
FCOS 经典的一阶段Anchor-Free检测算法

FCOS详解
总述
FCOS是近年来优秀的anchor free目标检测算法,本文将对论文中的创新点进行尽量详细的分析。
前情提要
在anchor free算法出现前,检测网络大多采用的是anchor based的算法思路,其主要流程为 backbone提取图像特征 -- FPN从backbone提取到的不同分辨率的特征层中构建特征金字塔 -- 在特征金字塔的不同层上建立多个anchor来构建规划正负样本,并计算损失值回传进行网络参数的优化更新。而anchor base类算法,我们也可以理解为,尝试将anchor的设计过程中每个anchor的高、宽,特征图上的每个像素点位置安排的anchor数目等经验值去掉,从而进一步减少超参数。
FCOS中聚焦的问题
FCOS中,作者思考如何将检测网络模型的超参数进一步的降低,作者看到FCN全卷积网络在分割等任务上的成功,也看到了DenseBox、UintBox等尝试将FCN网络应用于检测任务,其核心思想就是在每个像素点上直接回归出当前像素点所指向目标的类别和最小包围框,从而去掉了anchor的超参数设计流程。 但是在每个像素点回归,仍旧存在一个问题:当一个像素点同时位于两个Ground Truth的最小外接矩形框内时,如何判定当前像素点位置应该回归重叠框中的哪一个目标,因为只有能判定当前像素点的归属才能合理的计算损失值从而回传优化网络参数。
FCOS中给出的解决方案
在FCOS中,作者尝试在FPN得到的多个特征图上逐像素点直接进行回归,然后通过在不同层上设置回归阈值,来判断当前特征图的当前特征点位置的回归结果是否合理,对不合理的回归结果直接判定为负例。作者这么做的思路也是基于不同层的特征图用于回归不同尺度的目标,而当一个像素点位置回归具有歧义时,多发生在两个尺度相差较大的目标间。「通过限制不同特征层的最大回归尺寸,也就是使得浅层只用于回归较小的目标,而深层回归较大的目标」。具体如下:
设为FPN输出的特征图,在每个的每个像素点位置上回归一个检测框的偏移量数组,记为$PB = {l^,r^,b^,t^}m_iF_im_i=[0,64,128,256,512,∞]max(l^∗,t^∗,r^∗,b^∗) > m_imax(l^∗,t^∗,r^∗,b^∗) < m_{i-1}$ 时,将当前回归结果直接判定为负样本。作者这么做的目的就是在网络训练的时候直接限制了不同层的特征图回归指定尺寸的目标,而且作者通过实现发现,大部分的像素点回归歧义问题,即一个像素点位置位于两个目标最小外接矩形相交位置时不好确定当前位置回归的框应指向哪个目标,在采用FPN输出的特征图上进行分类和回归时会得到消解。若仍旧存在歧义性问题,「则当前像素点位置回归目标指定ground truth面积较小的一个」。
FCOS训练过程
首先贴上FCOS的整个网络图:
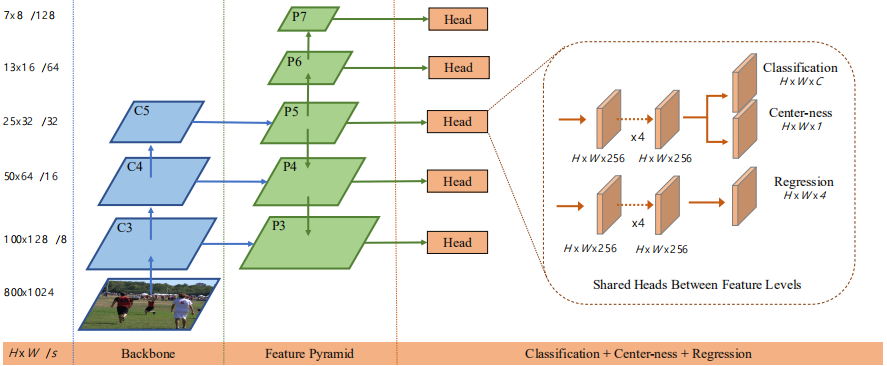
1、首先输入图像并通过FPN获取特征图,然后在每个特征图上进行逐像素点的分类和回归,分类输出HxWxC,其中C为类别数,回归输出HxWx4,其中的四个通道分别为以当前像素点位置对应的原图位置为中心,其所指向目标的最小外接矩形四个边界到中心点的距离值。其中回归输出,作者考虑到最终均为正值,所以通过4通道的值代入exp()函数使得其值域为(0,+∞),作者首先尝试在FPN输出的各级特征图上共享头卷积,但是对回归头来说不同的特征图所分配的回归目标尺寸区间不一致,为了增强适用性,作者最后采用的exp函数为 即对不同层FPN输出特征图设置一个可学习参数
2、「正负样本的划分」,作者规定正样本为:当特征图上某像素点落在Ground Truth区间内时,其为正样本。论文中提及的训练细节则说明,作者考虑当前像素点位置的分类分数大于0.05的,当前像素点回归目标框在指定范围内的(符合当前层特征图指定范围的),指定为正样本,当前回归框的类别为目标框类别,其余为负样本。(作者原文里没有说当回归出现歧义的时候类别如何设定,但是既然出现歧义时回归指向面积较小的GT那么类别标签应当也是指向同样的目标)
3、「损失函数」,作者损失函数公式为
其中,分类损失函数采用的是Retinanet中的Focal loss;回归损失函数采用的是UnitBox中的IOU损失,回归损失的具体计算为:。作者的值取的1,则表示,当前的类别标签为非背景类,即时为1,否则为0,实际作者还添加了另一个损失,将在下一节介绍
FCOS的其余改进
作者参考了Retinanet,将最后的分类器从多分类器改为了多个类别的二分类器,有兴趣的同学可以去看看这篇论文的原文。 作者在实际网络训练时发现,其网络模型的性能并没有达到和anchor base相同的程度,观察和分析结果发现是在正负样本选择时,虽然扩大了输入的正样本,但是也同步的生成了很多远离目标中心的负样本,然后作者通过添加centerness分支来评价每个像素位置距离当前目标中心的程度值来达到对正负样本的筛选,从而降低了远离目标中心回归框对训练的影响,提高了网络的精度。
centerness分支前向流程、损失计算:
首先我们看FCOS的整个网络图,centerness分支是放在分类分支一起的,多添加了一个卷积层。所以测试时前向输出的分数就是分类分数和centerness的乘积。centerness分支的损失计算为:首先能够由前向时的步长确定原图中的GT中心点对应的当前特征图的像素位置,然后前向卷积计算得到的回归值为,那么中心度损失就可以通过以下公式计算。因为该值是在[0,1]区间内的,所以就可以用BCEloss来计算该部分损失并加到总的损失函数里即为完整的损失。在论文里作者说明有两种中心度的计算方式,一种就是以该公式,从回归的结果计算得到,一种就是像图上那种通过网络层直接卷积得到分数。「作者试验说明用网络直接卷积得到的中心度分支表现最好」。
个人思考
(这个部分没做过试验验证,纯粹是自己的一点想法,大家听听就好)因为我是先看的centernet再看的FCOS,所以就觉得,centernet里的高斯核映射和centerness分支其实有一定的相似性的,这两种方式我学习到的就是,虽然基于像素点做回归增加了正样本数量,但是越靠近目标边缘的正样本其给训练模型带来的贡献越低,但是这两者中也有一个假设,就是不管是高斯核还是中心度其实都是圆形分布,但是我们知道以行人为目标的话,其实可能椭圆型更加合适,那么如果在centernet的高斯核部分,由输入样本确定一个统计参数来调整核函数呢?是不是会有更高的性能;在FCOS中的话,centerness分支计算得到的是[0,1]之间的值,其实就是一个smooth的前背景分类网络,或者说分割网络。那么物体检测来说,其中心是不是应该是一个椭圆型区域,这部分如何构建来帮助更好的正负样本选取呢?《Bridging the Gap Between Anchor-based and Anchor-free Detection》这篇论文也说了,区分anchor base和anchor free的就是正负样本的选取,那么我觉得这个点是可以做的。
欢迎关注GiantPandaCV, 在这里你将看到独家的深度学习分享,坚持原创,每天分享我们学习到的新鲜知识。( • ̀ω•́ )✧
有对文章相关的问题,或者想要加入交流群,欢迎添加BBuf微信:
为了方便读者获取资料以及我们公众号的作者发布一些Github工程的更新,我们成立了一个QQ群,二维码如下,感兴趣可以加入。