
对Elasticsearch生命周期的思考
点击上方蓝色字体,选择“标星公众号”
优质文章,第一时间送达
作者 | 一寸HUI
来源 | urlify.cn/zYNFzq
什么是es索引的生命周期?有啥用?可以怎么用?用了有什么好处呢?
在现实的生产环境中有没有觉得自己刚开始设计的索引的分片数刚刚好,但是随着时间的增长,数据量增大,增长速度增大的情况下,你的es索引的设计是否还合理呢?
在现实的生产存储中,有没有一些数据时间长了就没价值了,没必要浪费存储了,就可以删除了,有些数据变得不再重要了,可以存放在低性能的磁盘上,节约公司的机器硬件成本呢?
es生产环境,有没有经历过通过人工去管理索引的中部分数据的删除呢,知道es删除数据原理的都知道,这样对性能有很大的影响,刚开始并没有真正的删除数据。
这篇文章纯属于个人通过别人的博客和官网的学习,结合自己公司业务场景的一个思考,有些是没有实际验证的。本篇也是基于elasticsearch7.8.1的一个版本的知识点。
一、引发思考的背景
1、首先业务场景,es的业务场景是真的广泛,目前我们只是用来做搜索查询,虽然现在在研究elk,对日志的进行索引,但是肯能还只是用到es的一点点的功能
2、在es安装的时候,如何设计节点,如何根据现有的机器做es的集群,配置好集群后,怎么设计索引,一般都会有一个时间的字段,根据数据量的大小和增长速度可以根据天,月,年等时间间隔切分索引,使用别名管理,那么多索引,但是又如何去管理这些索引呢,还要根据自己公司的业务场景,而不是纯粹的设计理论,我觉的符合公司情况,符合业务场景的设计才是最好的设计吧,但是不是一味的强耦合的只考虑单个业务,应该考虑多个,能够做到模板化,这样就能很好的做扩展了,以及要考虑对未来的规划和数据增长的容忍度吧
3、当然我们目前没有巨量的数据,但是很多事情也必须考虑进去,根据公司业务,比如数据只有一年的经常使用,后面的数据基本不用,三年前的数据可以删除,机器设备性能,有些机器磁盘性能好ssd,有些一般吧机械硬盘,还有cpu,内存的因素都要考虑。
4、公司管理人员少,怎么去管理这些呢,也没这个精力去开发索引的管理界面,很多因素都要考虑进去
二、冷热架构
冷热架构就是有冷的有热的(这是玩笑话),就是经常需要使用(热)和不经常使用的数据(冷),有了这样的却别,存储方面肯定也要区别对待吧,把热数据存放在性能好的机器上,把冷的数据存放在性能较差的机器上,这个就是所谓的合理利用资源,节约公司硬件成本,也就是在硬件成本一定的条件下,提升集群的性能。但是描述是这么描述了,怎么实现热数据就存在好的机器上,冷数据就存在差点的机器上呢,可以映射呀,打标签呀,方法很多嘛,es就是打标签。----如上描述都是个人理解(这里只说个人的)
好,接下来就给每个es集群的节点打标签咯,说A集群性能好,用来存热数据,说B机器性能差一些,用来存冷数据,在他们每个机器上挂个牌牌,方便数据根据自己的冷热程度对号入座。es是这么打标签的:
在elasticsearch.yml文件中增加
node.attr.{attribute}: {value}
比如可以给机器配置冷热的标签:
node.attr.temperature: hot //热节点
node.attr.temperature: warm //冷节点现在是机器的标签打好了,那索引数据怎么打标签,并且一一对应呢?就是对索引有如下的设置(_settings)就可以对应好啦:
index.routing.allocation.include.{attribute} //表示索引可以分配在包含多个值中其中一个的节点上。
index.routing.allocation.require.{attribute} //表示索引要分配在包含索引指定值的节点上(通常一般设置一个值)。
index.routing.allocation.exclude.{attribute} //表示索引只能分配在不包含所有指定值的节点上。详细的部署这里不说了,大概只聊聊思想,部署可以参考下其他博主的博客:
https://www.elastic.co/guide/en/elasticsearch/reference/7.8/shard-allocation-filtering.html
https://zhuanlan.zhihu.com/p/97098781
https://www.cnblogs.com/caoweixiong/p/11988457.html
三、生命周期
聊了背景,说了冷热架构,那我们怎么怎么自动的管理呢?这样生命周期就派上用处了,比如一个索引的数据经过10天就从热数据转为了冷数据,这样可以通过一系列的action和设置进行操作,自动根据时间把冷数据转移到性能较差的机器上。这样岂不是很方便,接下来我们就了解下索引的生命周期,以及怎么使用。
二话不说,上官网:https://www.elastic.co/guide/en/elasticsearch/reference/7.8/index-lifecycle-management.html
可以配置索引生命周期管理(ILM)策略,以根据您的性能、弹性和保留需求自动管理索引。比如当索引达到一定大小或文档数量时,旋转新索引,每天、每周或每月创建一个新索引,并归档以前的索引,删除过时的索引以执行数据保留标准。可以通过API配置和kibana配置进行生命周期的管理。
ES索引生命周期管理分为4个阶段:hot、warm、cold、delete,其中hot主要负责对索引进行rollover操作,warm、cold、delete分别对rollover后的数据进一步处理(前提是配置了hot)
阶段 | 描述 |
hot | 主要处理时序数据的实时写入 |
warm | 索引不再被更新,但仍在被查询 |
cold | 索引不再被更新,并且很少被查询。这些信息仍然需要可搜索 |
delete | 索引不再需要,可以安全地删除 |
那这些索引是根据什么条件去从一个阶段转到另一个阶段的呢?比如可以根据时间呀,文档数据呀,索引大小呀作为判断条件转到下一个阶段。
1、当索引达到50GB时,将鼠标移至新索引。
2、将旧索引移至热阶段,将其标记为只读,然后将其缩小为单个碎片。
3、7天后,将索引移至冷阶段,然后将其移至较便宜的硬件上。
4、达到所需的30天保留期后,删除索引那我们在索引的每一个阶段可以做什么样的操作呢,比如增加索引的设置,修改副本数量等。
阶段 | 操作(action) |
Hot | Set Priority,Unfollow,Rollover |
Warm | Set Priority,Unfollow,Read-Only,Allocate,Shrink,Force Merge |
Cold | Set Priority,Unfollow,Allocate,Freeze |
Delete | Wait For Snapshot,Delete |
具体如上的每一个动作(action)是什么,大家参考官网https://www.elastic.co/guide/en/elasticsearch/reference/7.8/ilm-actions.html
我们知道索引生命的周期的阶段,也知道根据什么条件从一个周期跳转到另一个阶段,也知道在每一个阶段可以做什么操作了,那么就成了呀,更具自己的业务场景设计索引的生命周期吧!!!接下来就看看什么实用呢?
来,官网:https://www.elastic.co/guide/en/elasticsearch/reference/7.8/set-up-lifecycle-policy.html
https://www.elastic.co/guide/en/elasticsearch/reference/7.8/getting-started-index-lifecycle-management.html
通过索引生命周期策略管理索引的基本步骤如下:
1. 创建定义适当阶段和操作的生命周期策略
2. 创建索引模板,将策略应用于每个新索引
3. 引导一个索引作为初始写索引
4. 验证索引按预期在生命周期阶段中移动
如上四个步骤根据官网来一步一步操作很简单,如果要结合冷热架构的话,可以在某一个阶段根据自己的需求通过索引的设置(_settings)指定打好标签机器的标签就好了
当然索引的生命周期还可以通过kibana进行配置:
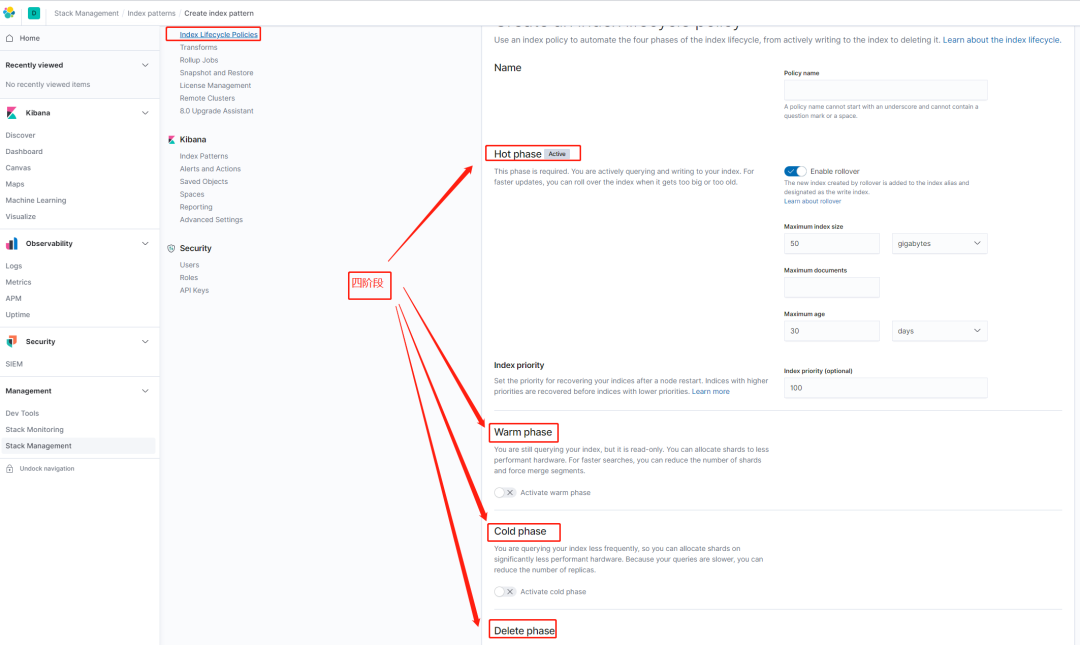
根据图一步一步的操作很简单的!
生命周期管理策略真的是一个很好管理索引的技术,很灵活,能够减少人工的介入。都可以根据公司的业务场景好好使用,本文的冷热架构这里没有实践过,但是索引的生命周期还是实践过,挺好用的,特别是一些日志数据,保留7天或者一个月就够了,可以通过生命周期策略配置自动删除满足条件的数据,这样集群的数据也不会无限的增长,也不需要人工管理。


感谢点赞支持下哈 