
TiDB 实践 | TiDB 在爱奇艺实时分析场景的应用实践
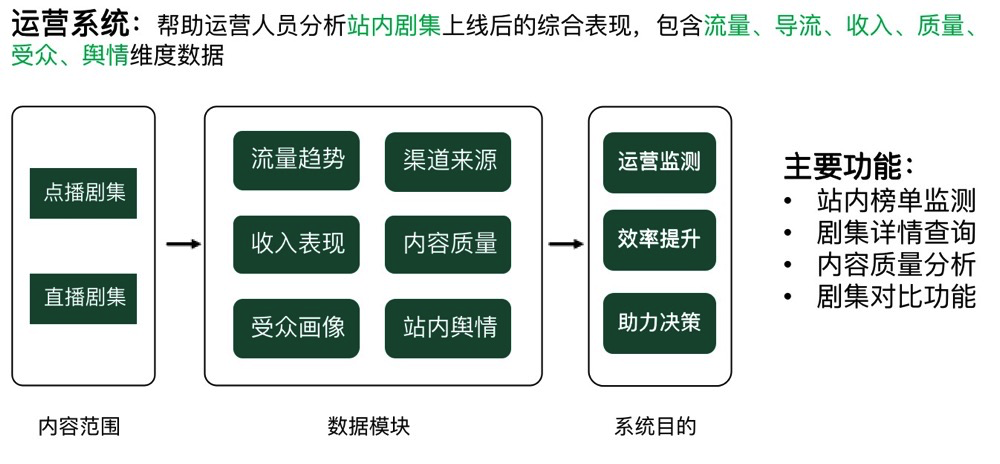
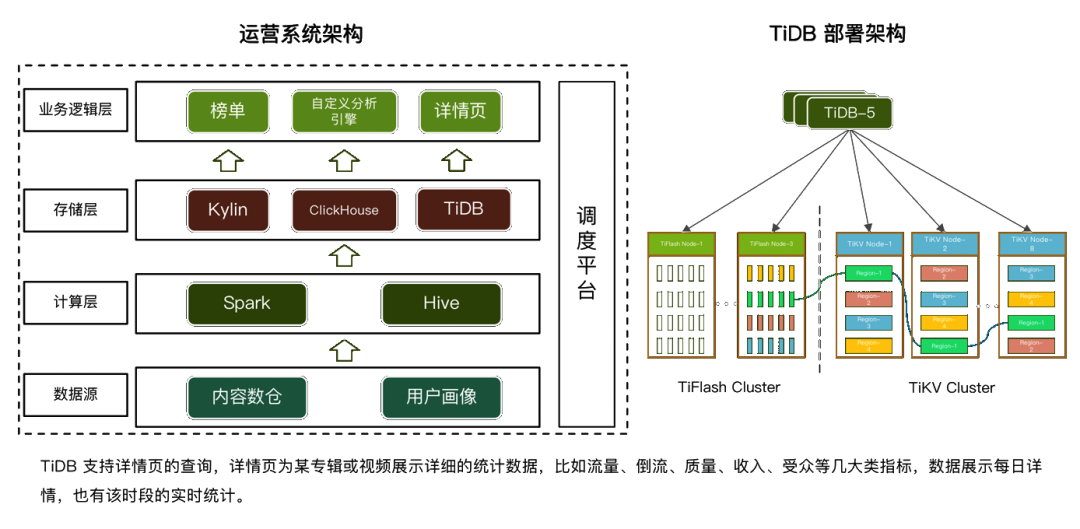
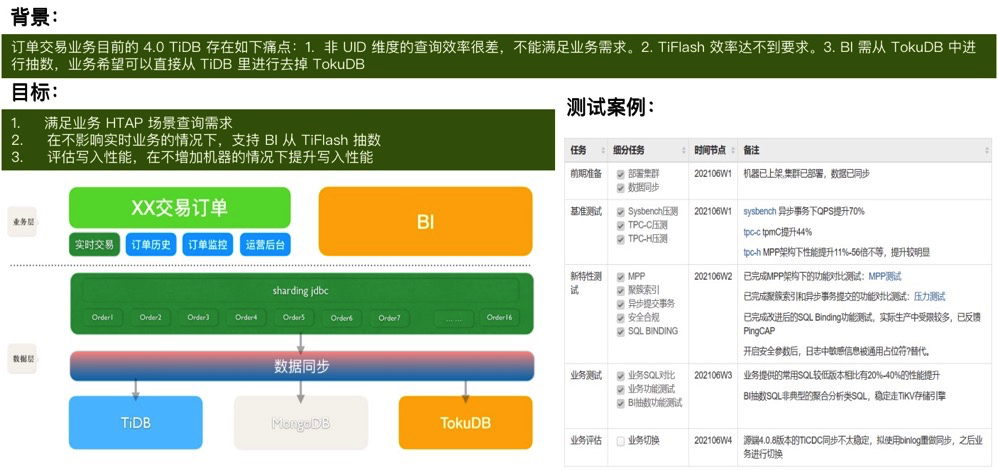
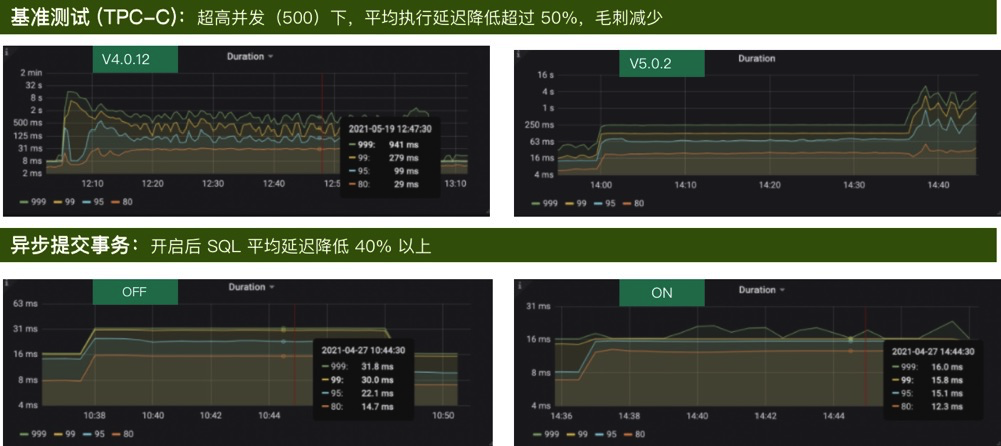
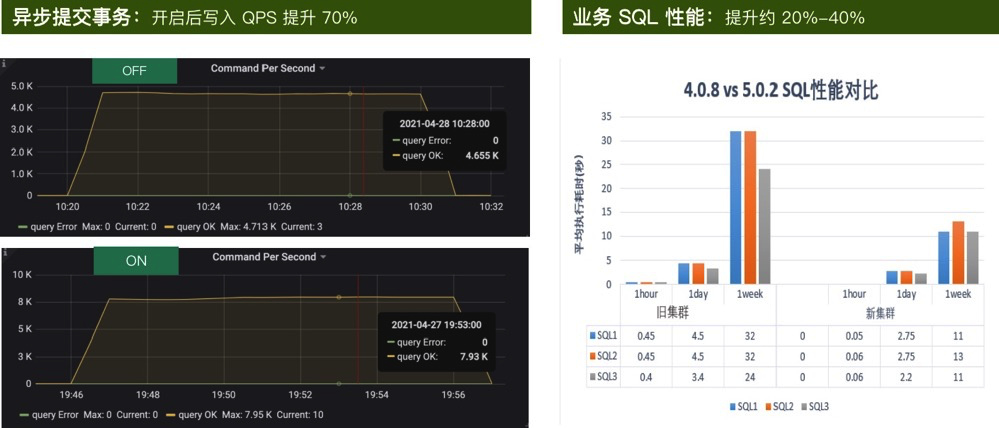
随着业务的规模化发展,数据实时处理的能力成为了限制企业数据变现的重要关口之一。本文结合爱奇艺在实时分析场景的实践经验,分享了传统实时分析架构的不足,以及 TiDB 在安全风控和 BI 运营分析系统中部署的经验,最后介绍了 TiDB 5.0 版本在订单交易系统中的测试结果和对未来的展望。

💡 本文根据路希在【PingCAP DevCon 2021】上的演讲整理而成。扫描下方二维码查看全部视频回放和 PPT。点击阅读原文查看本篇演讲实况。
评论