
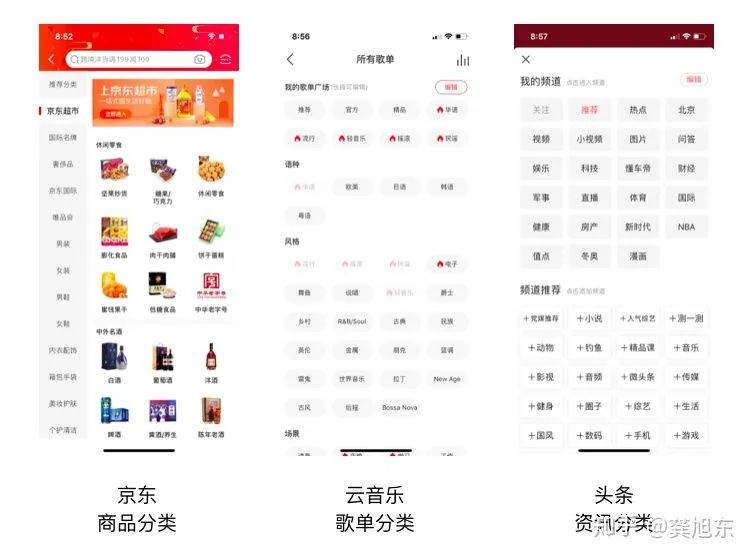
推荐系统之标签体系
为什么要先介绍标签体系?
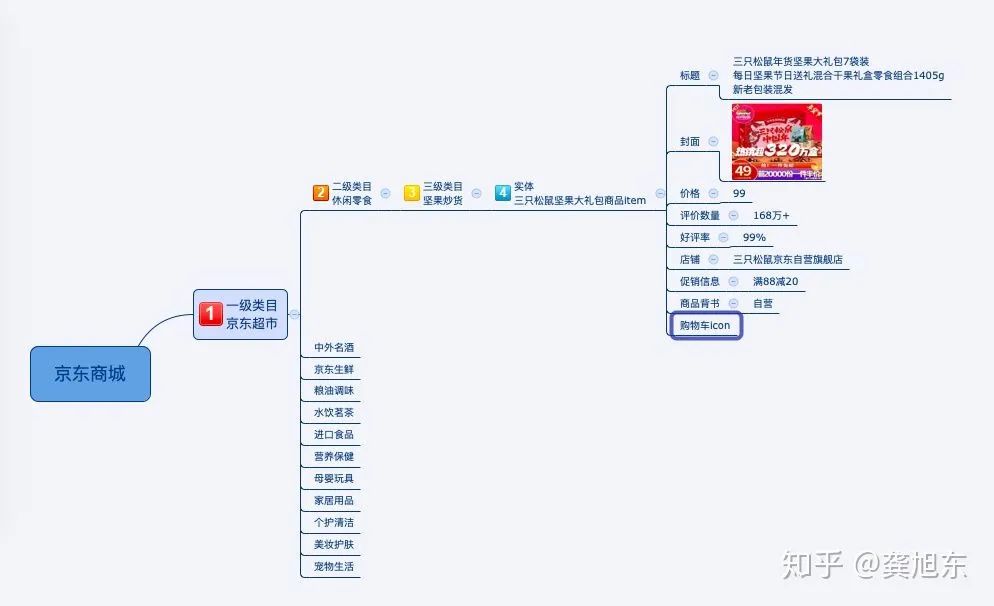
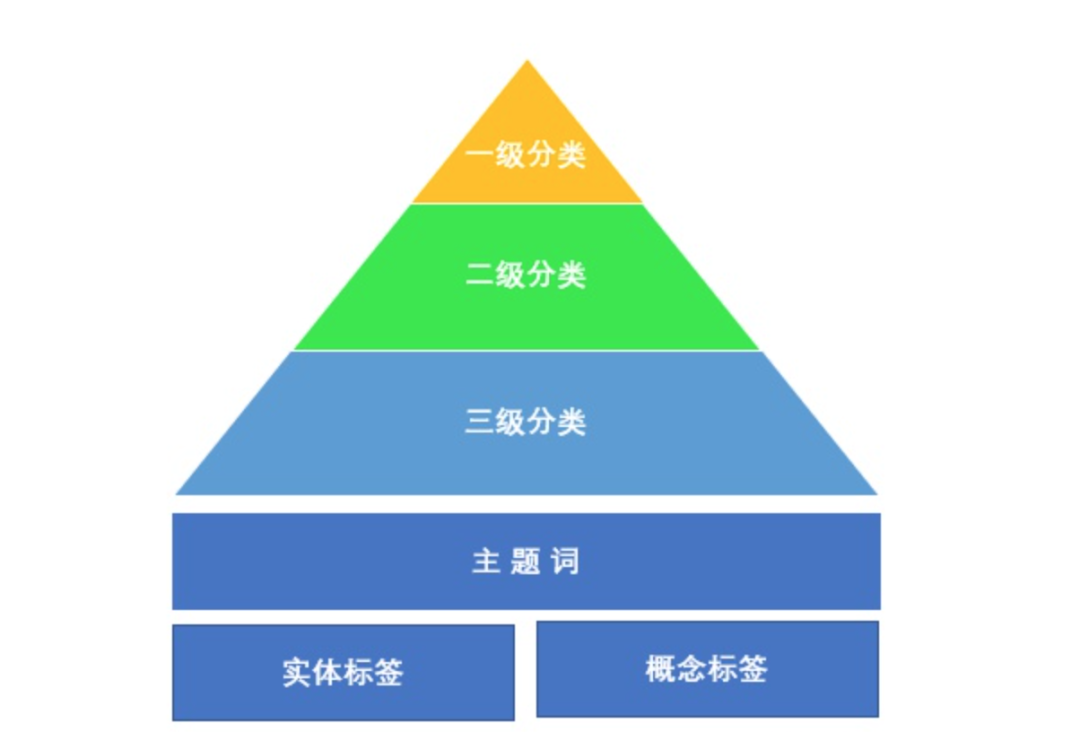
老板问:苹果,是实体标签吗? 给你三秒钟思考 你回答:是! 老板说:错! 你懵逼:靠!为啥不是?

难道我就不能用“苹果”了吗?当然可以用,只不过要给它另外起个名字:概念标签。

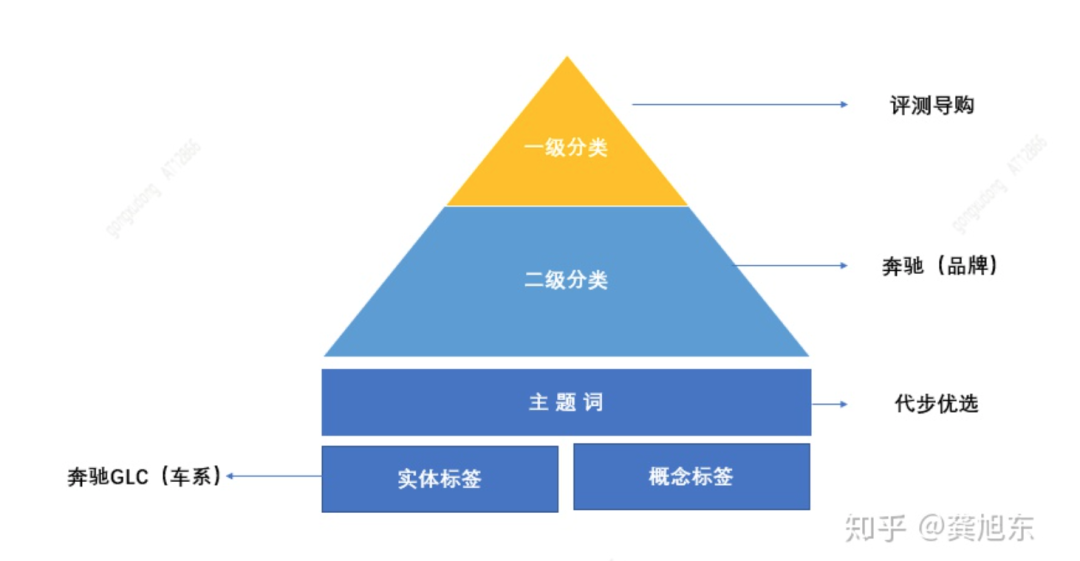
这里以之家的标签体系举例,要给买车用户推荐评测导购(一级)的文章,用户画像中车的品牌(二级)偏好太粗,而实体标签如奔驰GLC又太细,填补这中间的粒度空白,满足用户购车意图的画像,就加入“代步优选”的主题词,这样不仅保持了推荐的多样性,又不至于过分精准而导致的极度收敛。
原则一、放弃⼤而全的框架,以业务场景倒推标签需求
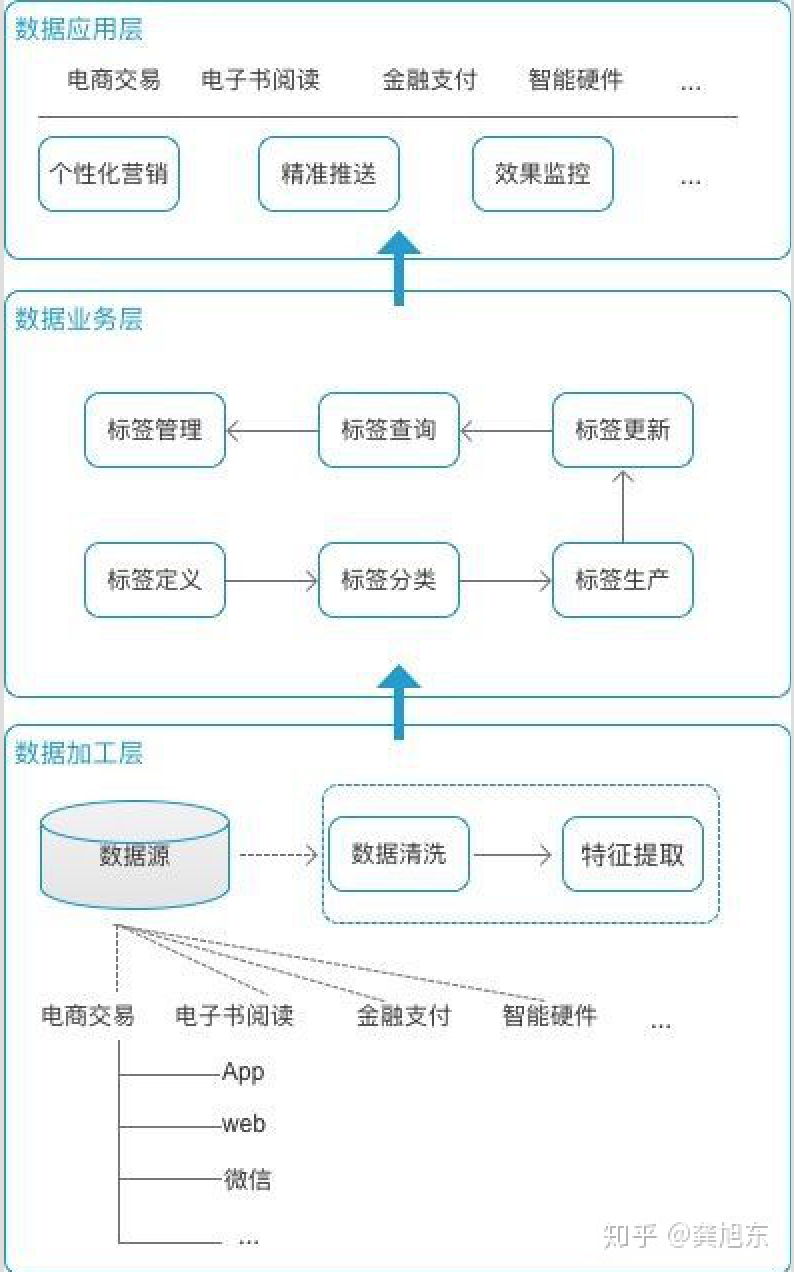
定义业务方需要的标签 创建标签实例 执行业务标签实例,提供相应数据
智能营销 Feed流推荐 个性化消息push
1. 业务梳理
有哪些产品线?产品线有哪些来源渠道?一一列出 每个产品线有哪些业务对象?比如用户,商品 最后再根据对象聚合业务,每个对象涉及哪些业务?每个业务下哪些业务数据和用户行为?

方便管理标签,便于维护和扩展 结构清晰,展示标签之间的关联关系 为标签建模提供子集。方便独立计算某个标签下的属性偏好或者权重
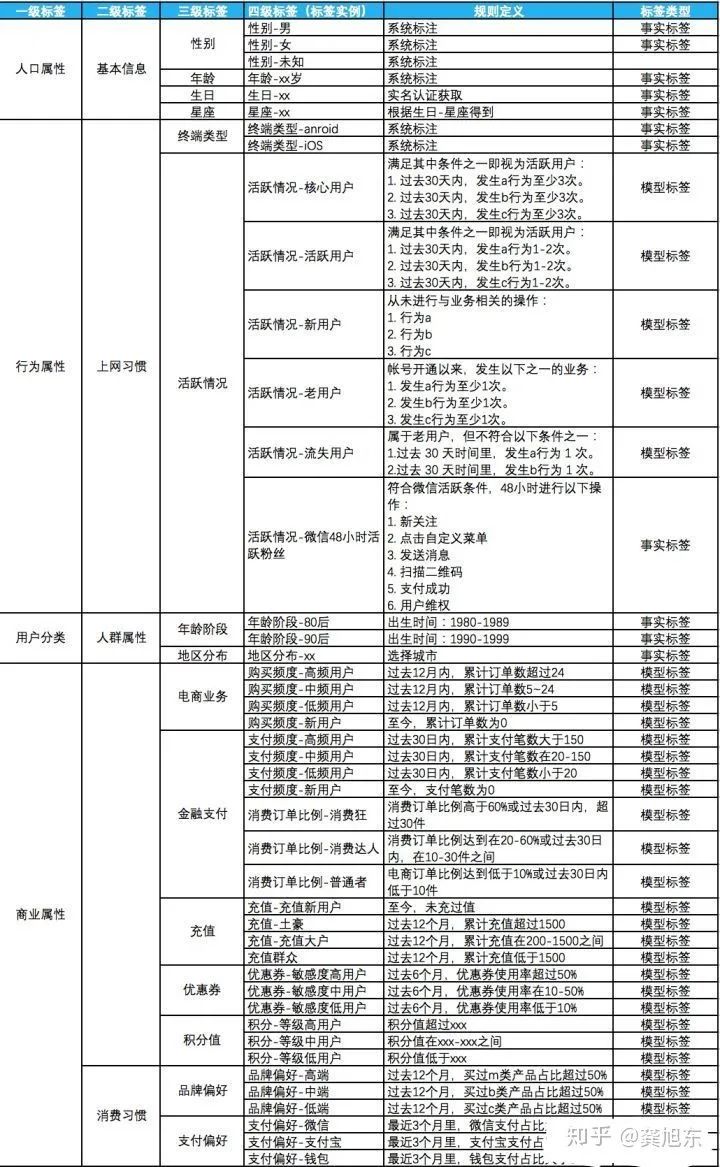
静态属性标签。长期甚至永远都不会发生改变。比如性别,出生日期,这些数据都是既定的事实,几乎不会改变 动态属性标签。存在有效期,需要定期地更新,保证标签的有效性。比如用户的购买力,用户的活跃情况
事实标签。既定事实,从原始数据中提取。比如通过用户设置获取性别,通过实名认证获取生日,星座等信息 模型标签。没有对应数据,需要定义规则,建立模型来计算得出标签实例。比如支付偏好度 预测标签。参考已有事实数据,来预测用户的行为或偏好。比如用户a的历史购物行为与群体A相似,使用协同过滤算法,预测用户a也会喜欢某件物品
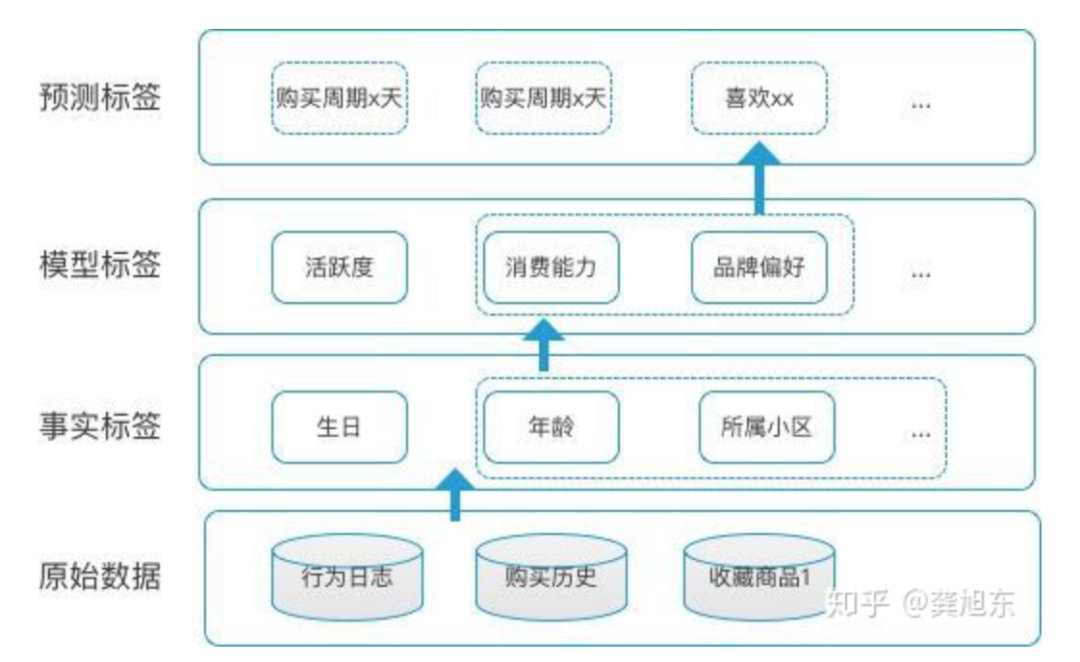
理解标签体系的设计 表达自己的需求
设计合理数据处理单元,相互独立,协同处理 标签的及时更新及数据响应的效率
属性信息缺失怎么办?比如,现实中总有用户未设置用户性别,那怎么才能知道用户的性别呢? 行为属性,消费属性的标签能不能灵活设置?比如,活跃运营中需要做A/B test,不能将品牌偏好规则写死,怎么办? 既有的属性创建不了我想要的标签?比如,用户消费能力需要综合结合多项业务的数据才合理,如何解决?
时间的开放。支持时间任意选择:昨天,前天,近x天,自定义某段时间等等 支付笔数的开放。大于,等于,小于某个值,或者在某两个值区间
标签的最小颗粒度要触达到具体业务事实数据,同时支持对应标签实例的规则自定义 不同的标签可以相互自由组合为新的标签,同时支持标签间的关系,权重自定义

评论