
告别Heatmap!人体姿态估计表征新方法SimDR

极市导读
本文提出了一种姿态估计的解耦坐标表征:SimDR,将关键点坐标(x, y)用两条独立的、长度等于或高于原图片尺寸的一维向量进行表征,在CNN-based和Transformer-based人体姿态估计模型上均取得了更好的表现。 >>加入极市CV技术交流群,走在计算机视觉的最前沿

论文笔记及思考:Human Pose Regression with Residual Log-likelihood Estimation(ICCV 2021 Oral)
https://zhuanlan.zhihu.com/p/395521994
论文笔记TokenPose: Learning Keypoint Tokens for Human Pose Estimation(附pytorch导出onnx说明)
https://zhuanlan.zhihu.com/p/443243421
终于,在最近我刷到了这样一篇论文,发出了大家共同的一个问题:对于姿态估计任务而言,2D高斯热图形式的特征表示真的是必要的吗?
1. 简介
首先本文列举了Heatmap-based方法饱受诟病的几大罪状:
在低分辨率图片上掉点严重:对于HRNet-W48,当输入分辨率从256x256降到64x64,AP会从75.1掉到48.5 为了提升精度,需要多个上采样层来将特征图分辨率由低向高进行恢复:通常来说上采样会使用转置卷积来获得更好的性能,但相应的计算量也更大,骨干网络输出的特征图原本通道数就已经很高了,再上采样带来的开销是非常庞大的 需要额外的后处理来减小尺度下降带来的量化误差:如DARK修正高斯分布,用argmax获取平面上的极值点坐标等
因此,本文发出疑问:用2D高斯热图表征来联合编码横纵坐标真的是维持高精度必要的吗?
在过去一年中,Transformer模型在CV领域兴起,涌现了一批不错的在姿态估计任务上的工作,如Tokenpose。尽管Tokenpose模型最终的输出依然是heatmap形式,但在模型中间的特征表示却是一维向量的形式(用一个token表征一个关键点,具体细节可以看我之前的文章),最终通过一个MLP把一维向量映射到HxW维再reshape成2D,并没有像传统FCN那样,在整个pipeline中维持2D特征图结构。这些工作说明,带有显式空间结构的高斯热图表征可能并不是编码位置信息所必需的。
于是,为了探索更高效的关键点表征方式,本文提出了一种姿态估计的解耦坐标表征,Simple Disentagled coordinate Representation(SimDR),将关键点坐标(x, y)用两条独立的、长度等于或高于原图片尺寸的一维向量进行表征,在CNN-based和Transformer-based人体姿态估计模型上均取得了更好的表现。

2. SimDR
传统的Heatmap-based方法通过2D高斯分布生成高斯热图作为标签,监督模型输出,通过L2 loss来进行优化。而这种方法下得到的Heatmap尺寸往往是小于图片原尺寸的,因而最后通过argmax得到的坐标放大回原图,会承受不可避免的量化误差。
坐标编码
在本文提出的方法中,关键点的x和y坐标通过两条独立的一维向量来进行表征,通过一个缩放因子k(>=1),得到的一维向量长度也将大于等于图片边长。对于第p个关键点,其编码后的坐标将表示为:
缩放因子k的作用是将定位精度增强到比单个像素更小的级别
坐标解码
假设模型输出两条一维向量,很自然地,预测点的坐标计算方法为:
即,一维向量上最大值点所在位置除以缩放因子还原到图片尺度。
经历了lambda次下采样的高斯热图,量化误差级别为[0, lambda/2),而本文的方法级别为[0, 1/2k)。
网络结构
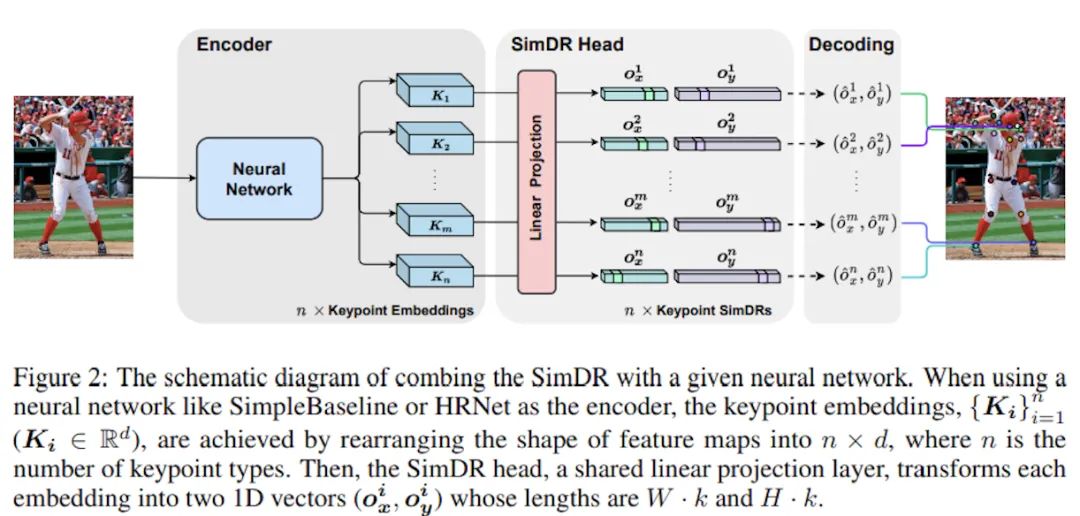
在清楚了原理后,SimDR的头部结构也就非常直观了,n个关键点对应n个embedding,也就是网络输出n条一维向量,再通过线性投影(MLP等)为n个SimDR表征。
具体地讲,对于CNN-based模型,可以将输出的特征图拉直为d维的一维向量,再通过线性投影把d维升高到W*k维和H*k维。而对于Transformer-based模型,输出则已经是一维向量,同样地进行投影即可。
训练target和目标函数
很自然地可以发现,本文的方法将关键点定位问题转化为了分类问题,因而目标函数可以使用相较于L2(MSE) Loss 性质更优的分类loss,简单起见本文使用了交叉熵。
一点私货:将定位问题转化为分类问题其实之前已经有大量的工作,比如Generalized Focal Loss工作中提出的Distribution Focal Loss,便是利用向量分布来表征bbox坐标点的位置,在轻量和精度上均取得了优异的成绩,也衍生出了有名的开源项目Nanodet。
更进一步
上面所述的SimDR存在一个问题,即作为分类问题标签是one-hot的,除了正确的那一个点外其他错误坐标是平等,会受到同等的惩罚,但实际上模型预测的位置越接近正确坐标,受到的惩罚应该越低才更合理。因此,本文进一步提出了升级版SimDR,通过1D高斯分布来生成监督信号,使用KL散度作为损失函数,计算目标向量和预测向量的KL散度进行训练:
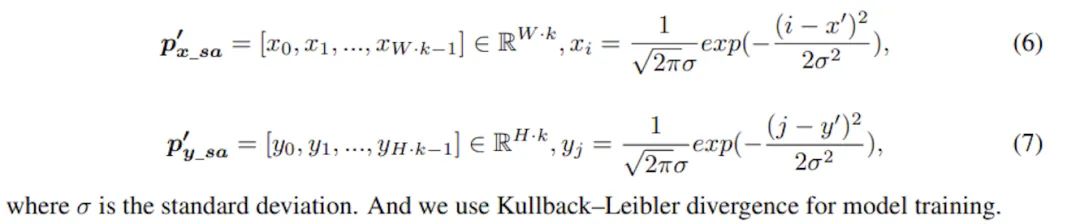
3. 实验
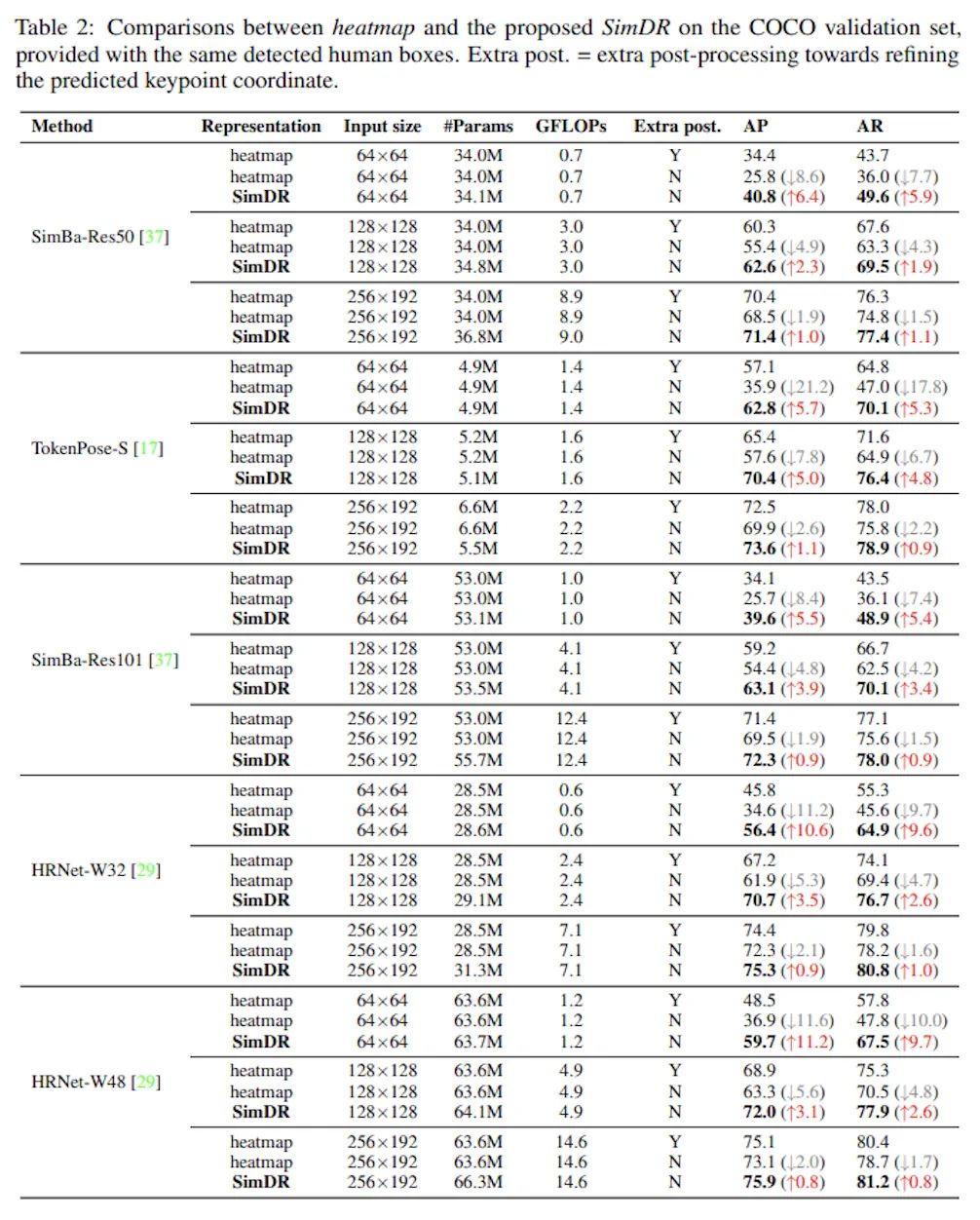
在COCO数据集上的实验对比可以看到,在小尺度(64x64)图片输入上Heatmap方法出现严重的掉点问题,哪怕是强如HRNet-W48作为backbone也难逃AP掉到50以下的厄运,而SimDR方法在更低计算量的情况下多了10.6个点的提升。
另一个值得注意的点是,Tokenpose作为Transformer-based方法,也是唯一一个在64x64图片输入上AP高于50的网络,由此可见Transformer的强大。而且这里的实验中使用的是Tokenpose-S网络,其特征提取层只由几层卷积构成,我有理由相信,如果换成Tokenpose-L等用HRNet做特征提取的结果会更加爆炸。
BTW,到这个时候我才注意到Tokenpose也是本文作者的工作,难怪如此紧跟时髦hhhh
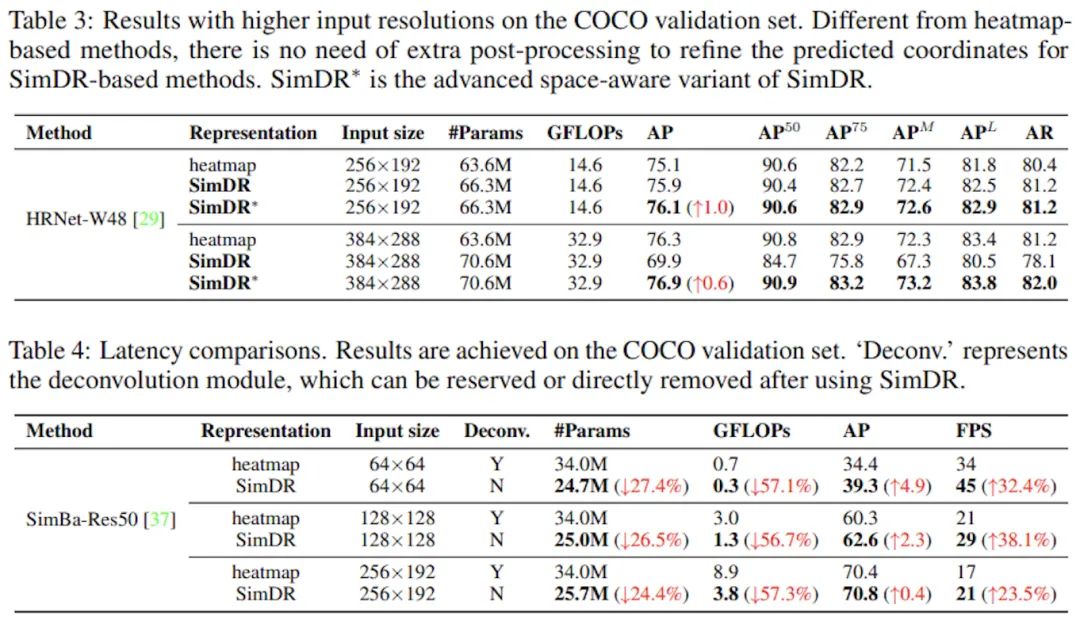
加强版SimDR的对比实验中可以看到,在较大尺度的图片输入上,SimDR也还有不错的表现,但随着图片变大,Heatmap的收益也越来越高,在大尺度384x288上甚至超越了普通版SimDR。作者分析其中的原因在于,足够大的输入图片会导致全连接层参数量过高,又因为对错误的惩罚一样,因而模型出现了过拟合,因此采用加强版SimDR来训练是更好的选择。
作者同时也表示,更加仔细地设计损失函数和监督信号能将SimDR的性能边界进一步推进。看到这一句时我瞬间想到了Tokenpose和RLE,跟这篇文章三者可以很轻松的结合起来,RLE+HRNetW48在COCO test-dev上取得的成绩为75.5AP,而本文使用加强版SimDR达到了76AP,之后我会实验一下三者的结合。
而在延迟方面,一维表征带来的提升是巨大的,在中小尺度输入上均能取得参数和精度上的优势,同时免去了Heatmap-based方法所需要的繁琐后处理和上采样开销,这些优点对于轻量级模型和需要落地部署的实时应用都是极其有利的,也是我一直以来关注的重点。
k值的选择
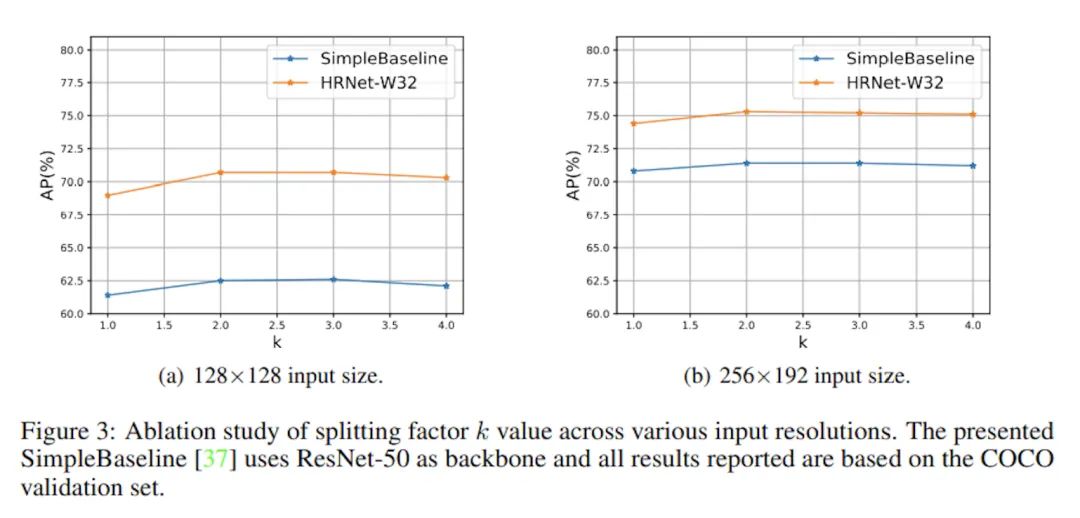
在两个CNN-based模型上验证了不同k取值的表现,总体而言k取2或3是足够优秀的,更大的k带来的收益几乎可以忽略不计了,并且为了避免过拟合的风险,越大的输入图片应该用越小的k。不过作为对超参数更敏感的Transformer,本文并没有做相关的实验,也许作为Tokenpose的作者可以也跑一下实验。
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“transformer”获取最新Transformer综述论文下载~

# 极市平台签约作者#

Tau
知乎:镜子
计算机视觉算法工程师
研究领域:姿态估计、轻量化模型、图像检索
持续学习,乐于实验总结,分享学术前沿,注重AI技术实用性和产品化
作品精选
