
3D人体姿态估计笔记
本文转自|3D视觉工坊
姿态估计
RGB or RGBD 图像 or 视频 单目 or 多视角 单人 or 多人 2D or 3D 3D姿态 or 3D形态

任务
单人姿态估计 Benchmark: MPII (2014) 代表作: CPM (CVPR 2016), Hourglass (ECCV 2016) 多人姿态估计 Benchmark: COCO (2016), CrowdPose (2018) 自底向上: OpenPose (CVPR 2017), Associative Embedding (NIPS 2017) 自顶向下: CPN (CVPR 2018), MSPN (Arxiv 2018), HRNet (CVPR 2019) 人体姿态跟踪 Benchmark: PoseTrack (2017) 代表作: Simple Baselines (ECCV 2018)
挑战
遮挡 复杂背景 特殊姿态

3D姿态估计
问题
输入: 包含人体的图片 输出: N×3个人体关节点
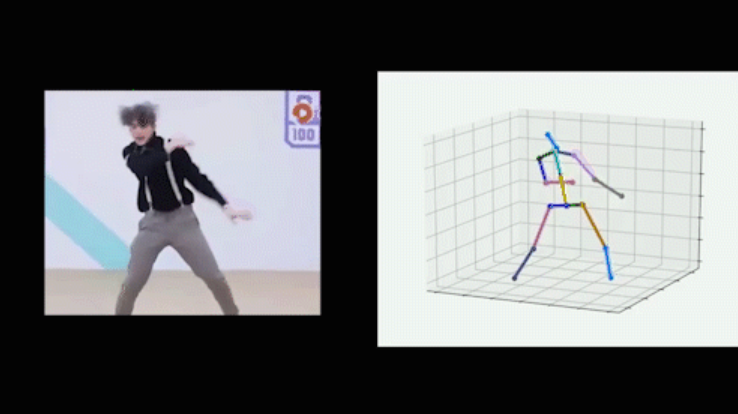
巨大的3D姿态空间、自遮挡 单视角2D到3D的映射中固有的深度模糊性、不适定性(一个2D骨架可以对应多个3D骨架) 缺少大型的室外数据集(主要瓶颈) 缺少特殊姿态的数据集(如摔倒,打滚等) 由于数据集是在实验室环境下建立的,模型的泛化能力较差 3D姿态数据集是依靠适合室内环境的动作捕捉(MOCAP)系统构建的。MOCAP系统需要带有多个传感器和紧身衣裤的复杂装置,在室外环境使用是不切实际的

应用
动画,游戏 运动捕捉系统 行为理解 姿态估计可以做为其他算法的辅助环节(行人重识别) 人体姿态估计跟人体相关的其他任务一起联合学习(人体解析)

方法
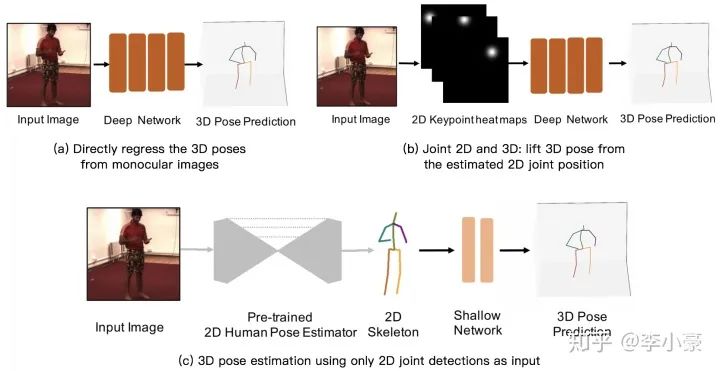
从2D图片直接暴力回归得到3D坐标 3D Human Pose Estimation from Monocular Images with Deep Convolutional Neural Network (ACCV 2014) Coarse-to-Fine Volumetric Prediction for Single-Image 3D Human Pose (CVPR 2017) 通过深度学习模型建立单目RGB图像到3D坐标的端到端映射,但是对于单一模型来说需要学习的特征太过复杂。 先获取2D信息,然后再“提升”到3D姿态 联合2D,3D共同训练(2D信息通常以heatmap来表示) Towards 3D Human Pose Estimation in the Wild (ICCV 2017) 3D Hand Shape and Pose Estimation from a Single RGB Image (CVPR 2019) 需要复杂的网络架构和充足的训练样本。 直接用预训练好的2D姿态网络,将得到的2D坐标输入到3D姿态估计网络中(得益于2D姿态估计较为成熟) Simple Yet Effective Baseline (ICCV 2017) 3D human pose estimation in video with temporal convolutions (CVPR 2019) 2D姿态网络: Hourglass (ECCV 2016), CPN (CVPR 2018) 优点 减少了模型在2D姿态估计上的学习压力 网络结构简单,轻量级 实时性,快速 训练快,占用显存少 缺点 缺少原始图像输入,可能会丢失一些空间信息 2D姿态估计的误差会在3D估计中放大 为什么要先进行2D估计再进行3D估计? 因为基于检测的模型在2D的关节点检测中表现更好,而在3D空间下,由于非线性程度高,输出空间大,所以基于回归的模型比较流行。
数据集
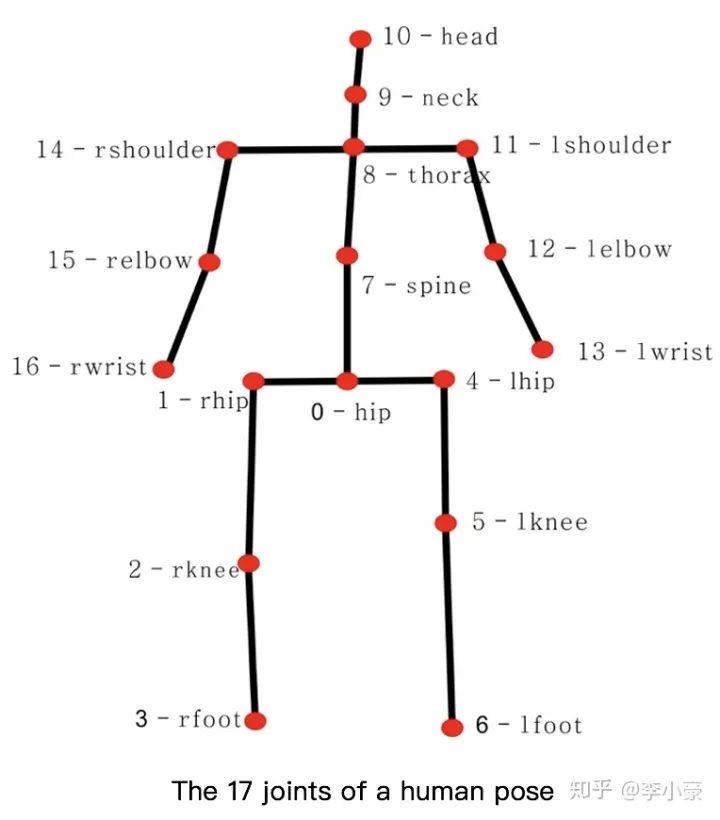
Human3.6M (2014) 3D姿态估计最大、最广泛使用的数据集 360万张图像,4个不同的视角 (原数据集提供的是视频,50fps) 15个动作: directions, discussion, eating, greeting, phoning, posing, purchases, sitting, sitting down, smoking, taking photo, waiting, walking, walking dog, walking together 11 个人,但只有7个人包含3D姿态标签 训练: S1, S5, S6, S7, S8 (1559752张图像) 测试: S9, S11 (550644张图像) 备注:实际使用的时候只用了7个人的数据,总共210万张图像,所以我感觉应该称为Human2.1M。而且从原数据的视频中提取出图片的时候,提取出的图片数会比标签要多,提取出来有2137070张图像,而标签只有2110396个。在使用这个数据集的时候将每个视频舍弃尾部几帧多出来的图像使得与标签一一对应。 HumanEva (2010) MPI-INF-3DHP (2017)

评价指标
Mean Per Joint Position Error (MPJPE): Protocol 1,关节点坐标误差的平均值 网络输出的关节点坐标与ground truth的平均欧式距离(通常转换到相机坐标) Procrustes analysis MPJPE (P-MPJPE): Protocol 2,基于Procrustes分析的MPJPE 先对网络输出进行刚性变换(平移,旋转和缩放)向ground truth对齐后,再计算MPJPE Percentage of Correct Key-points (PCK),正确关键点的百分比 如果预测关节与ground truth之间的距离在特定阈值内,则检测到的关节被认为是正确的 Percentage of Correct Parts (PCP),正确部件的百分比 如果两个预测的关节位置与ground truth之间的距离小于肢体长度的一半,则认为肢体被检测到 备注:做3D的问题,需要掌握各个坐标系间的转换,如世界坐标、相机坐标、图像坐标等。可参考以下两篇博文 计算机视觉:相机成像原理:世界坐标系、相机坐标系、图像坐标系、像素坐标系之间的转换 相机成像模型——建立过程(世界坐标系,相机坐标系,图像坐标系,图像像素坐标系,四者之间的关系
监督方法
弱监督: 不直接用标签,而用其他信息计算Loss 深度图、点云、网格、GAN、3D投影到2D 半监督 3D投影到2D 自监督 全监督
视频序列的优点
当前帧有遮挡的时候,可利用相邻帧的完整性解决这个问题 由于单独预测每个帧的3D姿态时,每个帧中的结果与其他帧无关,会导致输出不连贯,带有视频抖动 单张图片包含的深度信息是有限的,网络可以从序列中挖掘到更丰富的深度信息 一张2D图片可以对应无穷多个3D姿态,让模型“多看”同个视角不同时间人的图片,可以减少深度模糊性,缩小3D姿态的空间范围
3D形态估计
问题
3D形态的表示
网格: 由三角形组成的多边形网格 深度图: 每个像素值代表的是物体到相机xy平面的距离 体素: 三维空间中的一个有大小的点,一个小方块,相当于是三维空间中的像素 点云: 某个坐标系下的点的数据集。点包含了丰富的信息,包括三维坐标xyz、颜色、分类值、强度值、时间等
SMPL(A Skinned Multi-Person Linear Model)
3D Mesh: SMPL 输入 (82): Shape  + Pose
+ Pose
各个参数代表人体哪个部分?可参考“SMPL模型Shape和Pose参数” 输出: Mesh 
优点: 只需要估计少量的参数便可得到包含6890个顶点的高质量的人体3D Mesh 3D Pose 可从3D Mesh中回归得到,其中  为预先训练好的线性回归器
为预先训练好的线性回归器

2D Pose 可从3D Pose中使用相机内参计算得到

Reference
人体姿态估计的过去,现在,未来 重新思考人体姿态估计 人体姿态估计(Human Pose Estimation)经典方法整理 A 2019 guide to Human Pose Estimation with Deep Learning 从DeepNet到HRNet,这有一份深度学习“人体姿势估计”全指南 A 2019 guide to 3D Human Pose Estimation Human Pose Estimation 101 3D人体姿态估计最新研究2019 3D姿态估计:语义图卷积SematicGCN与GAN-RepNet 谈谈三维形态估计 人体3D姿态重建与估计 基于深度学习的视觉三维重建研究总结
 End
End
声明:部分内容来源于网络,仅供读者学术交流之目的。文章版权归原作者所有。如有不妥,请联系删除。
评论