
hadoop之MapReduce推荐系统实战
需求背景
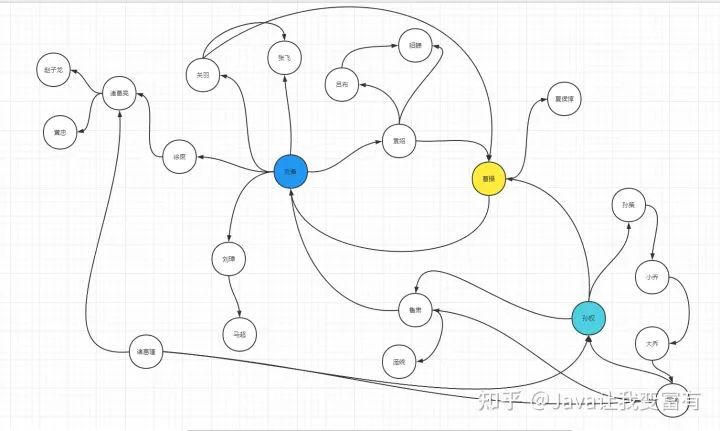
前边已经使用mapReduce找到了每个月中温度最高的两天。现在我们来看看平时的社交软件,推荐系统的机制是怎样的,其实也是非常简单。如下图所示,我们需要给每个人推荐好友,既然是推荐的,肯定需要符合以下规则:
1 两人不能是好友
2 两人最有可能认识,定义关系链条只能跨越一个人,不能跨越两个人。
例如,可以推荐的人:
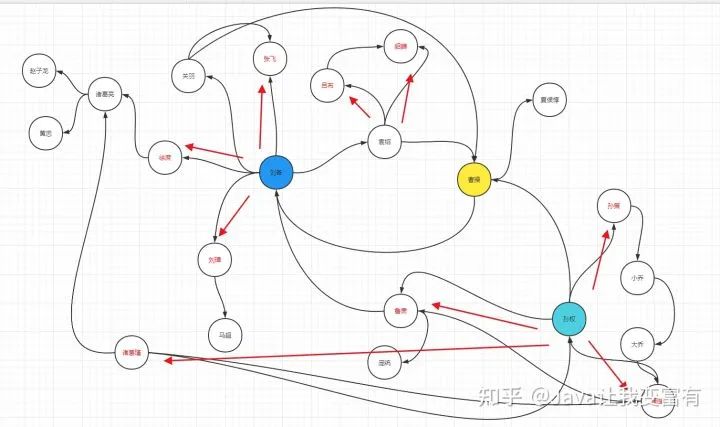
从下图,我们可以看出来,要给刘备推荐的好友列表是:诸葛亮(徐庶推荐),马超(刘璋推荐),貂蝉(袁绍推荐),吕布(袁绍推荐),夏侯惇(曹操推荐),庞统(鲁肃推荐),孙权(鲁肃推荐)。
不可以推荐的人:
赵子龙,因为已经跨越了徐庶和诸葛亮两个人了。曹操,因为刘备和曹操就是好友。
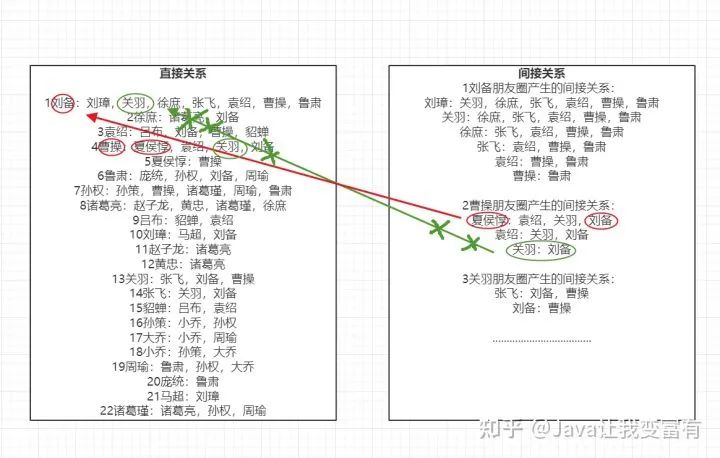
接下来我们知道了规则之后,我们先将图谱分为两个map,其中一个map用来匹配直接关系,一个map用来匹配间接关系。然后从间接关系中排除掉直接关系,剩下的就是可以推荐的人选。
直接好友
如下图示例,我们先列出来这22个人的直接关系数据,只要是两者相连的的,肯定是直接好友。

间接好友:
如下图,由于一个人的朋友圈的人,很可能相互认识,所以只要是和这个人认识的,都是间接好友关系。当然,可能这两个间接好友,早都已经加了好友了。

刘备认识曹操,曹操圈子里,刘备和夏侯惇是间接好友关系。然后我们看到刘备的直接好友里面没有夏侯惇,这个时候我们就可以通过曹操给刘备推荐夏侯惇。
然后,虽然曹操圈子里,关羽和刘备是间接好友关系,但是我们在刘备好友列表中找到了关羽,是直接好友。所以不能通过曹操给刘备推荐关羽。
而且我们看到了,目前只有22个人的时候,我们可以很轻松的列出来直接好友关系,但是间接好友的数据量就会是比较庞大的。因此我们开始借助程序来完成好友推荐功能。
数据模型
首先第一步当然是根据需求来构建我们的数据模型了,让我们的程序能够更好的批量处理数据之间的关系。以下便是我们此次构建出来的数据模型,每一行代表第一个人与后边的人都是直接好友关系。(数据模型后续有更改,不可直接搬运,不过出错了可以自己调节也算是锻炼!!!)

上传数据文件
数据模型建立好之后,我们就该上传文件至hdfs了。
hdfs dfs -D dfs.blocksize=1048576 -put friend.txt /data/friend/input编写程序
mapper
map中,我们主要是通过遍历每一行,来将每一行的直接朋友关系和间接朋友关系写入文件中。很显然,每一行的第一列和后边的所有列都是直接好友。从第二列开始,两两互成间接好友关系。同时我们将两个人关系进行排序,否则,刘备-关羽,和关羽-刘备 程序会识别为不同的组合。
/**
* @author Ted
* @version 1.0
* @date 2022/2/2 16:19
*/
public class FMapper extends Mapper<LongWritable,Text,Text,IntWritable> {
Text mkey = new Text();
IntWritable mval = new IntWritable();
/**
* 刘备 刘璋 关羽 徐庶 张飞 袁绍 曹操 鲁肃
* 徐庶 诸葛亮 刘备
* 袁绍 吕布 刘备 曹操 貂蝉
* @param key
* @param value
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//value:刘备 刘璋 关羽 徐庶 张飞 袁绍 曹操 鲁肃
String[] directFriends = StringUtils.split(value.toString(), ' ');
//间接关系为1 , 直接关系为 0
for (int i=1;i<directFriends.length;i++){
mkey.set(getFriendPair(directFriends[0],directFriends[i]));
mval.set(0);
// 写入文件
context.write(mkey,mval);
for (int j=i+1;j<directFriends.length;j++){
mkey.set(getFriendPair(directFriends[i],directFriends[j]));
mval.set(1);
//写入文件
context.write(mkey,mval);
}
}
}
/**
* 排序
* @param person1
* @param person2
* @return
*/
public static String getFriendPair(String person1,String person2){
if(person1.compareTo(person2)>0){
return person1+"-"+person2;
}else {
return person2+"-"+person1;
}
}
}reducer
reduce中,我们对map产生的文件进行读取,由于两两一组,value是0代表直接关系,value是1代表间接关系。我们判断如果这两人有直接关系,存在为0的情况,这组推荐关系抛弃掉。如果都是1,我们就将每一组相同的key值相加,来判断间接关系的权重。
/**
* @author Ted
* @version 1.0
* @date 2022/2/2 16:33
*/
public class FReduce extends Reducer<Text,IntWritable,Text,IntWritable> {
IntWritable rValue = new IntWritable();
/**
* 一组key值 每个key代表的是某个两个人,同时分到一个组,值就是这两个人到底是直接朋友,还是间接朋友
* 如果最后循环最后,没有一个是0的,那么两个人肯定是间接关系,rValue就是间接关系的深度
* 如果间接关系深厚,关联的好友很多,那么就优先推荐。
* @param key
* @param values
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
// 刘备 关羽 0
// 刘备 关羽 0
// 刘备 关羽 1
// 刘备 关羽 1
int flag = 0;
int sum = 0;
for (IntWritable val: values){
if(val.get()==0){
flag = 1;
}
sum = val.get();
}
if(flag == 0){
rValue.set(sum);
context.write(key,rValue);
}
}
}客户端程序
/**
* @author Ted
* @version 1.0
* @date 2022/2/2 16:16
*/
public class MyFriend {
public static void main(String[] args) throws Exception{
Configuration configuration = new Configuration(true);
// 获取客户端启动 指定参数列表
String[] params = new GenericOptionsParser(configuration, args).getRemainingArgs();
configuration.set("mapreduce.app-submission.cross-platform","true");
// 创建任务
Job job = Job.getInstance(configuration);
job.setJarByClass(MyFriend.class);
job.setJobName("myFriend");
job.setJar("D:\\javaEngineer\\javaproject\\hadoop\\hadoophdfs\\target\\hadoop-hdfs-1.0-0.1.jar");
// 输入路径
TextInputFormat.addInputPath(job,new Path(params[0]));
Path outputFile = new Path(params[1]);
if(outputFile.getFileSystem(configuration).exists(outputFile)){
outputFile.getFileSystem(configuration).delete(outputFile,true);
}
// 输出路径
TextOutputFormat.setOutputPath(job,outputFile);
// 设置Map 参数
job.setMapperClass(FMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//设置reduce参数
job.setReducerClass(FReduce.class);
// 执行任务 等待结束
job.waitForCompletion(true);
}
}启动hadoop集群
程序写好了,接下来当然是启动我们的hadoop集群了。
配置启动参数
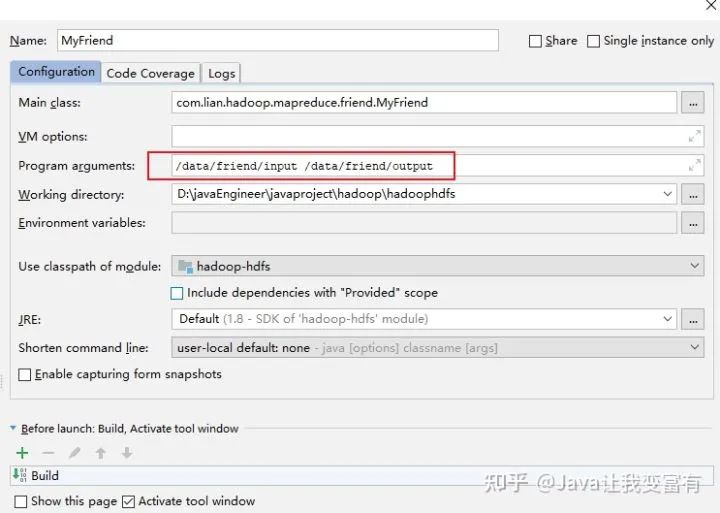
接下来我们来指定mapReduce需要的参数,其中输入路径和输出路径是最基本的要求,剩下的排序分组分区我们都采用系统默认的方式。
启动客户端
然后我们开始运行客户端,得到如下文件。
hdfs dfs -ls -R /data/friend
我们可以看看里面的内容是不是和真实的场景相吻合。
hdfs dfs -cat /data/friend/output/part-r-00000乱码
分析原因
可以看到上传的文件也是乱码的。
将文件另存为为UTF-8编码格式之后,文件正常
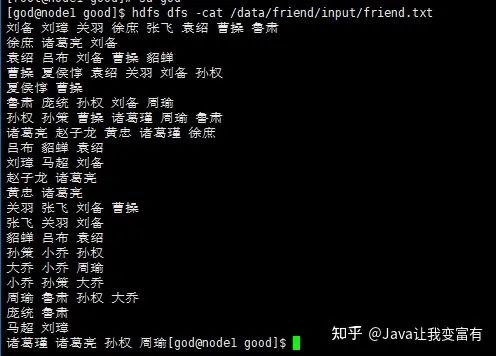
重启客户端
输出结果如下。
刘璋-关羽 1
吕布-刘备 1
周瑜-刘备 1
夏侯惇-关羽 1
夏侯惇-刘备 1
孙权-关羽 1
孙权-刘备 1
孙权-夏侯惇 1
孙权-大乔 1
孙策-周瑜 1
孙策-大乔 1
小乔-周瑜 1
小乔-孙权 1
庞统-刘备 1
庞统-周瑜 1
庞统-孙权 1
张飞-刘璋 1
徐庶-关羽 1
徐庶-刘璋 1
徐庶-张飞 1
曹操-刘璋 1
曹操-吕布 1
曹操-周瑜 1
曹操-孙策 1
曹操-张飞 1
曹操-徐庶 1
袁绍-关羽 1
袁绍-刘璋 1
袁绍-夏侯惇 1
袁绍-孙权 1
袁绍-张飞 1
袁绍-徐庶 1
诸葛亮-刘备 1
诸葛亮-周瑜 1
诸葛亮-孙权 1
诸葛瑾-孙策 1
诸葛瑾-徐庶 1
诸葛瑾-曹操 1
貂蝉-刘备 1
貂蝉-曹操 1
赵子龙-徐庶 1
赵子龙-诸葛瑾 1
马超-刘备 1
鲁肃-关羽 1
鲁肃-刘璋 1
鲁肃-大乔 1
鲁肃-孙策 1
鲁肃-张飞 1
鲁肃-徐庶 1
鲁肃-曹操 1
鲁肃-袁绍 1
鲁肃-诸葛瑾 1
黄忠-徐庶 1
黄忠-诸葛瑾 1
黄忠-赵子龙 1我们截取给曹操推荐的朋友圈人选
曹操-刘璋 1 曹操-吕布 1 曹操-周瑜 1 曹操-孙策 1 曹操-张飞 1 曹操-徐庶 1
鲁肃-曹操 1 貂蝉-曹操 1 诸葛瑾-曹操 1
再来看下关系图谱,可以看出来是正确的,权重关系都为1。
增加复杂度
接下来我们增加一下关系复杂度,让徐庶加张飞和关羽好友,让诸葛亮加刘备为好友,接下来,诸葛亮通过徐庶和刘备两个人,会和张飞关羽分别产生两次间接关系。图谱变为如下样子:
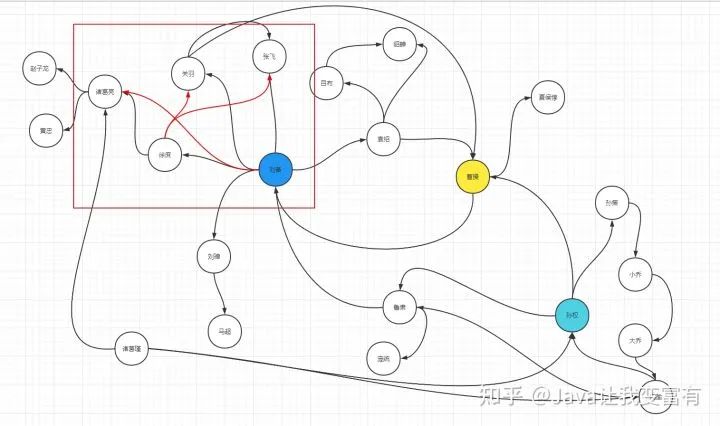
数据模型变为如下样子,再次上传文件,运行客户端程序。
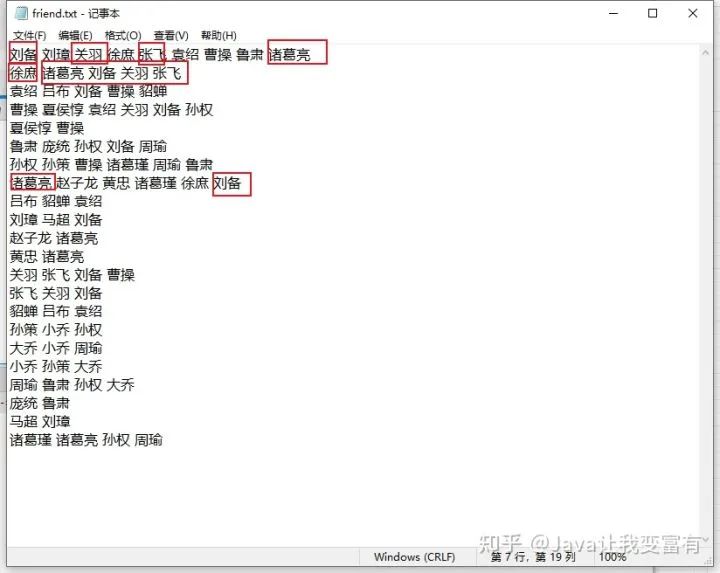
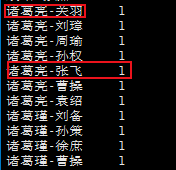
得到结果如下,发现并不是想象的样子。
取消reduce
接下来我们取消reduce任务,只进行输出map文件,来调节bug。
// 如果将reduce任务设置为0,那么就可以得到map输出
job.setNumReduceTasks(0);输出map文件如下:

很明显,从map中,我们看到了两个诸葛亮-关羽,两个诸葛亮-张飞,因此reduce中的代码是有错误的。并没有正确完成权重相加。
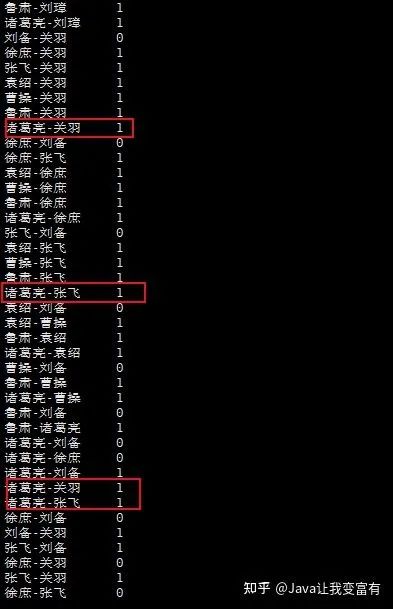
最后发现代码书写错误,居然只写了等于号。
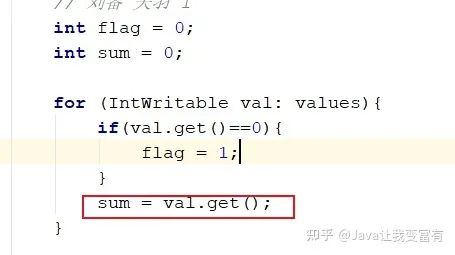
修改代码,程序正确之后,我们重新maven打包。一定要maven打包,不然jar中的代码还是原先的代码。
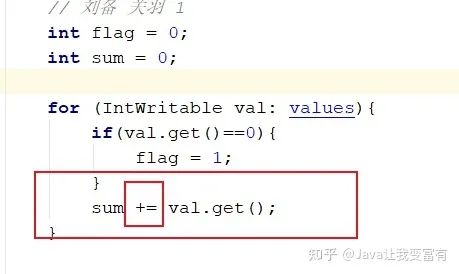
添加reduce
修改代码,再次开放reduce任务。获取结果如下。可以看到,诸葛亮-关羽的权重是2,诸葛亮-张飞的权重是2,应该优先给诸葛亮推送张飞和关羽这两位好朋友。
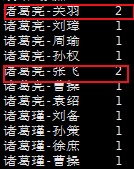
最终结果如下图,我们可以总hadoop的web端下载文件。
刘璋-关羽 1
吕布-刘备 1
周瑜-刘备 1
夏侯惇-关羽 1
夏侯惇-刘备 1
孙权-关羽 1
孙权-刘备 2
孙权-夏侯惇 1
孙权-大乔 1
孙策-周瑜 1
孙策-大乔 1
小乔-周瑜 1
小乔-孙权 1
庞统-刘备 1
庞统-周瑜 1
庞统-孙权 1
张飞-刘璋 1
徐庶-刘璋 1
曹操-刘璋 1
曹操-吕布 1
曹操-周瑜 1
曹操-孙策 1
曹操-张飞 2
曹操-徐庶 1
袁绍-关羽 2
袁绍-刘璋 1
袁绍-夏侯惇 1
袁绍-孙权 1
袁绍-张飞 1
袁绍-徐庶 1
诸葛亮-关羽 2
诸葛亮-刘璋 1
诸葛亮-周瑜 1
诸葛亮-孙权 1
诸葛亮-张飞 2
诸葛亮-曹操 1
诸葛亮-袁绍 1
诸葛瑾-刘备 1
诸葛瑾-孙策 1
诸葛瑾-徐庶 1
诸葛瑾-曹操 1
貂蝉-刘备 1
貂蝉-曹操 1
赵子龙-刘备 1
赵子龙-徐庶 1
赵子龙-诸葛瑾 1
马超-刘备 1
鲁肃-关羽 1
鲁肃-刘璋 1
鲁肃-大乔 1
鲁肃-孙策 1
鲁肃-张飞 1
鲁肃-徐庶 1
鲁肃-曹操 2
鲁肃-袁绍 1
鲁肃-诸葛亮 1
鲁肃-诸葛瑾 1
黄忠-刘备 1
黄忠-徐庶 1
黄忠-诸葛瑾 1
黄忠-赵子龙 1