
架构解析 | 从ABTest是啥开始说
数据驱动概念的兴起,ABTest逐渐被各互联网大厂所应用。ABTest提供了科学的分流能力,能够实施监控实验效果数据,根据用户与产品的互动情况,支持各实验版本的流量的实时调整,保证实验结果数据可靠有效,助力业务决策。
接下来,我们来具体了解下什么是ABTest。
为了验证一个新策略的效果,准备原策略A和新策略B两种方案。然后在用户群中根据一定的分流方式区分出一部分目标用户群,将这部分用户随机的分成两个组。将原策略A和新策略B分别展示给不同的用户组,一段时间后,结合统计方法分析数据,得到两种策略生效后指标的变化结果,并以此判断新策略B是否符合预期。这个过程就是ABTest(或称AB实验,也叫“对照实验”或“小流量随机实验”)。
图1-1大致描述了应用、场景、实验和流量之间的关系,为了更好的了解ABTest,我们先熟悉以下常见的名词。
1、应用
应用是对流量和系统的划分,比如商详页可以是一个应用,购物车也可以是一个应用。应用实现对流量的隔离,一个应用下可以包含多个场景。
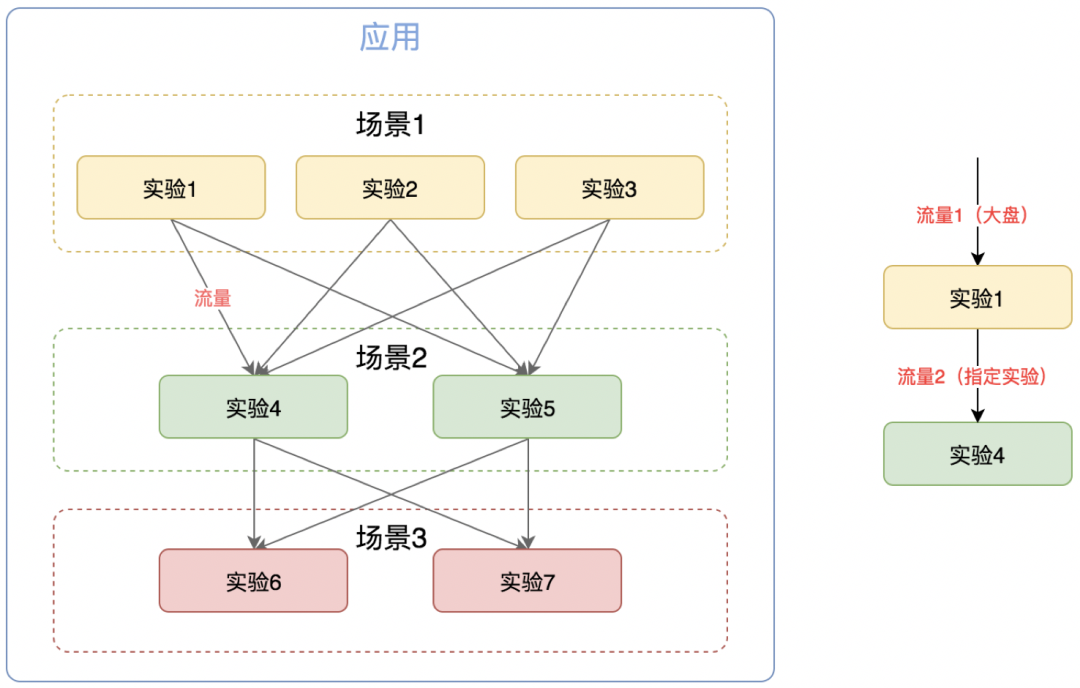
图1-1 应用、场景、实验与流量关系图
2、场景
场景是指需要对比不同策略的业务场景,场景是进行ABTest的业务单元,一个场景下可以包含1个或多个的实验(测试中的场景通常至少包含2个实验)。流量在同一应用下的不同场景之间可以被复用。
3、实验
实验代表场景下的策略,由实验配置来描述,即一份实验配置对应一种业务策略。同一个场景下的实验相互之间是互斥的,场景的分流结果仅返回一个实验。
4、流量正交
每个独立实验为一层,层与层之间流量是正交的,一份流量穿越每层实验时,都会再次随机打散,且随机效果离散,这一过程叫正交,这样的实验叫正交实验。正交实验能最大化的保证各层实验相互独立,确保各个实验不会相互影响。
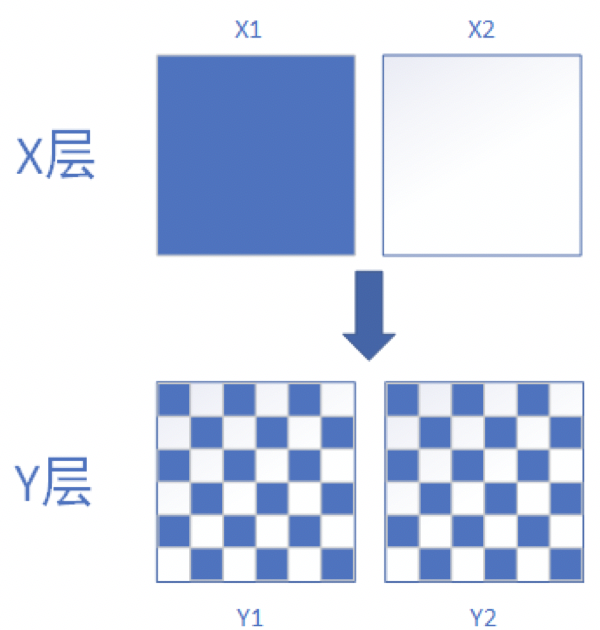
图1-2 正交实验效果图
5、流量互斥
即为在同一层中拆分流量,且不论如何拆分,不同的流量是不重叠的。互斥实验时在流量足够的情况下进行的分流策略,各个实验之间也不会相互影响。

图1-3 互斥实验效果图
6、分流器
实验中用到的一个重要组件,它的作用就是通过一定的规则将随机流动的数据分成多个版本,用户会进入分流器后会被自动分配到各个版本中,各个版本对应开发的新旧版本,从而进行稳定测试。
了解了ABTest的概念之后,如何设计ABTest呢?ABTest设计简图如图2-1所示。
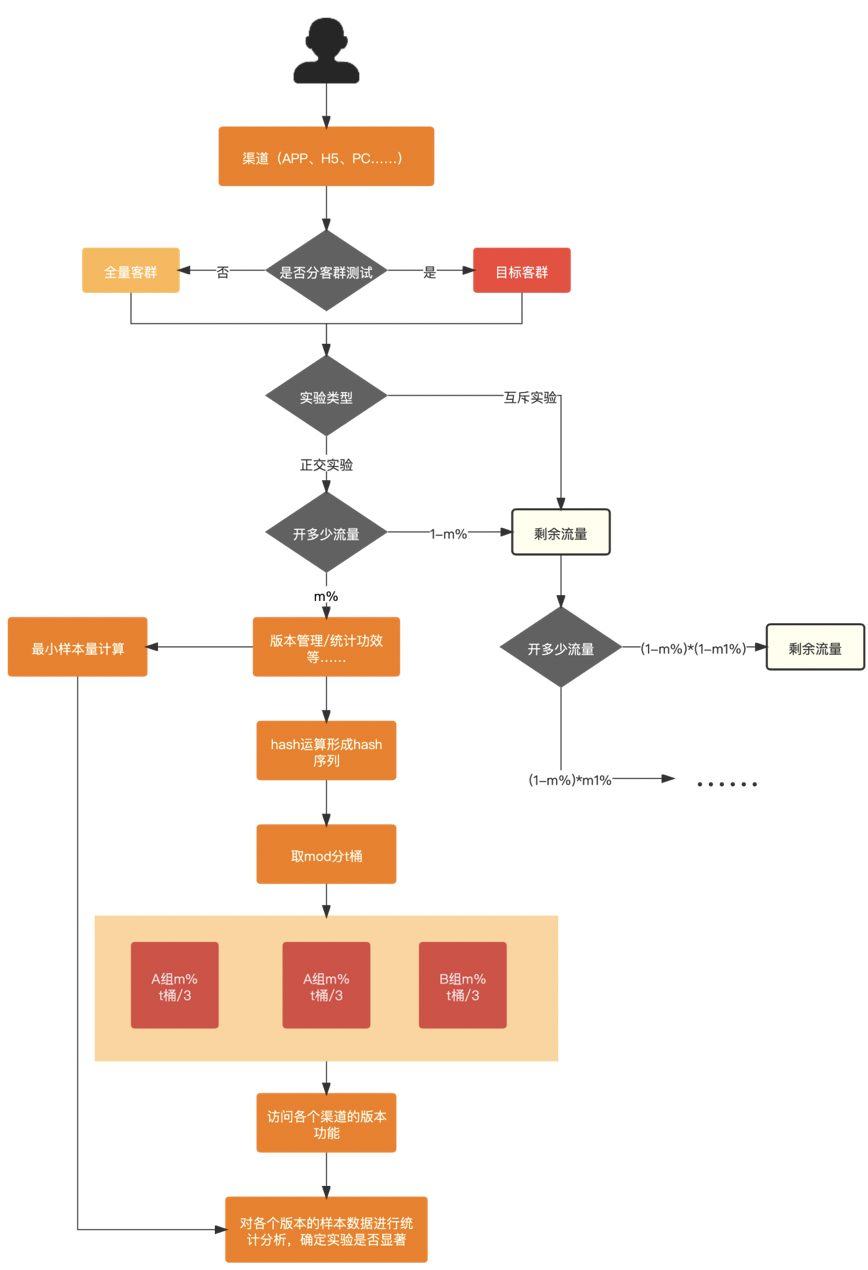
图2-1 ABTest设计思路简图
对上述ABTest实验思路简单的解释一下:
1、一个用户通过前端APP、H5或PC渠道进入系统,会在客群的部分做一次筛选,即实验是否是有划分客群,如果有客群划分,则需要判断新来的客户是否命中我们的实验客群;
2、第二步我们要判断需要进行什么类型的实验,正交还是互斥?以及此次实验需要切分多少流量,5%还是10%;
3、经过了客群识别和流量切分后,我们的客户来到了实验分组部分,系统采集客户访问的pin/uuid/deviceId信息计算出唯一hash值,并对这一hash值做mod处理;
4、mod处理之后的数据会被分到t个桶中的某一个,然后再根据一定的比例和算法将t个桶中的数据分成三组,即:A组、A组和B组,假设分流比例为:1/3,1/3,1/3;
5、A-A组即为旧版本对照组,用来检验分流是否有效,如果A-A组不显著,说明数据不受系统性因子影响,分流是有效的;A-B组即为新旧版本的对照组,其中B组为新版本;
6、A-A-B组的数据比较即为实验数据分析,分析人员借此完成实验的效果检验,确定实验是否显著。
1、单层实验
上述设计是一个ABTest实验过程,一般早期版本的ABTest实验都是单层实验,逻辑比较简单,比如使用pin/uuid/deviceId 做hash取模,将流量打到0-99,做成100份,按照实验场景做流量的分配。

图3-1 ABTest单层设计图
单层实验有如下问题:
1)扩展性差,只能同时支持少量实验。但是以数据驱动的业务,需要极快的创新速度,大量的创新需要被测试,会严重delay业务。
2)如果在单层同时进行多个实验,实验之间不是独立事件,并行的时候,同一个策略,只能进行一个实验,如果多个并行支持,无法实现。不同策略之间也有影响。
3)流量饥饿问题:假设我们整体用户要做5个实验,如果前2个实验占据了大部分的流量,后面的3个实验就有很少的流量可以供使用,甚至没有流量可用。
4)流量偏置问题:假设上游的实验把所有的年轻人都获取了,下游的实验,没有年轻人的样本。导致有偏差。
2、多层实验
如图1-1就是多层实验。对比单层实验,多层实验不用担心流量饥饿和流量偏置的问题,每一层分配的流量都是大盘的100%流量,不用担心各层实验之间的相互影响。
多层实验的优势:
1)突破限制,加速迭代:以前单层最多10个组(总流量有限,分组太多会失去置信度)。现在可以无限分层,每层100%流量再分组,理论上同时在线实验组不受限。
2)层与层间流量正交,还有业务场景间也流量正交,不用担心不同场景间的ABTest互相影响。
3、单层和多层混合实验
下图3-2是单层实验和多层实验同时进行的分层示意图。这种实验设计适合更加复杂的业务场景。
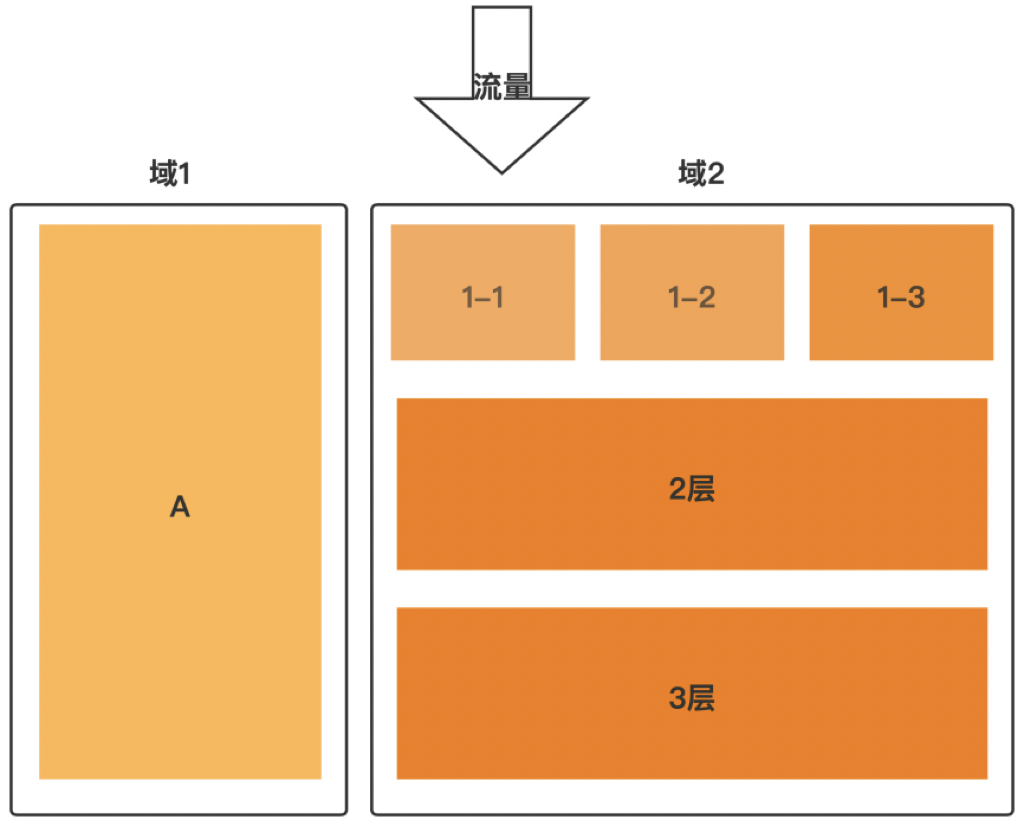
图3-2 单层和多层实验混合设计图
图3-2的分组情况可以看出:域1和域2互斥拆分流量,域2中的流量串过1-1层、1-2层、1-3层,进入到2层和3层,1-1层、1-2层、1-3层是互斥的,1层、2层、3层是正交的,上层的流量大于等于下层。
从使用场景上看,1层、2层、3层可能分别为UI层、搜索结果层、广告结果层,这几个层级基本上没有任何的业务关联度,即使共用相同的流量,也不会对实际的业务造成影响。但是如果不同层之间所进行的实验相互关联,就需要进行互斥实验。例如:1-1层是修改页面按钮上文字的颜色,1-2层是修改按钮颜色,如果按钮和文字颜色一致,估计按钮就不可用了,实验的基本原则是控制变量,即尽可能的保证每次实验只有一个变量,不要让一个变量的实验动态影响另一个变量实验,否则实验就会失去公正性。另外,如果我们觉得一个实验可能会对新老客户产生完全不同的影响,那么就应该对新客户和老客户分别展开定向实验,观察结论。
ABTest解决的是选择最优策略的问题,当我们在诸多可选策略里并不清楚哪个策略是最优的时候,ABTest可以帮助我们:1)选择更优的策略;2)避免选择更差的策略。因此,ABTest的价值包含两个方面,即更优策略的价值增量和更差策略的规避风险。我们将极限提升GMV指标作为ABTest系统的北极星指标。
极限提升GMV的定义为:在拥有两个及以上实验的场景中,平均请求转化金额最好的实验对最差实验的提升量相对于场景全部请求量的提升GMV之和,即:

其中,i为拥有两个及以上实验的场景,(i,j)为场景i中的实验j,Gmv为归因到实验的互斥GMV,Req为实验请求量。
极限提升GMV是一个理想的指标,度量了ABTest系统的价值。更全面的,ABTest系统的评价指标包括:

图4-1 ABTest评价指标图
因此,提升ABTest覆盖面,重点投入到GMV提升量更大、影响力更高的实验场景是提升ABTest实验效果的重要指标。
我们下边结合具体的项目实践,来介绍如何使用ABTest完成一次产品需求从提出到设计再到最后的实验数据分析得出结论的过程。
1、产品需求
产品同学提出需求,为了提升客服人效,提升页面的NPS,以发票小i为试点,接入ABTest平台,不加发票提示小i 为对照组A,加发票提示小i为实验组B,关注实验过程中用户浏览uv指标,以及对比历史发票相关问题的客服数据,从而评估实验组B是否与对客服人效是否有提升。
2、创建实验数据
在ABTest平台上建立实验数据。

3、SOA服务接入ABTest
SOA可通过集成SDK的方式接入ABTest平台。
下边是在我们在SOA层具体接入ABTest平台的业务逻辑代码:
/*** 获取ABTest分流结果* @param clientInfo* @param paramMap* @return*/public static Map<String,Object> getABTest(ClientInfo clientInfo,Map<String,Object> paramMap){//初始化产品线,注册试验(兜底版本为base-即对照组A)String productLine ="productLine123";//实验IDString expId = Util.toString(paramMap.get("expId"));//兜底标识-如果ABTest平台系统异常,返回兜底版本-即对照组AString baseFlag = Util.toString(paramMap.get("baseFlag"));//分流方式:1-单一试验分流 2-批量试验分流int abType = Util.toInt(paramMap.get("abType"));//切量方式:1-pin、2-userid、3-deviceIdListmode = Util.swapList(paramMap.get("mode")); ABPower abPower = new ABPower.ABPowerBuilder(productLine).register(expId,baseFlag).build();//根据pin、userid、deviceId进行分流String pin = "";String uuid = "";String deviceId = "";if (mode != null && mode.contains(1)) {pin = clientInfo.getPin();}if(mode != null && mode.contains(2)){uuid = clientInfo.getUuid();}if(mode != null && mode.contains(3)){deviceId = clientInfo.getDeviceId();}ABUser abUser = new ABUser(pin,uuid,deviceId); //默认按照pin的方式分流/*** 设置前置条件(可选)*/if(MapUtils.isNotEmpty(preCondition)) {preCondition.forEach((k,v) -> abUser.setPreCondition(k, v));}if(StringUtils.isNotEmpty(preCondition) && "version".equals(preCondition)) {abUser.setPreCondition(preCondition, clientInfo.getClientVersion());}if(abType == 1){//单一试验分流ABSingleResult abSingleResult = abPower.router(abUser,expId);result = abSingleResult.getABData();}if(abType == 2){//批量试验分流ABBatchResult abResult = (ABBatchResult) abPower.batchRouter(abUser);result = abResult.getABData();}if(result == null){return abTestResult;}}/*** 获取ABTest分流结果,将埋点数据通过客户端上报到ABTest平台,用于对照组和实验组数据分析* abTestParamMap 根据业务需求设置实验id、分流方式等基础数据*/Map<String,Object> abTestResult = getABTest(sopParam.getClientInfo(),abTestParamMap);if (MapUtils.isNotEmpty(abTestResult)) {Map<String, String> invoiceABTestExpInfo = Maps.newHashMap();invoiceABTestExpInfo.put("touchstone_expids", Util.toString(abTestResult.get("touchstone_expids")));pointData.put("invoiceABTestExpInfo", invoiceABTestExpInfo);}
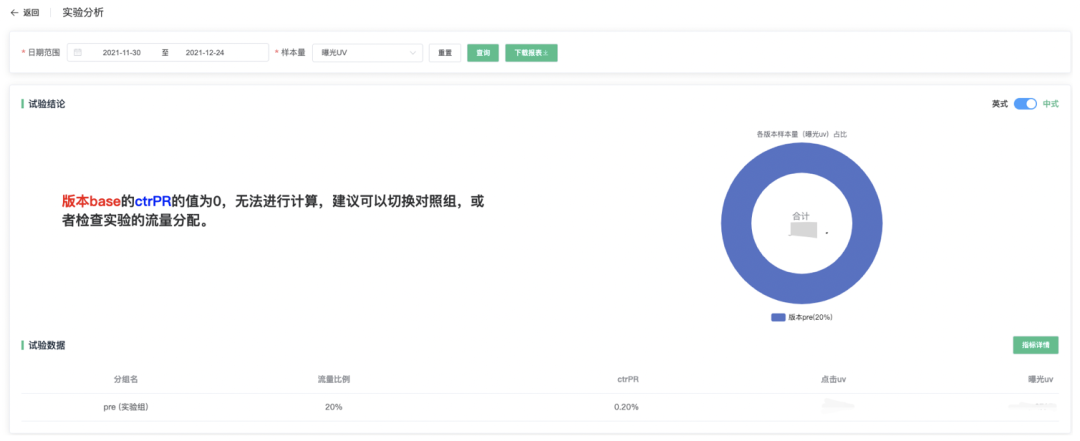
4、分析ABTest结果
因为该实验产品需求是只有漏出发票小i客户端才会上报埋点到ABTest平台,所以ABTest平台只有实验组B的数据,没有对照组A的数据。结合ABTest平台的报告和用户反馈平台历史数据量对比,发票小i的曝光对客服的人效是有提升的(用户反馈平台数据有偶然性因素,因为目前该需求还处于小流量试跑阶段,所以提升效果需要在全量实验之后效果对比更明显)。
ABTest是数据驱动增长的核心工具,我们希望通过构建ABTest系统来帮助产研小伙伴更好地做产品技术迭代和帮助商家更好地实现增长,从而也为我们接下来的数据驱动增长的探索奠定基础。