
超级芯片GH200发布,AI算力是H100两倍


英伟达在计算机图形学顶会 SIGGRAPH 2023 上发布了专为生成式 AI 打造的下一代 GH200 Grace Hopper 平台,并推出了 OVX 服务器、AI Workbench 等一系列重磅更新。
五年前,也是在 SIGGRAPH 大会的演讲中,英伟达宣布将 AI 和实时光线追踪引入 GPU ,可以说,当时的这个决定重塑了计算图形学。
「我们意识到光栅化已经达到了极限,」黄仁勋表示:「这要求我们重塑硬件、软件和算法。在我们用 AI 重塑 CG 的同时,也在为 AI 重塑 GPU。」
预言应验了:几年来,计算系统变得越来越强大,例如 NVIDIA HGX H100,它利用 8 个 GPU 和总共 1 万亿个晶体管,与基于 CPU 的系统相比,提供了显著的加速。
「这就是世界数据中心迅速转向加速计算的原因,」在今年的 SIGGRAPH 大会,黄仁勋重申:「The more you buy, the more you save.」

如今,训练越来越大的生成式 AI 模型所需的计算未必由具有一定 GPU 能力的传统数据中心来完成,而是要依靠像 H100 这样从一开始就为大规模运算而设计的系统。可以说,AI 的发展在某种程度上只受限于这些计算资源的可用性。
但黄仁勋断言,这仅仅是个开始。新模型不仅需要训练时的计算能力,还需要实现由数百万甚至数十亿用户实时运行的计算能力。
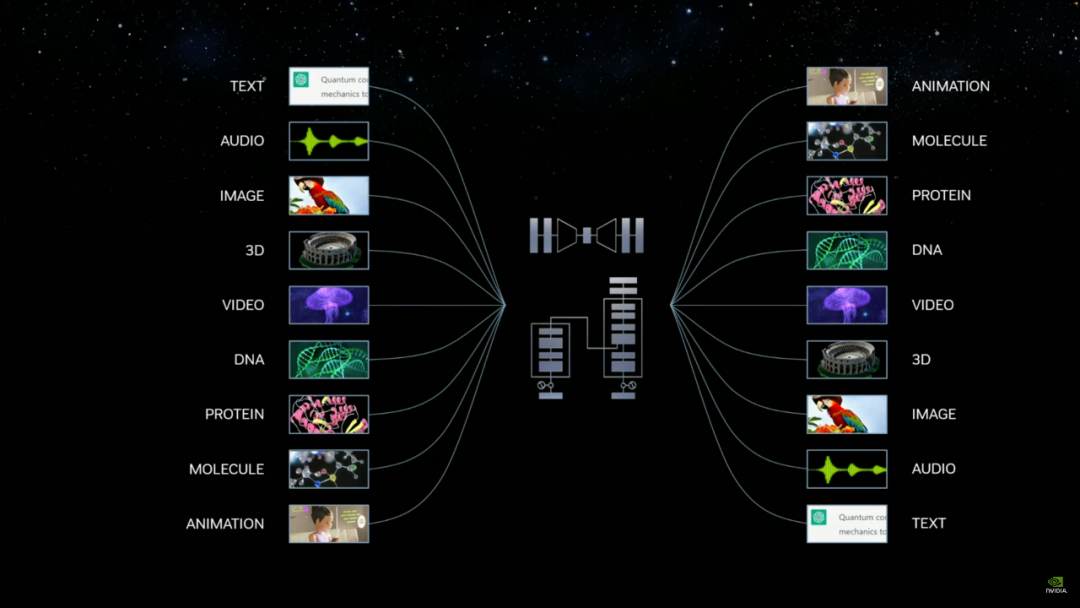
「未来,LLM 将出现在几乎所有事物的前端:人类就是新的编程语言。从视觉效果到快速数字化的制造市场、工厂设计和重工业,一切都将采用自然语言界面。」黄仁勋表示。
在这场一个多小时的演讲中,黄仁勋带来了一系列新发布,全部面向「生成式 AI」。
更强的 GH200 Grace Hopper 超级芯片平台
英伟达的 Grace Hopper 超级芯片 NVIDIA GH200 结合了 72 核 Grace CPU 和 Hopper GPU,并已在 5 月全面投入生产。
现在,黄任勋又宣布 Grace Hopper 超级芯片将配备 HBM3e 高带宽内存(HBM3e 比当前的 HBM3 快 50%),下一代 GH200 Grace Hopper 平台将大幅提升生成式 AI 的计算速度。

全新的 GH200 内存容量将增加至原有的 3.5 倍,带宽增加至 3 倍,包含一台具有 144 个 Arm Neoverse 核心、282GB HBM3e 内存的服务器,提供 8 petaflops 的 AI 算力。
为了提升大模型的实际应用效率,生成式 AI 模型的工作负载通常涵盖大型语言模型、推荐系统和向量数据库。GH200 平台旨在全面处理这些工作负载,并提供多种配置。
英伟达表示,这款名为 GH200 的超级芯片将于 2024 年第二季度投产。
Nvidia AI Workbench,模型即服务
此外,为了加快全球企业定制化采用生成式 AI,老黄宣布英伟达即将推出 Nvidia AI Workbench。
尽管很多预训练模型都是开源的,但使其定制化服务自身业务仍然具有挑战性。AI Workbench 减轻了企业 AI 项目入门的复杂程度,将所有必要的企业级模型、框架、软件开发套件和库整合到统一的 workspace 之中。
只需要在本地系统上运行的简化界面进行点击,AI Workbench 就能让开发者使用自定义数据微调 Hugging Face、GitHub 和 NGC 等流行存储库中的模型,然后将其扩展到数据中心、公有云或 Nvidia DGX 云。
黄仁勋还宣布英伟达将与 Hugging Face 合作,开发人员将能够访问 Hugging Face 平台中的 NVIDIA DGX Cloud AI 超级计算来训练和调整 AI 模型。这将使数百万构建大型语言模型和其他高级 AI 应用程序的开发人员能够轻松实现生成式 AI 超级计算。
「这将是一项全新的服务,将世界上最大的人工智能社区与世界上最好的训练和基础设施连接起来,」黄仁勋表示。
全新的 RTX 工作站和 Omniverse
老黄还宣布,英伟达与 BOXX、戴尔科技、惠普和联想等工作站制造商合作,打造了一系列全新的高性能 RTX 工作站。
最新发布的 RTX 工作站提供多达四个英伟达 RTX 6000 Ada GPU,每个 GPU 配备 48GB 内存。单个桌面工作站可提供高达 5828 TFLOPS 的性能和 192GB 的 GPU 内存。

根据用户需求,这些系统可配置 Nvidia AI Enterprise 或 Omniverse Enterprise 软件,为各种要求苛刻的生成式 AI 和图形密集型工作负载提供必要的动力。这些新发布预计将于秋季推出。
新发布的 Nvidia AI Enterprise 4.0 引入了 Nvidia NeMo,这是一个用于构建和定制生成式 AI 基础模型的端到端框架。它还包括用于数据科学的 Nvidia Rapids 库,并为常见企业 AI 用例(例如推荐器、虚拟助理和网络安全解决方案)提供框架、预训练模型和工具。
工业数字化平台 Omniverse Enterprise 是 Nvidia 生态系统的另一个组成部分,让团队能够开发可互操作的 3D 工作流程和 OpenUSD 应用程序。Omniverse 利用其 OpenUSD 原生平台,使全球分布的团队能够协作处理来自数百个 3D 应用程序的完整设计保真度数据集。
此次英伟达主要升级了 Omniverse Kit(用于开发原生 OpenUSD 应用和扩展程序的引擎),以及 NVIDIA Omniverse Audio2Face 基础应用和空间计算功能。开发者可以轻松地利用英伟达提供的 600 多个核心 Omniverse 扩展程序来构建自定义应用。
作为发布的一部分,英伟达还推出了三款全新的桌面工作站 Ada Generation GPU:Nvidia RTX 5000、RTX 4500 和 RTX 4000。
全新 NVIDIA RTX 5000、RTX 4500 和 RTX 4000 桌面 GPU 采用最新的 NVIDIA Ada Lovelace 架构技术。其中包括增强的 NVIDIA CUDA 核心(用于增强单精度浮点吞吐量)、第三代 RT 核心(用于改进光线追踪功能)以及第四代 Tensor 核心(用于更快的 AI 训练性能)。

Nvidia RTX 5000 Ada 一代 GPU。
这几款 GPU 还支持 DLSS 3,为实时图形提供更高水平的真实感和交互性,以及更大的 GPU 内存选项,用于大型 3D 模型、渲染图像、模拟和 AI 数据集的无差错计算。此外,它们还提供扩展现实功能,以满足创建高性能 AR、VR 和混合现实内容的需求。
因为配备了第三代 RT Core,这几款 GPU 的吞吐量高达上一代的 2 倍,使用户能够实时处理更大、保真度更高的图像,将应用于艺术创作和设计生产。
RTX 5000 GPU 已经上市,并由 HP 和分销合作伙伴发货,而 RTX 4500 和 RTX 4000 GPU 将于秋季从 BOXX、Dell Technologies、HP、Lenovo 及其各自的分销合作伙伴上市。
Nvidia OVX 服务器
英伟达还推出了配备 Nvidia L40S GPU 的 Nvidia OVX 服务器,用于生成式 AI 和数字化时代的开发和内容创作。
每台 Nvidia OVX 服务器将支持多达 8 个 Nvidia L40S GPU,每个 GPU 配备 48GB 内存。L40S GPU 由 Nvidia Ada Lovelace GPU 架构提供支持,拥有第四代张量核心和 FP8 Transformer 引擎,可实现超过 1.45 petaflops 的张量处理能力。

Nvidia L40S GPU。
在具有数十亿参数和多种数据模式的生成式 AI 工作负载领域,与 Nvidia A100 Tensor Core GPU 相比,L40S GPU 的生成式 AI 推理性能提高了 1.2 倍,训练性能提高了 1.7 倍。这将更好地满足 AI 训练和推理、3D 设计和可视化、视频处理和工业数字化等计算密集型应用的需求,加速多个行业的工作流程和服务。
参考链接:
https://blogs.nvidia.com/blog/2023/08/08/siggraph-2023-special-address/
https://venturebeat.com/ai/nvidia-launches-rtx-workstations-chips-for-content-creation-in-the-generative-ai-era/
https://techcrunch.com/2023/08/08/nvidia-ceo-we-bet-the-farm-on-ai-and-no-one-knew-it/
来源:机器之心
下载链接:
中国AIGC产业全景报告
AIGC算力全景与趋势报告
半导体行业数字化转型解决方案手册
2023中国AI商业落地价值研究报告
2023中国AIGC商业潜力研究报告
人机共生:大模型时代的AI十大趋势观察
AIGC行业趋势:大模型趋于分化,关注应用场景落地
330+份重磅ChatGPT专业报告(全网最全)
《人工智能AI大模型技术合集》
《70份GPU技术及白皮书汇总》
《FPGA五问五答系列合集》
《机器人行业报告合集(2023)》
GPU研究框架(2023)
NVIDIA GPU架构白皮书
《NVIDIA A100 Tensor Core GPU技术白皮书》
《NVIDIA Kepler GK110-GK210架构白皮书》
《NVIDIA Kepler GK110-GK210架构白皮书》
《NVIDIA Kepler GK110架构白皮书》
《NVIDIA Tesla P100技术白皮书》
《NVIDIA Tesla V100 GPU架构白皮书》
《英伟达Turing GPU 架构白皮书》
多领域(GPU CPU)散热材料工艺发展历史及路径演绎
AI围绕算力产业、国产化替代、复苏主线布局
CPU和GPU:异构计算的演进及发展
新型GPU云桌面发展白皮书(2023)
GPU原理及在云桌面中的应用
兆芯CPU+GPU技术路线解读
AI算力行业深度:AI模型乘风起,GPU掌舵算力大时代
GPU技术专题汇总链接
深度报告:GPU研究框架
CPU和GPU研究框架合集
本号资料全部上传至知识星球,更多内容请登录智能计算芯知识(知识星球)星球下载全部资料。
免责申明:本号聚焦相关技术分享,内容观点不代表本号立场,可追溯内容均注明来源,发布文章若存在版权等问题,请留言联系删除,谢谢。
温馨提示:
请搜索“AI_Architect”或“扫码”关注公众号实时掌握深度技术分享,点击“阅读原文”获取更多原创技术干货。
