
Spark Core——RDD何以替代Hadoop MapReduce?
导读
继续前期依次推文PySpark入门和SQL DataFrame简介的基础上,今日对Spark中最重要的一个概念——RDD进行介绍。虽然在Spark中,基于RDD的其他4大组件更为常用,但作为Spark core中的核心数据抽象,RDD是必须深刻理解的基础概念。

RDD(Resilient Distributed Dataset),弹性分布式数据集,是Spark core中的核心数据抽象,其他4大组件都或多或少依赖于RDD。简单理解,RDD就是一种特殊的数据结构,是为了适应大数据分布式计算的特殊场景(此时传统的数据集合无法满足分布式、容错性等需求)而设计的一种数据形式,其三个核心关键词是:
弹性:主要包含4层含义:即数据大小可变、分区数可变、计算可容错、内存硬盘存储位置可变
分布式:大数据一般都是分布式的,意味着多硬件依赖、多核心并行计算
数据集:说明这是一组数据的集合,或者说数据结构
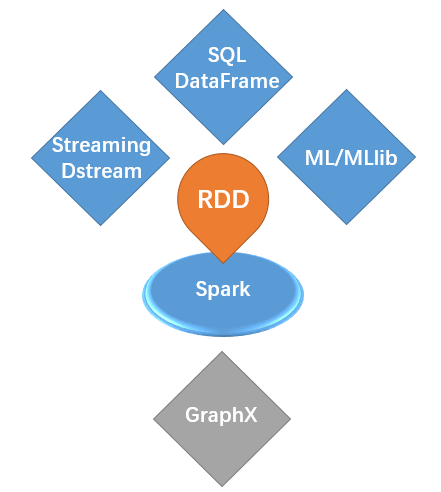
RDD在Spark中占据"core"的地位
看一个人,可以看看他的对手;了解一个产品,也可以看看他的竞品。Spark是为了解决Hadoop中 MapReduce计算框架效率低下而产生的大数据计算引擎,所以Spark起初的竞争对手就是MapReduce。
MapReduce之所以计算效率低,主要原因在于每次计算都涉及从硬盘的数据读写问题,而Spark设计之初就考虑尽可能避免硬盘读写,所以Spark的第一大特点是数据优先存储于内存中(除非内存存储不够才放到硬盘中)。同时,为了尽可能优化RDD在内存中的计算流程,Spark还引入了lazy特性。lazy特性其实质就是直至"真正碰上事了"才计算,否则就一直"推托下去",颇有不见兔子不撒鹰的味道。
这实际上又涉及到了RDD的两类算子:transformation和action,前者只是建立逻辑转换流程,后者才真正落地执行。transformation的结果是从一个RDD转换到另一个RDD,而action则是从一个RDD转换到一个非RDD,因此从执行结果是否仍然是RDD也可推断出该操作是transformation抑或action。进一步地,在transformation过程中,Spark内部调度RDD的计算过程是一个有向无环图(Directed Acyclic Graph,DAG ),意味着所有RDD的转换都带有方向性(一个产生另一个,即血缘关系),且不存在循环依赖的,这对Spark的容错性带来了有效保证:当一个环节出现问题时仅需按照方向关系追溯到相应的父RDD即可,而无需从头开始全流程计算。
Spark中关于宽窄依赖的经典图例(图片选自网络)
上图给出了宽窄依赖的一个图例。实际上,这里的宽窄依赖是针对RDD的每个partition而言的,分析子RDD的每个partition来源就容易理解其依赖为宽或窄:
窄依赖:子RDD和父RDD中的各partition是一一对应关系,由于仅单个依赖,所以是窄的,也无需等待其他父RDD中的partition
宽依赖:子RDD和父RDD中partition存在一对多的关系,也就是说生成子RDD中的某个partition不仅需要这个父RDD中的一个partition,还需要其他partition或其他父RDD的partition,由于依赖多个partition,所以是宽的,在实际执行过程中要等到所有partition就位后方可执行
也正因如此,对于整个DAG而言,依据依赖类型可将Spark执行过程划分为多个阶段,同一阶段内部Spark还会进行相应的调度和优化。可以说,内存计算+DAG两大特性共同保证了Spark执行的高效性。
RDD的创建主要有3类形式:
从Python中的其他数据结构创建,用到的方法为parallelize(),接收一个本地Python集合对象,返回一个RDD对象,一般适用于较小的数据集
从本地或HDFS文件中创建RDD对象,适用于大数据集,也是生产部署中较为常用的方式
从一个已有RDD中生成另一个RDD,所有transformation类算子其实都是执行这一过程
from pyspark import SparkContext # SparkContext是spark core的入口
sc = SparkContext() # sc是一个单例
rdd1 = sc.parallelize(['Tom', 'John', 'Joy']) # 从本地已有Python集合创建
rdd2 = sc.textFile('test.txt') # 从本地文件序列化一个RDD
rdd3 = rdd1.map(lambda x:(x, 1)) # 从一个RDD转换为另一个RDD
需要指出的是,RDD作为分布式的数据集合,其本身是不可变对象(immutable),所以所有的transformation算子都是从一个RDD转换生成了一个新的RDD,这也印证了DAG中无环的概念。
至于说转换过程中仍然可以使用相同的变量名,这是由Python的特性所决定的,类似于字符串是不可变数据类型,但也可以由一个字符串生成另一个同名字符串一样。
Spark中的算子,其实就是一类操作,或者更具体说是一个函数!
前面提到,Spark在执行过程中,依据从一个RDD是生成另一个RDD还是其他数据类型,可将操作分为两类:transformation和action。这实际上也是最为常用的RDD操作,甚至说Spark core编程模式就是先经历一系列的transformation,然后在action提取相应的结果。
然而,在系列transformation过程中,由于其lazy特性,当且仅当遇到action操作时才真正从头至尾的完整执行,所以就不得不面对一个问题:假如有RDD6是由前面系列的RDD1-5转换生成,而RDD6既是RDD7的父RDD,也是RDD8的父RDD,所以在独立执行RDD7和RDD8时,实际上会将RDD1=>RDD6的转换操作执行两遍,存在资源和效率上的浪费。当存在2遍计算重复或许尚可接受,但若存在更多重复转换时,这种模式或许不是一个明智之举,为此Spark还为RDD设计了第三类算子:持久化操作persistence。
至此,RDD的三类常用算子介绍如下:
1. transformation算子
map,接收一个函数作为参数,实现将RDD中的每个元素一对一映射生成另一个RDD,其实与Python中的原生map函数功能类似
filter,接收一个函数作为参数,实现将RDD中每个元素判断条件是否满足,进行执行过滤,与Python中的原生filter函数类似
flatMap,实际上包含了两个步骤,首先执行map功能,将RDD中的每个元素执行一个映射转换,当转换结果是多个元素时(例如转换为列表),再将其各个元素展平,实现一对多映射
groupByKey,适用于RDD中每个元素是一个包含两个元素的元组格式,例如(key, value)形式,进而将相同key对应的value构成一个特殊的集合对象,实质与SQL或者pandas中groupby操作类似,一般还需与其他聚合函数配合操作
reduceByKey,实际上groupByKey只执行了一半的聚合动作,即只有"聚"的过程,而缺少实质性的"合"的操作。reduceByKey则是在groupby之后加入了reduce的函数,实现真正聚合。换句话说,reduceByKey = groupByKey + aggFunction
sortByKey,也比较简单,即根据key值进行排序的过程
另外,针对以上函数还有一些功能相近的函数,不再列出。
2. action算子
action算子Spark中真正执行的操作,当一个算子的执行结果不再是RDD时,那么它就是一个action算子,此时Spark意识到不能再简单的进行逻辑运算标记,而需要实质性的执行计算。常用的action算子包括如下:
collect,可能是日常功能调试中最为常用的算子,用于将RDD实际执行并返回所有元素的列表格式,在功能调试或者数据集较小时较为常用,若是面对大数据集或者线上部署时切忌使用,因为有可能造成内存溢出
take,接收整数n,返回特定记录条数
first,返回第一条记录,相当于take(1)
count,返回RDD记录条数
reduce,对RDD的所有元素执行聚合操作,与Python中的原生reduce功能类似,返回一个标量
foreach,对RDD中每个元素执行特定的操作,功能上类似map,但会实际执行并返回结果
3. persistence算子
持久化的目的是为了短期内将某一RDD存储于内存或硬盘中,使其可复用。主要操作有两类:
persist,接收参数可以指定持久化级别,例如MEMORY_ONLY和MEMORY_AND_DISK,其中前者表示仅存储于内存中;后者表示优先放于内存,内存不足再放硬盘中
cache,缓存,即仅将RDD存于内存中,相当于持久化级别为MEMORY_ONLY的persist操作
另外,还有checkpoint也属于持久化操作。对于一个已经持久化的对象,当无需继续使用时,可使用unpersist完成取消持久化。
需知,持久化操作是为了便于多次重复调用同一RDD时,防止发生重复计算而设计的操作,但其本身仍然是偏lazy的模式,即执行了persist或者cache操作后,仅仅是将其标记为需要持久化,而直至第一次遇到action触发其执行时才会真正的完成持久化。
最后,举一个Spark中hello world级别的WordCount例子,实战一下各类算子的应用:
texts = ['this is spark', 'this is RDD']
rdd = sc.parallelize(texts) # 从已有集合创建RDD对象
# rdd = ['this is spark', 'this is RDD']
rdd1 = rdd.flatMap(lambda x:x.split(' ')) # flatMap将原来的句子用空格分割,并展平至单个词
# rdd1 = ['this', 'is', 'spark', 'this', 'is', 'RDD']
rdd2 = rdd1.map(lambda x:(x, 1)) # 将每个单词映射为(单词,1)的(key value)对象格式
# rdd2 = [('this', 1), ('is', 1), ('spark', 1), ('this', 1), ('is', 1), ('RDD', 1)]
rdd3 = rdd2.reduceByKey(lambda a, b:a+b) # 依据单词相同进行聚合
# rdd3 = [('spark', 1), ('RDD', 1), ('this', 2), ('is', 2)]
rdd3.collect() # 遇到action算子,将上述rdd=>rdd1=>rdd2=>rdd3有向无环图真正执行,并返回列表
相关阅读: