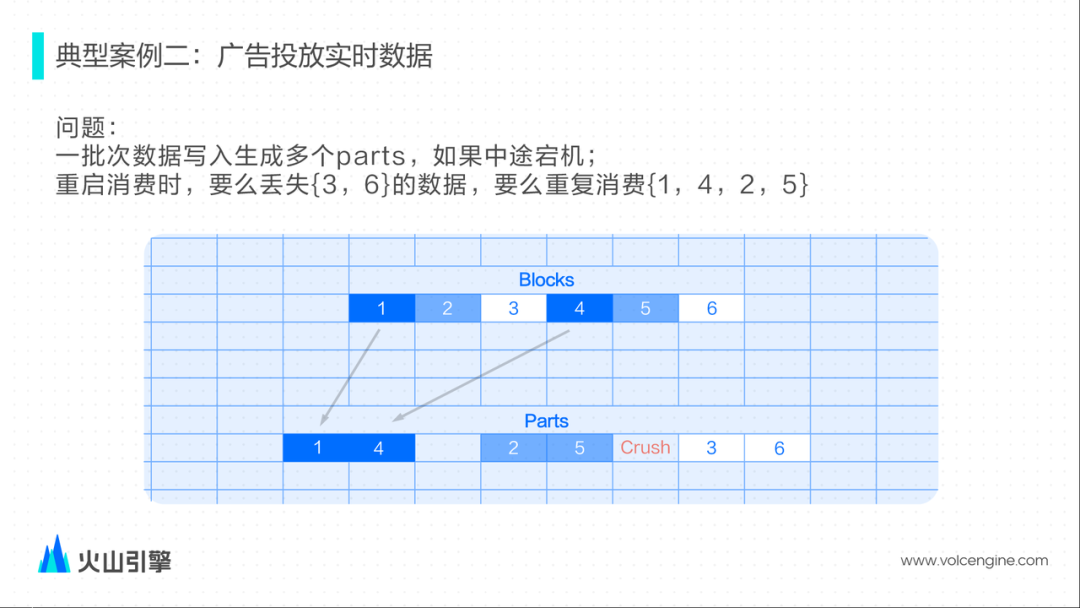
解析输入数据生成内存中数据结构的 Block; 然后切分 Block,并按照表的 schema 构建 columns 数据文件; 最后扫描根据 skip index schema 去构建 skip index 文件。三个步骤完成之后才会算 Part 文件构建完毕。
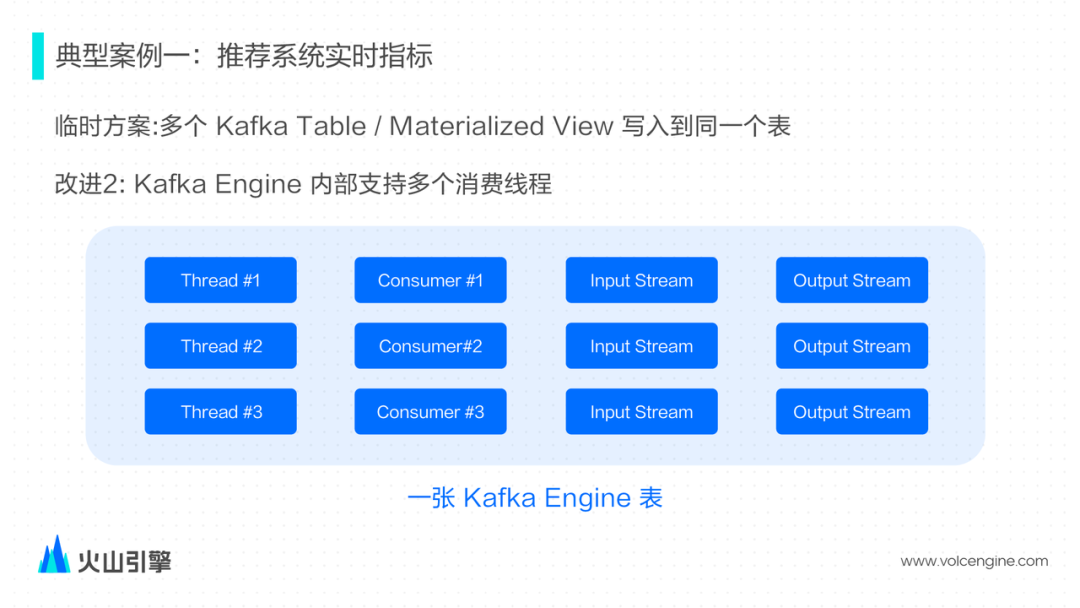
尝试通过增大消费者的个数来增大消费能力,但社区的实现是由一个线程去管理多个的消费者,多个消费者消费到的数据最后仅能由一个输出线程完成数据构建,所以这里没能完全利用上多线程和磁盘的潜力; 尝试通过创建多张 Kafka Table 和 Materialized View 写入同一张表,但是对于运维会比较麻烦。
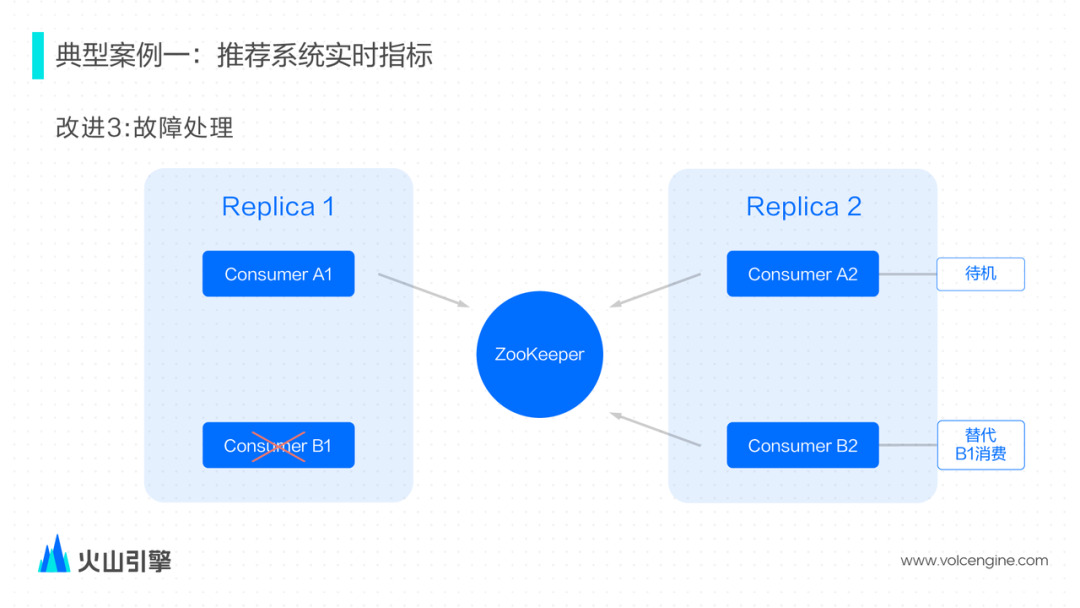
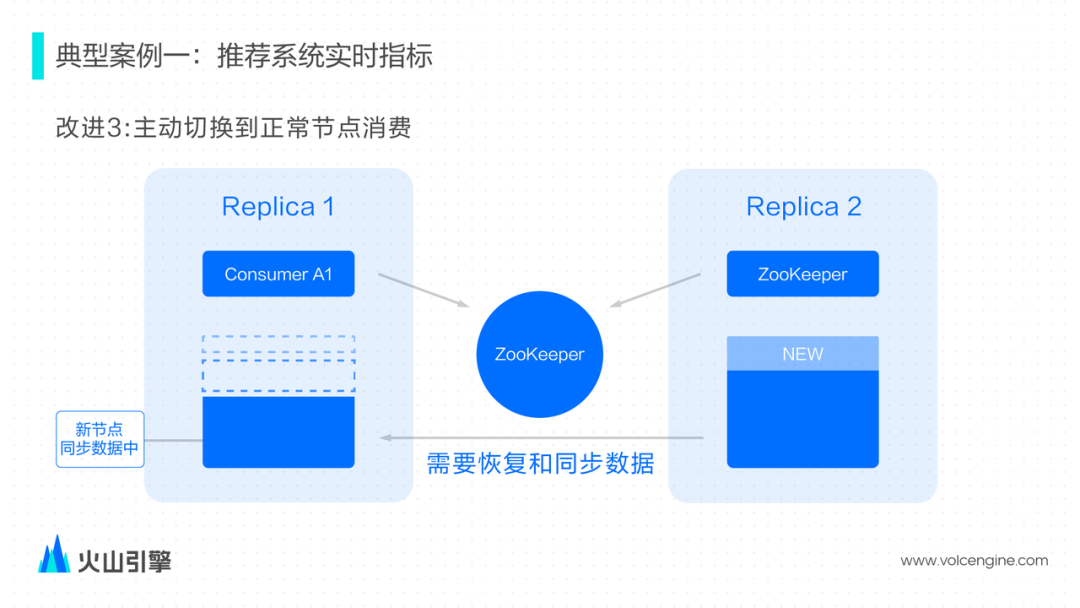
解决方案:确保主备模式下只会写入一个主备其中一个节点。
广告投放实时数据

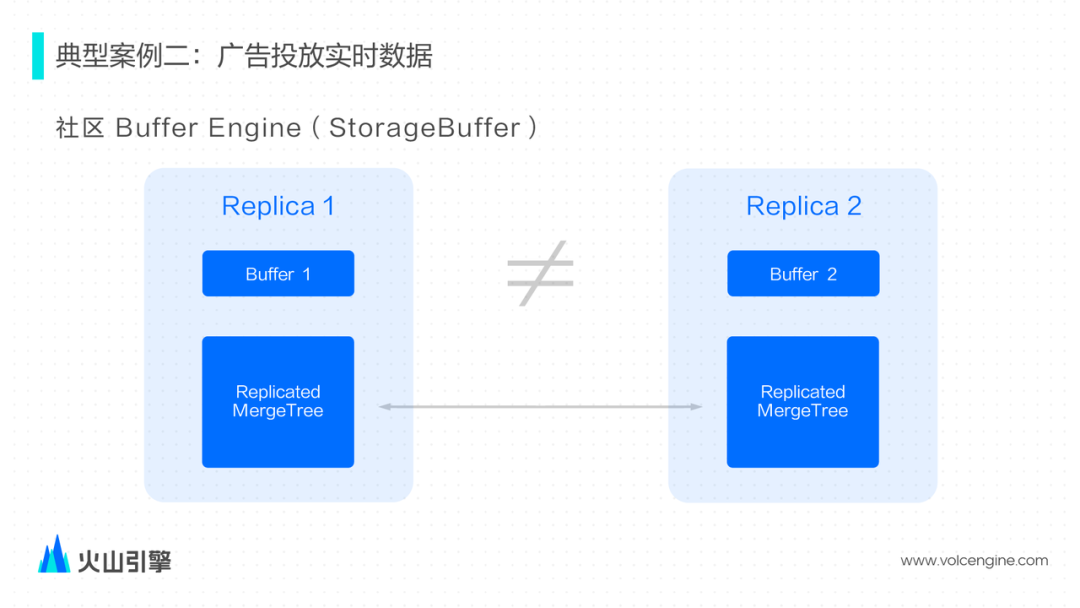
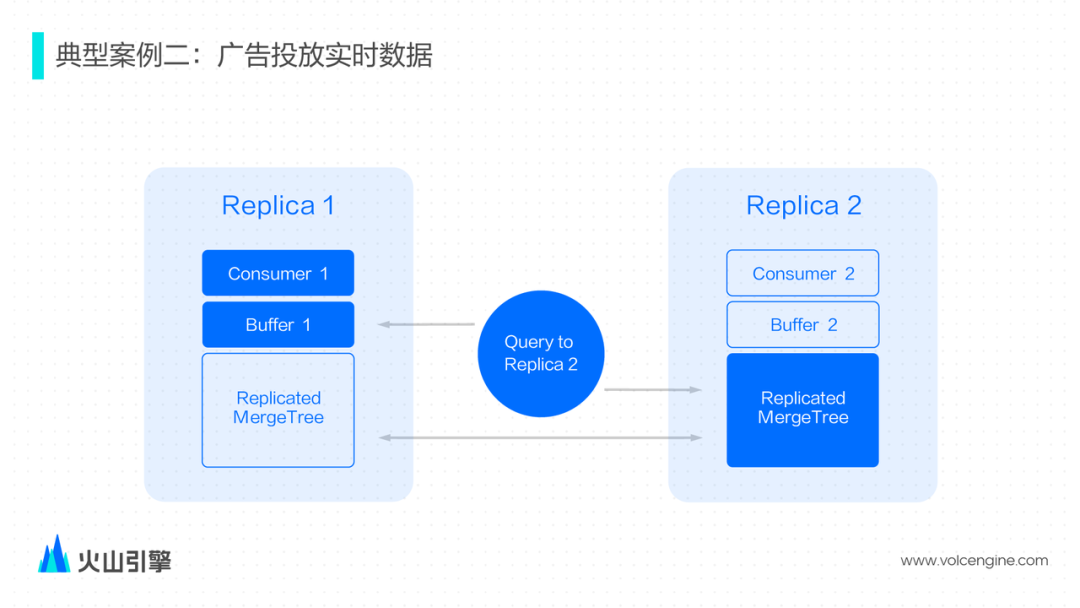
我们选择将 Kafka/Buffer/MergeTree 三张表结合起来,提供的接口更加易用; 把 Buffer 内置到 Kafka Engine 内部, 作为 Kafka Engine 的选项可以开启/关闭,使用更方便; Buffer table 内部类似 pipeline 模式处理多个 Block; 支持了 ReplicatedMergeTree 情况下的查询。

小结
评论