
从18年公司基础架构开始转向 Kubernetes
几年前,人们认为,对于 Zendesk 而言,Kubernetes 是个不可能的挑战。那时,人们普遍认为:
在 Kubernetes 中,我们可以做一些小事情,但是对于我们最初的单体 Ruby on Rails 产品来说,这样做并没有什么意义。即便我们这么做,我们也不知道 Kubernetes 是否能够应付得来。
但是一切都是可以改变的,改变的种子始于 2017 年的 Zendesk Dev Leads 峰会,Jon Moter 在那里举办了一场“Zendesk 的 Kubernetes”的研讨会。我萌生了进一步探索的想法。
一开始,我在本地开发环境中使用 Kubernetes。我们已经将它引入到了基于 Docker 的环境中,我只想在 Kubernetes 中运行时启动应用程序。然而,应用程序经常崩溃,使我陷入困境:
Kubernetes 上的各种错误是什么意思?
怎样查看日志?
怎样知道失败的原因?
最初的几个月,变成了要学会如何使用 Kubernetes,而非在上面运行应用程序。我完全没想到会这样,但是这很有意思。
在本地开发环境中启动应用程序,而不立即抛出错误,是我的首要目标。一旦完成,我开始测试其他的 API。异常会被抛出,而我无法找出原因,这时我就可以开始解决配置问题了。我认识到需要解决配置问题,这样才能在部署环境中加入 Kubernetes。
有必要介绍一下配置的背景:Zendesk 遵循的路径对于 Ruby on Rails 应用程序非常典型:首先要有几个 YAML 文件……最后才是 YAML 文件和环境变量……然后再根据这些文件定制特定于公司的内容。这一切我们都有。使用 Chef 在 EC2 实例和数据中心中“烘焙”出 YAML 文件和环境变量。其结果是:配置管理混乱。
首先要尝试做的是将所有配置注入到环境变量中。这是我们开始时所做的,并且非常适合许多事情。接着我们进入结构化数据,事情就开始变得有趣了。现在回想起来,第一个挑战是网络配置。环境变量的值在 UNIX 系统中可以是有限的。在多数系统中,一个变量实际上并没有限制,但是整个环境却有限制。这有几十兆甚至更多,但是我们这里也讨论兆字节的结构化数据。此外,我们的部署工具,即注入环境变量的工具,在一个文本列中存储数值,长度不超过 2048 个字符。事实上,我们不能将所有结构化数据放在某些环境变量中。所以我们必须把它们分开。这就是说将一个数据块放在一个键中。我们设置的是 20 个键都具有相同的前缀,后缀表示数据所包含结构的哪一部分。
原始 YAML 的定义如下:

联网 YAML 文件示例
尝试用环境变量来代替:

网络环境变量示例
刚开始的时候,这样做非常好,因为它涵盖了 80% 的场景。然而,仅有 40 个环境变量的配置并非正确的答案,而且无法将我们引入预生产环境,因此我们开始使用 Kubernetes ConfigMap。
“网络配置”是我们处理的第一个大地图。在 Kubernetes 集群的 ConfigMap 中,我们编写了一个小型服务,将 Chef 维护的 YAML 文件放入其中。在最初的成功之后,我们开始加载更多的 ConfigMap。
我们得到了一些相当有趣的边缘案例,在这些案例中,我们有涉及到文件的秘密值。在此之前,我们并不反对将秘密以限制访问模式保存在磁盘上。但是在 ConfigMap 中,我们不想保持这种习惯。根据菜谱的评估位置,我们创建了一个菜谱,它会产生“数据形状”,并在所有地方共享。当运行我们的单体 EC2 实例时对其进行评估,它会以某种方式填充秘密值。若是其他应用程序,则使用不同的方法对其进行填充。基本上配置的形状是一样的,但是每个应用程序的秘密都不一样。
要让 Kubernetes 最终进入我们的 staging 环境,我们就必须把范围缩小到最小,以便获得自信。我们主要关注 unicorn 服务的流量。我们这么做的理由有很多。第一个原因是纯粹的可观察性。到目前为止,这是我们仪器化程度最高的过程,并且我们的观测越来越好。可以看到响应时间指标、错误率指标和各端点指标等等。它使得衡量成功更加容易。“这东西和以前一样管用吗?还是我破坏了什么?”
第二个原因,之所以选择 HTTP 请求,是因为它们的工作单元很小:你得到一个请求,你做了些什么,然后你发送一个响应。这样最容易让它们回滚。在推出东西的时候,我们可以观察这些指标,然后再用最小的影响将其翻转回来。这是我们必须考虑的因素。
到目前为止,我们对可观察性有信心。通过 ConfigMap,Kubernetes 突然在我们最初的 Ruby on Rails 单体产品(Classic)的 staging 环境中运行。开始后,我们可以可靠地部署它,并向它发送流量。我记得那是一个平常的日子,我们说:“噢,这确实管用。大家好,Classic 现在可以在 Kubernetes 上运行了。”
接着是什么呢?我们在 staging 中运行了一段时间,发现了许多 bug,并对它们进行了修复,一些类型的 bug 也开始出现。举例来说,开发者 A 改变了配置,他们有与此相适应的代码片段。这样很好。开发者 B 随后将代码部署到我们的 staging 环境中,并从开发者 A 那里得到配置的更改,而不知道相关的代码更改……我们以某种形式的大脑分裂告终:我们的配置输入和我们更新代码的方式不同步。这一局面变得非常混乱,非常迅速。我们开始看到事情发生一些变化,不是由于 Kubernetes 的变化,而是由于配置的变化。
这里发生了一件特殊的事情,是一个转折点。更改被合并进 README 文件。它会自动部署到我们的 staging 环境中,然后……突然之间,staging 环境不起作用了。大家感到困惑:“我们修改了一个 Markdown 文件,这是我们所能做的最无伤大雅的一件事。这怎么会破坏 staging 呢?”我们立刻回滚了以前的标签,但……这并不能解决问题。这个经验告诉我们,在复杂的环境下,或者任何环境下的配置版本都是至关重要的。这说明了配置是多么困难,并最终引导我们在整个公司实现配置的标准化。
迄今为止,我们已进入了一个阶段,而且感觉良好,希望进入生产阶段。但是,在此之前,我们需要了解新的基础设施在负载情况下的性能情况。负载均衡器是否足够好?代理层是否能够均匀地代理所有这些事情,或者我们最终会遇到瓶颈和请求排队的情况?
这非常有趣,因为它与 Zendesk 的历史有关。在我们以前的基础设施中,我们有一个 Ruby 单体应用,并且垂直扩展以适应增长。到了这一地步,我们购买了专用硬件,是 256GB 内存和 64 核 CPU 的裸机实例。接下来我们将运行 100 个 unicorn 服务。于是我们决定在它前面安装一个不可思议的高性能负载均衡器。那时候,我们的代理层不需要均衡,它也不在乎,因为我们有专门的硬件。部分原因是有意识的决定,部分原因是当时的技术不足。这种结构甚至贯穿于我们的 AWS 转型过程中,在 EC2 实例之前还有一个 AWS 弹性负载均衡器(应用程序或网络均衡器出现之前)。
但是在 Kubernetes 世界里,这个选项并不简单。为了使该应用程序稳定,我们必须了解配置和所有不同的特性。要找出不同的垂直和水平扩展特性。现在我们回顾一下,unicorn 是如何工作的,以及 NGINX 层中负载的分布。重新审视 8 年前的这些决定是痛苦的,但也是十分宝贵的。重新审视这些决定还会带来一些很好的优化,比如改变 NGINX 的负载均衡策略,这会极大地影响我们的资源利用率。

Kubernetes Pod 在改变 NGINX 上游配置前后的 CPU 使用情况在开始向 Kubernetes 迁移的时候,我们尝试让它的部署与之前的环境相匹配。如果有可能的话,我们会尽量让它们在垂直方向上变大,但是不幸的是,这仅仅是以前的四分之一。在开始均衡这些请求的时候,我们担心的是会遇到一个完全繁忙的实例。这就是名为“经典 API 流量生成器”的笨拙工具。主要是对生产环境中的前 20 个请求进行快照,并查看每个请求的数据和所占比例。流量生成器在 staging 环境中生成这些请求,并将其相应地加权以使其与生产环境大致一致。搜索是我们最大的动力之一。结果,生成器会对搜索终端产生很大的影响,请求形状也大致相似。
这样就可以在 staging 环境中找到很多有趣的发现。首先,我们没有对资源进行正确的测量。在单个 Kubernetes pod 中运行一定数量的 unicorn 进程,而该 pod 可以使用一定数量的 CPU。除非负载过重,否则没有问题。大量请求排在一起,pod 会崩溃,因此我们必须进行深入研究,“我只给它发送了 10 次请求。为何这个应用现在失败了?”最终,CPU 内存资源的上限对于这个应用程序的配置文件来说还不够高。

随着负载的增加,与现有的基础设施相比,服务器的利用率和排队情况对于我们来说,另一个巨大的挑战是将 Kubernetes 实际部署到我们的生产环境中,换句话说,把一组新的代码传递给 Kubernetes 集群中运行的东西。与在磁盘上更改文件相比,部署一个不可变的代码库实际上会做得更少,也更耗时。刚开始进行大规模试验时,它的速度非常缓慢。去年,我们花费了大量的时间和精力,通过添加工具来提前加载构件构建,从而降低了我们的部署速度。这就是说,在 EC2 专用硬件中运行新代码只需几分钟:我们会更新代码,unicorn 会顺利完成请求,工作器进程会终止,然后再重新运行新代码。
在 Kubernetes 环境中,情况就完全不同了。不能连接到 Kubernetes,也不能发出信号来执行类似 unicorn 重载的事情。即便我们能够,我们也不能将新代码放入已有的容器中,因为我们将损失所有的热重载。为了部署完整规模的 Kubernetes pod 集群,需要下载所有容器并创建所有 pod。部署时间从 2~3 分钟到 30 分钟不等,简直吓死人了。没有什么灵丹妙药,但是我们已经采取了一些重要措施来提高部署速度。
我们在 Kubernetes 浪费时间的一个原因就是对所有实例进行轮换。我们将扩展集群,但是我们没有足够的空间来运行如此大型的应用程序。一个显而易见的解决方案是“只需让集群永久性地变大”。我们的梦想当然是要运行两个完整的版本:启动一个全新的集群,将流量转移到新的集群,在旧的集群仍然存在的情况下验证它,如果有任何问题,只需拨动开关,就可以将流量送回。有时,我们确实开始怀疑是否需要将 EC2 的开销增加一倍,以确保可以进行部署。但是在当时,加倍的开支是行不通的,因此我们必须寻找其他办法来推进。
在 Kubernetes 专家的帮助下,我们花了大量时间讨论是否可以利用滚动部署。当我们开始这样做时,我们的主要关注点就变成了实际的容器,“我们如何帮助它自己更快地部署?如何才能让它在 Kubernetes 领域中更出色呢?”
容器里的工作很多。首先我们要了解的是 unicorn 工作器进程的启动顺序。从 Kubernetes 调度我们的工作负载,到工作负载对我们有用时,这个时间花了多少?结果我们发现,这个启动要用 60~90 秒钟的时间才完成。这就是说,在这个滚动部署期间,我们必须等待 90 秒才能杀死旧的一批,然后再开始新的一批:当你谈论几百个批时,这可不是件好事。
我们首先在本地绘制了启动过程的火焰图,并在各种模式下运行了启动程序。在 Rails,我们研究了“eager load”和“not eager load”。当构建 Docker 容器时,我们尝试预先加载尽可能多的内容。就是在这里,我们找到了一种最有影响力的方法,它可以减少部署时间,这样我还是觉得很有趣。在 unicorn 的启动过程中,在 unicorn 工作器被分叉后,它将回收所有连接到数据库或缓存存储的连接。正是在这里,我们找到了……一个休眠。在连接回收命令发出后,会有一秒钟的休眠,旁边会有一条注释:“给连接重置的时间”。但我们在一个容器中运行了 20~30 个 unicorn 进程。连接回收就像是一个原子操作,调用该方法回收连接,就会发生。你不必等待任何事情。如果把这条休眠线去掉,我们马上就能省下 30 秒钟。当编写任何应用程序时,如果你决定只需等待的话,这就是一个错误的选择。从规模上讲,这绝对是一个错误的选择。
最终,我们缩短了部署时间,令人满意,并逐渐投入生产。最主要的原因之一就是它的安全性。由于产品代码路径未在 staging 阶段中执行,因此我们不希望发现一些可怕的错误。我们正在转移真实客户产生的流量,不能冒着风险让 Zendesk 变得更加缓慢,也不能让错误率增加一倍。
因为我们无法负担运行 EC2 实例的两个副本,逐步推出也使我们可以一点点地获得信心。我们将推出一小部分流量来对其进行验证,让它静置几天,从我们的仪器获得信心,然后将集群减少 5%。接下来,我们按照分区一个一个来,持续 3~4 个月。
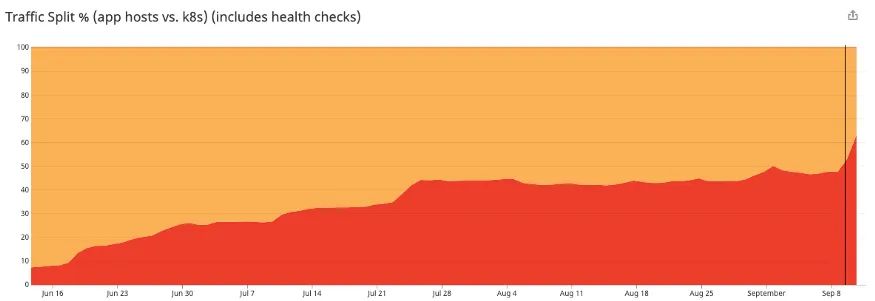
Kubernetes 部署所服务的生产流量逐渐增加它就像是一场跨越式的游戏,一个棘轮运动,我们会向上走一步,然后向下走一步。它拖慢了推出的速度,但是以一种良好的方式放慢。在开始时,我们会有 1~2% 的增量;在结束时,我们可以随意以 10~20% 的增量移动。
最后,我们达到了这样一个点:可以告诉我们的外部代理层,将 100% 的流量发送到新的基础设施。在将近两年的努力之后,我们准备开放 EC2 实例……但是,仍然需要处理旧的基础设施。结果是我们还没有处理好。这个单体包含了大部分 API,我们有许多外部用户,但是还有内部服务在运行。还有一个未知问题是,这些内部服务如何向单体发出请求。如今,我们必须寻找这些“小精灵”,找出它们为什么要跟我们“说话”,以及我们如何将它们引入新的基础设施。这一步骤令人沮丧,因为我们认为它已经完成了。但我喜欢的是,这最终让我们得到了一个标准,能够真正保证人们以一种一致的方式想请求撸油到我们的单体。对于我们来说,这是架构上的重大改进。
目前,我们已经全面进入 Kubernetes,并看到了一些意想不到的后果。到了新的规模级别,我们必须改变很多东西,包括我们如何使用 Consul、网络、DNS 配置、Etcd 集群、节点更新和集群自动调节。
我们现在已经完全进入了 Kubernetes,并看到了一些意想不到的后果。我们已经达到了新的规模水平,并且不得不改变许多事情,包括使用 Consul 的方式、网络、DNS 配置、Etcd 集群、节点更新和我们的集群自动扩缩器。

对 Kubernetes 集群度量服务器的影响是,最初启用了自动扩缩,然后被迫将其禁用
而且我们还享受着意外的收获。使我们的单体在与所有新服务相同的基础设施上运行,意味着当构建公共组件时,我们现在可以将它与 Kubernetes 绑定。通过更快的迭代,我们可以拥有标准的流程,每个人都将从中受益。就像我们最近已经修改了日志基础设施,并且免费获得了所有这些最新的日志一样。
我们现在已经 100% 使用 Kubernetes 了,感觉非常棒。在 Kubernetes 世界中,我们已经自动地进行了扩缩,转换到后台工作器,使其更有弹性。而且,Kubernetes 还迫使我们更加一致,这是一件好事。近期,我将内部的 Slack 频道 #classic-k8s-rollout 存档。那是我最喜欢的频道之一,同时也是个苦乐参半的时刻,但现在,是继续前进的时候了。
- END -
推荐阅读 最新Kubernetes实战指南:从零到架构师的进阶之路 互联网公司招聘运维工程师【内推】,7月 使用Go语言,25秒读取16GB文件 用 Python 实现快速 Ping 一个 IP 网段地址! 企业级日志平台新秀Graylog,比ELK轻量~ 下一代Docker镜像构建神器 BuildKit 面试数十家Linux运维工程师,总结了这些面试题(含答案) 七年老运维实战中的 Shell 开发经验总结 运维的工作边界,这次真的搞明白了! 搭建一套完整的企业级 K8s 集群(v1.20,二进制方式) 12年资深运维老司机的成长感悟
点亮,服务器三年不宕机

