
Transformer拿下CV顶会大奖,微软亚研获ICCV 2021最佳论文
点击“凹凸域”,马上关注
更多内容、请置顶或星标
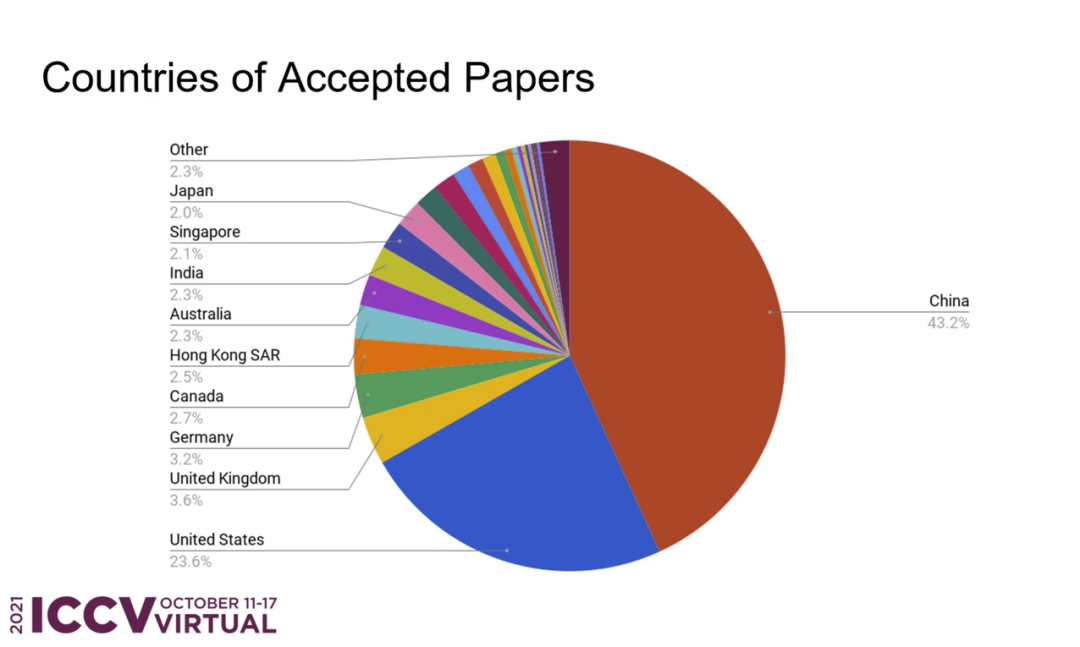
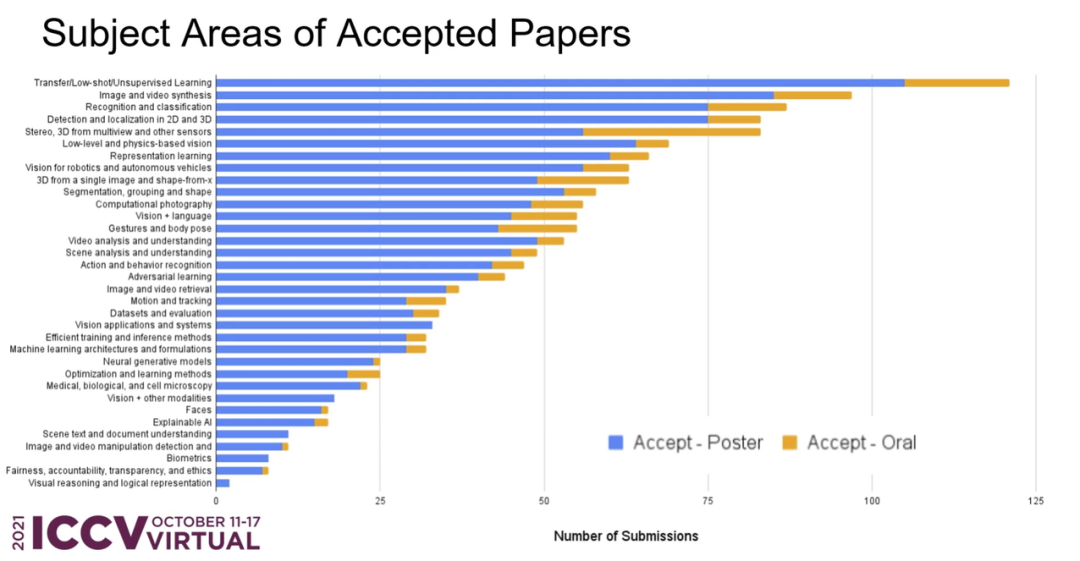
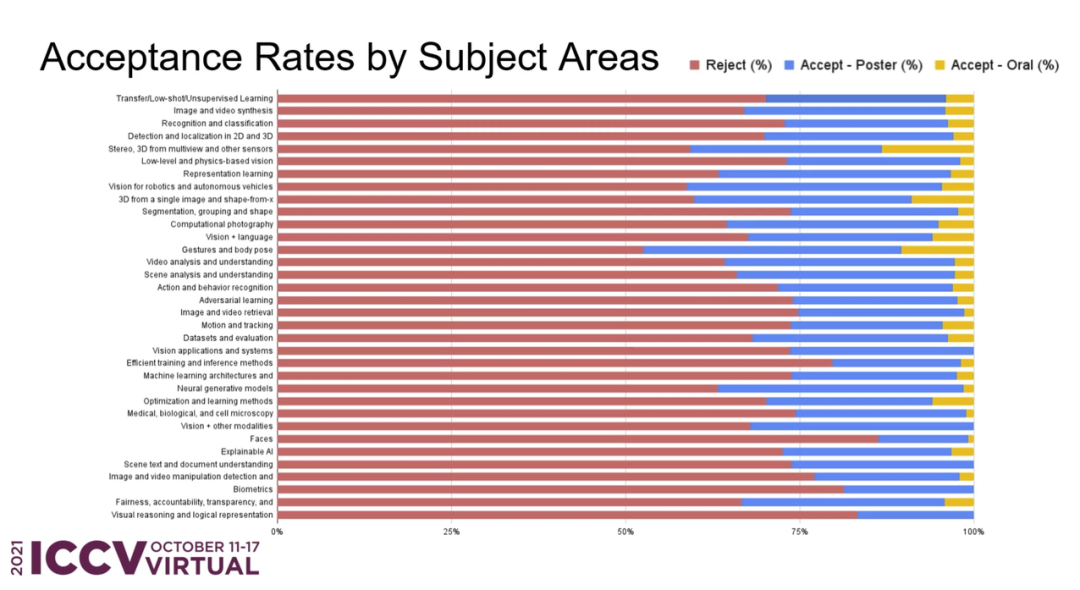
ICCV 2021 全部奖项已经公布,来自微软亚洲研究院的研究者获得 ICCV 2021 马尔奖(最佳论文);最佳学生论文奖由苏黎世联邦理工学院、微软研究者获得。


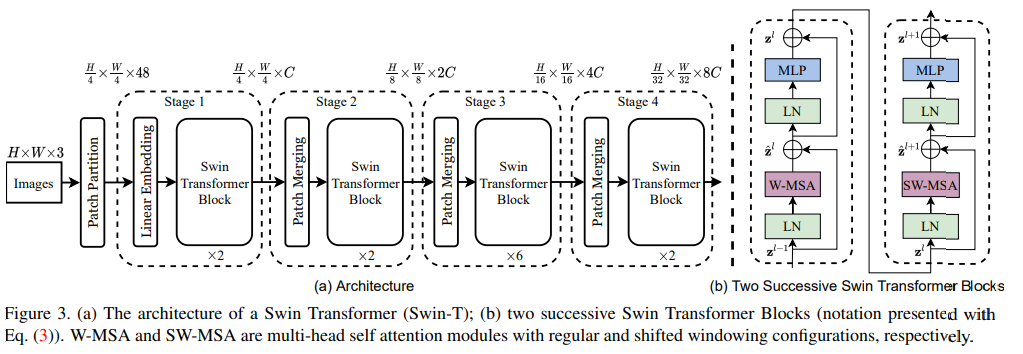
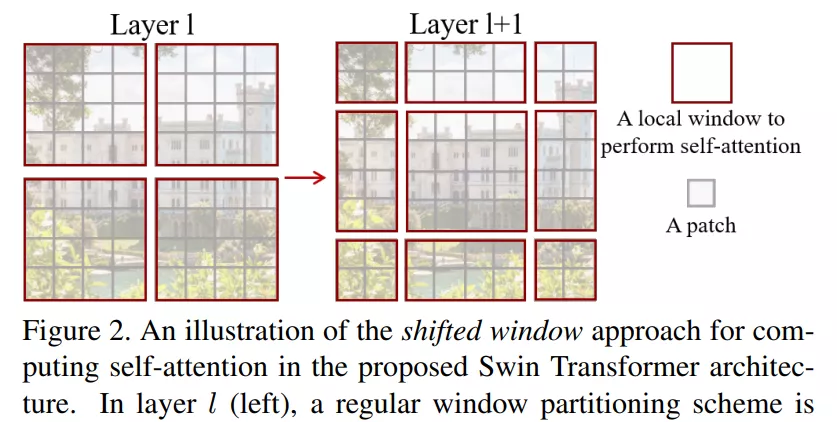
获奖论文:Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
作者机构:微软亚洲研究院
论文地址:https://arxiv.org/pdf/2103.14030.pdf
项目地址:https://github.com/microsoft/Swin-Transformer


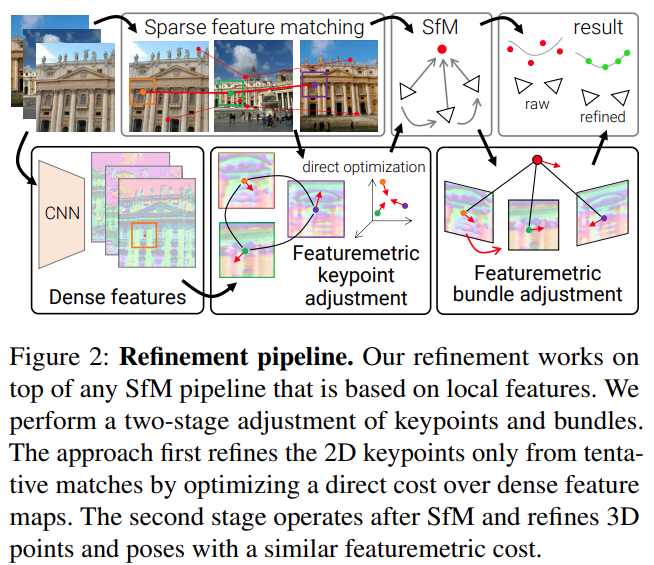
获奖论文:Pixel-Perfect Structure-from-Motion with Featuremetric Refinement
作者机构:苏黎世联邦理工学院、微软
论文地址:https://arxiv.org/pdf/2108.08291.pdf
项目地址:github.com/cvg/pixel-perfect-sfm (http://github.com/cvg/pixel-perfect-sfm)

论文 1:Mip-NeRF: A Multiscale Representation for Anti-Aliasing Neural Radiance Fields
作者机构:谷歌、加州大学伯克利分校
论文地址:https://arxiv.org/pdf/2103.13415.pdf

论文 2:OpenGAN: Open-Set Recognition via Open Data Generation
作者机构:卡内基梅隆大学
论文地址:https://arxiv.org/pdf/2104.02939.pdf

论文 3:Viewing Graph Solvability via Cycle Consistency
作者机构:特伦托大学等
论文地址:https://openaccess.thecvf.com/content/ICCV2021/papers/Arrigoni_Viewing_Graph_Solvability_via_Cycle_Consistency_ICCV_2021_paper.pdf

论文 4:Common Objects in 3D: Large-Scale Learning and Evaluation of Real-life 3D Category Reconstruction
作者机构:Facebook AI 研究院、伦敦大学学院
论文地址:https://arxiv.org/pdf/2109.00512.pdf


论文 1:《ORB: An efficient alternative to SIFT or SURF》
论文链接:https://ieeexplore.ieee.org/document/6126544
论文 2:《HMDB: A large video database for human motion recognition》
论文链接:https://ieeexplore.ieee.org/document/6126543
论文 3:《DTAM: Dense tracking and mapping in real-time》
论文链接:https://ieeexplore.ieee.org/document/6126513




— END —
想要了解更多AI资讯
点这里👇关注我,记得标星呀~
请点击上方卡片,专注计算机人工智能方向的研究