
炸!撩下 OLAP 数据分析的黑马神器 ClickHouse
点击蓝色“有关SQL”关注我哟
加个“星标”,天天与10000人一起快乐成长

图 | Lenis
互联网两大巨兽,西谷歌,东炎帝!
谷歌我们都知道,全世界有名的搜索引擎公司。那么炎帝,是中国那个老祖宗-炎帝么?
搞笑,当然不是!
炎帝是我硬翻的,英语 6 级,才疏学浅,不够用。原词是 Yandex, 俄罗斯的一家互联网公司。做搜索业务,与谷歌齐名。
认识这家公司,倒不是我要去俄罗斯宣传 SQL. 而是这家公司做了款牛皮到炸天的 OLAP 分析工具 ClickHouse.
ClickHouse = Click Stream + Data Warehouse
这并不是我 YY 的单词组合,炎帝(Yandex) , 就是这么宣传的。
说起 OLAP,容我卖下情怀,插播一段回忆。
2008年时,昕姐(我媳妇儿)和我还在无锡华润,做 SAP/R3 开发。
公司活少,人好,周末活动紧凑,两个人又都是不留钱的主,每月收入 5000 块,悉数花个精光,小日子过得忘乎所以。
也不知道昕姐哪天受了刺激,要求我开发一套家庭用的资产管理 MIS(management of information system).
好歹我也会点 VFP + SQL Server. 封闭式开发了一个周末,这套资产管理系统就出来了。
现在想想,太特么幼稚了。5000块,还资产管理,哈哈。
当时,却觉得蛮好玩。还在昕姐面前涨了面儿。
但,任何 MIS 投入使用,便开启一个大坑。
首先是界面美化。当时,前端没有那么火和骚,一个 FORM(表单)解决问题。调调背景色和线框样式,也就过去了。
最大的问题,来自数据分析。昕姐提出来两个报表:
每日消费统计图,并可以汇总成周/月/年的统计 消费明细统计图,按照时间粒度做分计
这两个要求,让当时的我,触摸到了 OLAP 的边。
你看,一个对象对 SQL BOY 的影响,就是这么大!
一开始,用 vfp 编程, 在表单上划线。折线图非常硬,特别直男的那种。没有一点柔和感,粗细不好调。数据一多,那锯齿画面,看得我一脸紧张。还没昕姐在 excel 上做的好。
于是想着,excel 2007 作图居然这么好看,为什么不能用在 vfp 编程中呢。谷歌了下,发现一个终极难题,vfp9 终结了开发,顶多与 excel 2003 集成。想要使用 excel2007 的 DLL库,必须用 c#.
好嘛,c# 就 c#, 反正经过这么几次折腾,我对 vfp 的前景,也看淡了很多。
于是,买了两本 c# 的书,趁着月黑风高,苦战了几个星期。把表单控件,ado.net 编程也都摸了个遍。彻底把家庭资产管理系统改写了。
终于,报表像样了,图变得润滑了,柱状切饼图,随手也做掉了。我的腰板再一次硬起来了。
原以为可以喘口气了。谁知昕姐,笑盈盈地端来了一碗热鸡汤面,同时还端来了新一轮的需求。
原来她想要的日消费统计图,是把所有的消费记录都拉出来。按照年一行行统计好,排列成柱状图。
如果哪一年消费有些高,可以点着那根柱状图,进去看每个月,进而可以找到哪一天,什么种类的消费高了。
天哪,这个脑洞怎么想出来的,肯定是那帮财务分子教她的!我就说嘛,找媳妇儿不能找财务,哪怕沾点边儿的,那个要求,细过出前一丁。
我一口一口扒着面,一嘴一嘴的讨价还价,最终还是接了这个需求。
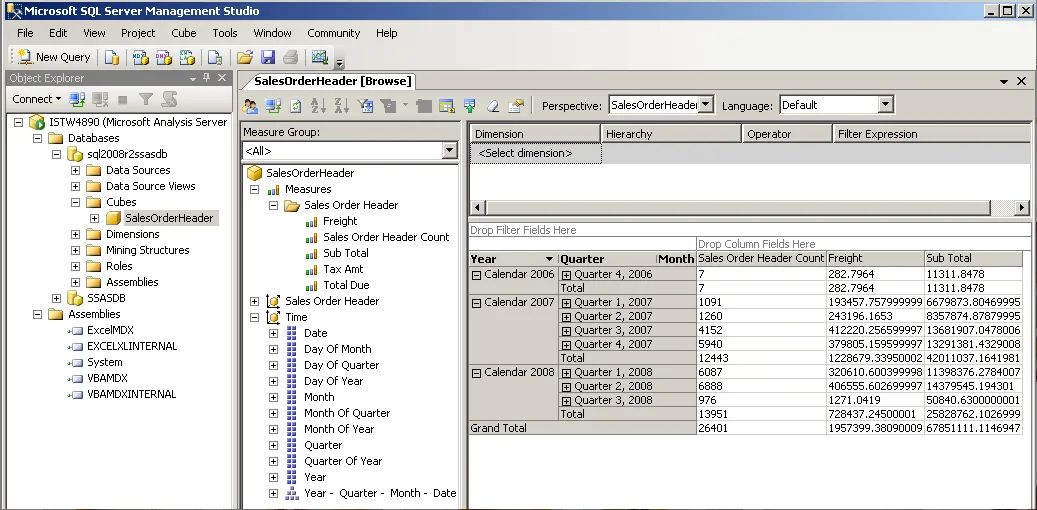
于是,又是一通搜索,让我知道了 sql server cube 和 excel pivot chart 这两样宝贝。
cube 可以实现下钻和上卷的功能,前提是按照维度和度量(组),预先生成一张大表。然后丢给 cube 服务器去跑数据。
大致的 cube 架构如下图:
excel pivot chart 则是承接 cube 来的数据,完成可视化操作。
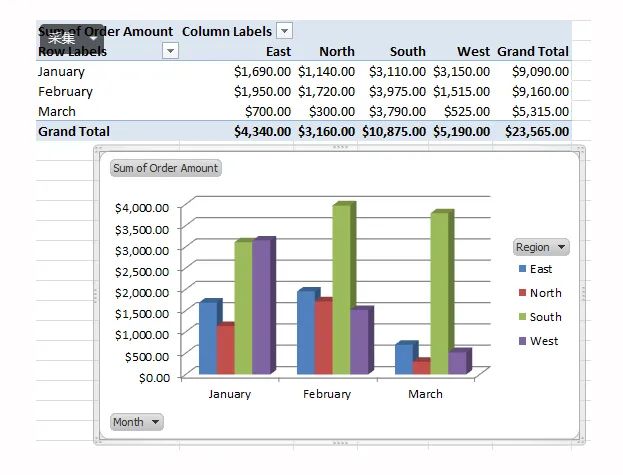
如今这样的可视化分析,到处都是,就连PowerBI,也大放异彩!
当把最终的产品给昕姐做展现的时候,虽然没有得到她的极力夸奖,但我内心却异常激动。因为后续的事情,老读者们都知道了。这项新研究,我把它用到公司的MES软件中,彻底改变了我在公司IT部门的地位,也让我拿到了薪水翻3番的新工作。
从现在的角度来看,当时做的这些基础的数据仓库和BI工作,是十分初级和粗糙的。但对于大部分的制造业和服务业来说,基本上解决90%的数据统计问题,一点瓶颈都没有。
美中不足的,有以下3个方面:
非实时 维度暴涨 极度呆滞
非实时
这个很好理解。类似 cube 这类预处理机制,本质上是用空间换时间策略。把聚合的处理,放在了数据分析的前道处理工序上。
就如同下面的建模,确定4个维度和1个度量,最后送入 Cube 服务器做处理:
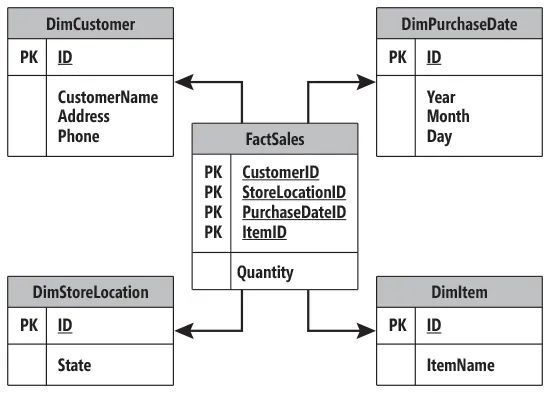
而这个预处理,非常耗时。首先需要确定维度和度量,经过数据建模和ETL,把数据聚拢。预处理后,查询速度极快。
业界称这种处理分析方式为 MOLAP, 即 Multidiemensional OLAP. 它需要一种特殊的数据库服务,就是聚合计算引擎。
除了 sql server cube,还有 Oracle, IBM, MySQL 都提供类似的产品。大数据界也有类似的产品,Hive, SparkSQL, Impala, Kylin 等。这些大数据产品的实现原理,也基本都衍生于 MapReduce.
维度暴涨
前面说到 MOLAP 的本质是预计算,针对特定维度组合,把预计算的统计值,存在数组里。等到分析时,根据维度组合索引,就能快速定位到具体的统计值。
在下面的数据立方体(Cube)中,预先计算了聚合的值。立方体的每条边,都视作一个维度。每个小碎格,代表了维度相交,聚合出来的度量值。立方体代表了3维,如果有更多维,则预处理会更加复杂。
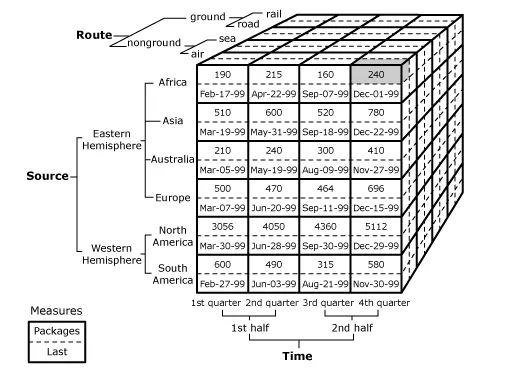
但是分析的时候,我们并不是每次都需要全部的维度。有时候仅需要其中2-3个维度,但是预处理引擎却是要把所有维度的组合,都算进来。
假设有 n 个维度,需要组合计算的种类,就有 2^n 个。比如 10个维度,那么维度组合就有1024种,这会是个巨大无比的集合。
显然,这不仅浪费资源,还容易拖累查询速度。
极度呆滞
在数据被送入 cube 处理之前,需要对表结构做特殊处理。这种处理方式,就是大家经常听到的维度建模。
在 cube 引擎中,流淌的不是一行行数据,而是一个个维度和基于这些维度组合附加的度量。这么说肯定很抽象,什么是维度,什么是度量?听上去和表结构似乎没什么关系,初学者也很难搞清楚。
再举个栗子,就拿篮球运动员奥尼尔来说,年龄,身高,带球速度,就是他的维度;而打过多少场球赛,胜多少场,平多少场,输多少场,就是他的度量。比如20岁,以216公分身高,147公斤体重,抢得篮板球2个,胜3场球赛。这样一条记录,可以为其建模为:
age height weight board_score win_time
20 216 147 2 3
这样一来,维度和度量,其实非常明确。年龄,身高,体重是维度,篮板个数,胜负数是度量。
数据被整理成这种格式后,就可以送入 cube 做处理。但,也因为是这样的预整理模式,束缚了 cube 的计算能力。
我们要增加一维,比如教练,就需要重新整理数据表,而 cube 也需要重新做一次全处理,而不是增量处理。全处理,意味着需要把整张表扫描,根据维度组合,生成预聚合。
很显然,这样的预处理,对于维度经常变动的数据,是没有优势的,缺少灵活性。如今的互联网形态,每分钟数据都有新的维度产生,因此cube的处理方式,变得力不从心。
此时, 黑马 Clickhouse 出场了。它带着新型的处理方式,来了。他来了,她终于来了。
它摒弃预处理方式,以实时维度组合,闪电般地计算聚合。增加维度,一维,两维,三维,都不需要做任何延迟计算,在数据表生成的那一刹那,查询既结果。它是真正的 ROLAP. 意味着,不需要多一层像 cube 一样的多维数据库引擎,来加快查询速度。
它解决了传统 cube 的所有缺点。
以上的分享,灵感来自于这本书《ClickHouse原理解析与应用实践》。感谢机械工业出版社华章赵静编辑的赠书。这是国内第一本详细介绍clickhouse的书,作者也是 clickhouse 代码的贡献者,非常值得一看。
迫不及待,我已经在春节期间,开始本次CH之旅。
全书总共分为11章:
第1章 介绍ClickHouse的由来、发展历程、核心特点与核心特点。
第2~6章 介绍了ClickHouse基础使用部分,包括整体架构、如何安装、数据定义、数据引擎、数据查询和函数的特性和使用方法。
第7~9章介绍了ClickHouse高级特性部分,包括数据库管理操作,数据分片、数据副本和高可用的特性和使用方法。
第10~11章介绍了如果自己手动实现ClickHouse中间件的思路和示例,同时也介绍了几款可视化工具与ClickHouse集成的方法。
往期精彩: