
有向无环图(DAG)的温故知新
当我们学习数据结构的时候,总是觉得很枯燥,而当我们解决实际问题的时候,又往往因为对数据结构了解的匮乏而束手无策。从问题中来,到问题中去,在某一点上的深入思考并且不断的实践积累,或许是个笨办法,但笨办法总是比没办法好一些。本文是老码农对DAG的随手笔记,积累成文。
什么是DAG?
DAG,Directed Acyclic Graph即「有向无环图」。

从计算机的视角来看,DAG 是一个图,图与数组、队列、链表等一样,都是是一种数据结构。图是由顶点和连接顶点的边构成的数据结构,在计算机科学中,图是最灵活的数据结构之一,很多问题都可以使用图模型进行建模求解。例如,人与人之间的社交网络、分析计算机网络的拓扑结构已确定两台计算机是否可以通信、物流系统中找到两个地点之间的最短路径等等。
回顾一下图的相关概念:
顶点:图中的一个点
边:连接两个顶点的线段
相邻:一个边的两头顶点成为相邻
度数:由一个顶点出发,有几条边就称该顶点有几度
路径:通过边来连接,按顺序的从一个顶点到另一个顶点中间经过的顶点集合
简单路径:没有重复顶点的路径
环:至少含有一条边,并且起点和终点都是同一个顶点的路径
简单环:不含有重复顶点和边的环
无环图:是一种不包含环的图
连通图:如果一个图中,从任意顶点均存在一条路径可以到达另一个任意顶点,该图称为连通图
稀疏图:图中每个顶点的度数都不较小
稠密图:图中每个顶点的度数都较大
如果图中的边可以是有方向的,边的方向性表明了两个顶点直接的不同不关系。例如,地图应用中必须存储单行道的信息,避免给出错误的方向。如果图中任意两个顶点之间的边都是有向边,这个图就是有向图。如果有一个非有向无环图,且A点出发向B经C可回到A,形成一个环。将从C到A的边方向改为从A到C,则变成有向无环图,即DAG。
按照数学上的定义,DAG是一个没有有向循环的、有限的有向图。具体来说,它由有限个顶点和有向边组成,每条有向边都从一个顶点指向另一个顶点;从任意一个顶点出发都不能通过这些有向边回到原来的顶点。也就是说,它由 顶点 Vertex 和 边 Edge (也称为弧)组成,每条边都从一个顶点指向另一个顶点,沿着这些顶点的方向 不会形成一个闭合的环 。DAG与代数拓扑学中的偏序集(Partially Ordered Set,Poset)有紧密联系。偏序关系相同的任意两个图会有相同的拓扑排序集。事实上,任何一个DAG都唯一对应一个Poset, 而所有的Poset都是DAG,所以它们在本质上是一种事物。
DAG具有一些很好性质,比如很多动态规划的问题都可以转化成DAG中的最长路径、最短路径或者路径计数的问题。
DAG的特性
DAG 具有空间结构和时间序列的混合特性,与数据结构中的树密切相关,其拓扑排序和最短路径的计算,都有着独到的特点。
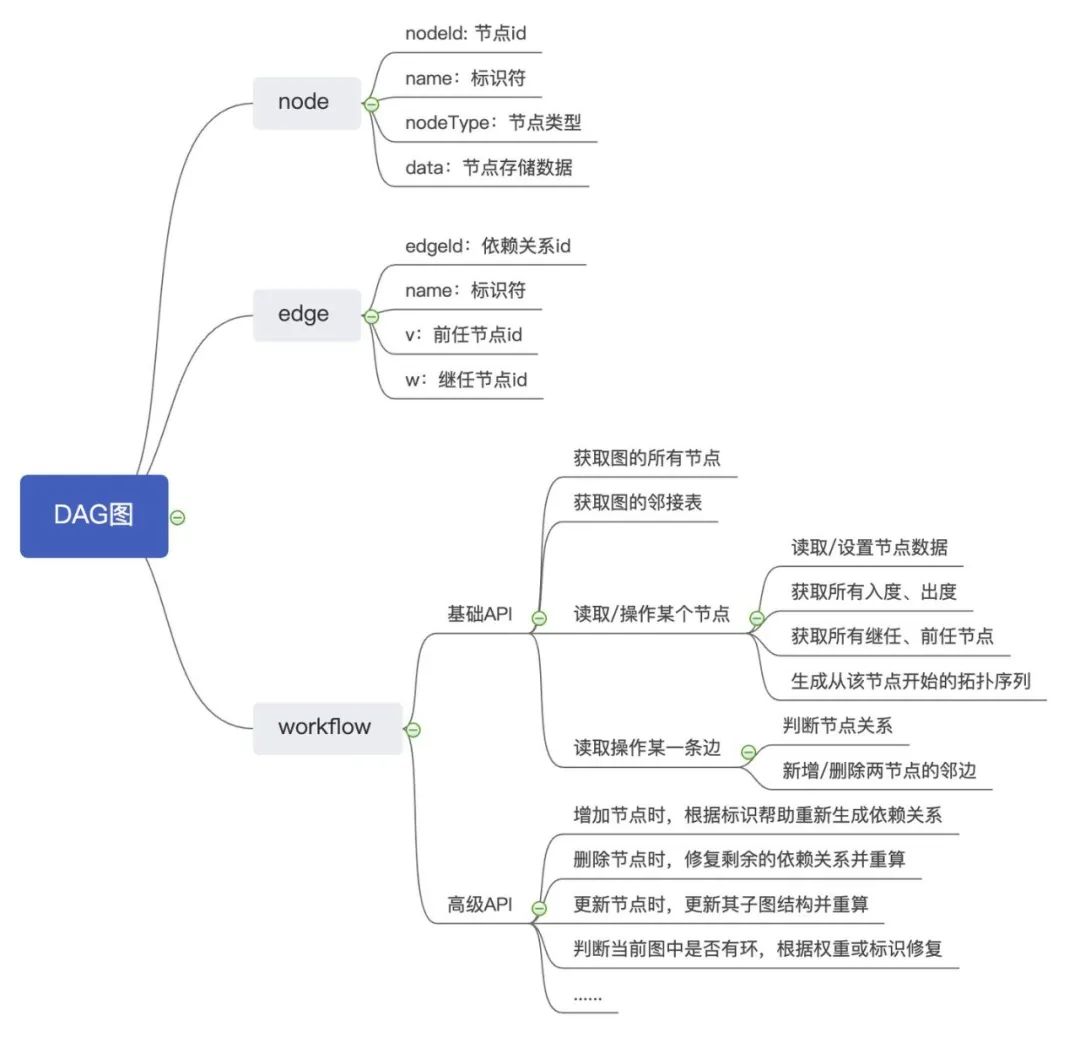
DAG 与树的关系
DAG是树的泛化,也是ploy tree的泛化。tree 是层次化,按照类别或者特性可以细分到原子单元,树其实就是一种无环连通图。DAG 从源开始细分,但是中间可以有合,有汇总。D就是可以合的点。
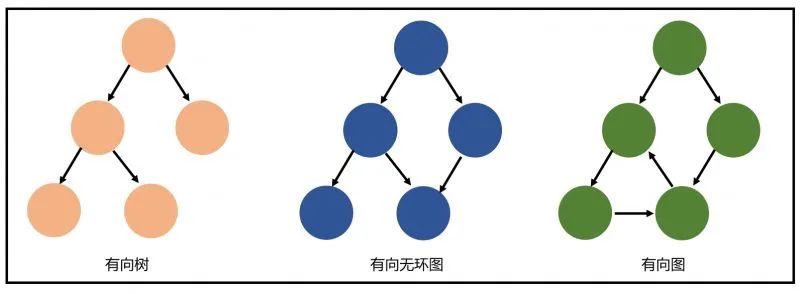
因为有向图中一个点经过两种路线到达另一个点未必形成环,因此有向无环图未必能转化成树,但任何有向树均为有向无环图。
DAG 的拓扑排序
拓扑排序是一个可以把所有的顶点排序的算法,它排序的依据是深度优先搜索算法的完成时间。可以根据拓扑排序来计算有向无环图(的单源最短路径),因为拓扑排序正好是建立在无环的基础上,在这个图中没有负权重边以及回路边。
拓扑排序是将图中所有顶点排成一个线性序列,使得图中任意一对顶点u和v,若边(u,v)∈E(G),则u在线性序列中出现在v之前。通常,这样的线性序列称为满足拓扑次序的序列,简称拓扑序列。简单的说,由某个集合上的一个偏序得到该集合上的一个全序,这个操作称之为拓扑排序。
对于一个DAG,可以这样确定一个图中顶点的顺序:对于所有的u、v,若存在有向路径u-->v,则在最后的顶点排序中u就位于v之前。这样确定的顺序就是一个DAG的拓扑排序。拓扑排序的特点如下:(1)所有可以到达顶点v的顶点u都位于顶点v之前;(2)所有从顶点v可以到达的顶点u都位于顶点v之后。
另外,只有有向无环图才存在拓扑排序,一个图的拓扑顺序不唯一。
实现拓扑排序主要有两种方法:入度表和DFS。在DFS实现拓扑排序时,用栈来保存拓扑排序的顶点序列;并且保证在某顶点入栈前,其所有邻接点已入栈。下面列出的是用C语言实现的入度表拓扑排序示例代码:
#define MAX_NODE 1000
#define MAX_EDGE_NUM 100000
struct Edge{
int to;
int w;
int next;
};
Edge gEdges[MAX_EDGE_NUM];
int gHead[MAX_NODE];
bool gVisited[MAX_NODE];
int gInDegree[MAX_NODE];
int gEdgeCount;
void InsertEdge(int u,int v,int w){
int e = gEdgeCount++;
gEdges[e].to = v;
gEdges[e].w = w;
gEdges[e].next = gHead[u];
gHead[u] = e;
gInDegree[v] ++; //入度加1
}
void TopoSort(int n/*节点数目*/){
queue<int> zero_indegree_queue;
for (int i = 0; i < n; i++){
if (gInDegree[i] == 0)
zero_indegree_queue.push(i);
}
memset(gVisited,false,sizeof(gVisited));
while (!zero_indegree_queue.empty()){
int u = zero_indegree_queue.front();
zero_indegree_queue.pop();
gVisited[u] =true;
//输出u
for (int e = gHead[u]; e != -1; e = gEdges[e].next){
int v = gEdges[e].to;
gInDegree[v] --;
if (gInDegree[v] == 0){
zero_indegree_queue.push(v);
}
}
}
for (int i = 0; i < n; i++){
if (!gVisited[i]){
//环!无法形成拓扑序
}
}
}DAG 的单源最短路径
图中节点的单源最短路径可以使用Dijkstra,BellmanFord, SPFA算法,而对于有向无环图DAG来说,可以通过简单的动态规划来进行求解。DAG的独特之处是所有节点可以线性化(拓扑序列),使得所有边保持从左到右的方向。

给定一个DAG和一个源点,可以得到该源点到其他所有的顶点的最短路径。如果是无负权,可以用djistra算法完成。但如果存在负权,则不行。同时,djistra算法效率并不高,既然是DAG,则可以利用拓扑排序的结果求出给定源点的最短路径,其时间复杂度是线性时间复杂度O(V+E)。
DAG 的单源最短路径算法原理如下:
1) 初始化dist[] = {INF, INF, ….} ,dist[s] = 0 是单源顶点
2)创建所有定点的拓扑排序
3) 对拓扑排序中的每个顶点u 做如下处理,即处理u 的每个相邻顶点:if (dist[v] > dist[u] + weight(u, v)) dist[v] = dist[u] + weight(u, v)
具体地, 用Python 实现的DAG最短路径算法代码示例如下:
# Python program to find single source shortest paths
# for Directed Acyclic Graphs Complexity :OV(V+E)
from collections import defaultdict
# Graph is represented using adjacency list. Every
# node of adjacency list contains vertex number of
# the vertex to which edge connects. It also contains
# weight of the edge
class Graph:
def __init__(self,vertices):
self.V = vertices # No. of vertices
# dictionary containing adjacency List
self.graph = defaultdict(list)
# function to add an edge to graph
def addEdge(self,u,v,w):
self.graph[u].append((v,w))
# A recursive function used by shortestPath
def topologicalSortUtil(self,v,visited,stack):
# Mark the current node as visited.
visited[v] = True
# Recur for all the vertices adjacent to this vertex
if v in self.graph.keys():
for node,weight in self.graph[v]:
if visited[node] == False:
self.topologicalSortUtil(node,visited,stack)
# Push current vertex to stack which stores topological sort
stack.append(v)
''' The function to find shortest paths from given vertex.
It uses recursive topologicalSortUtil() to get topological
sorting of given graph.'''
def shortestPath(self, s):
# Mark all the vertices as not visited
visited = [False]*self.V
stack =[]
# Call the recursive helper function to store Topological
# Sort starting from source vertice
for i in range(self.V):
if visited[i] == False:
self.topologicalSortUtil(s,visited,stack)
# Initialize distances to all vertices as infinite and
# distance to source as 0
dist = [float("Inf")] * (self.V)
dist[s] = 0
# Process vertices in topological order
while stack:
# Get the next vertex from topological order
i = stack.pop()
# Update distances of all adjacent vertices
for node,weight in self.graph[i]:
if dist[node] > dist[i] + weight:
dist[node] = dist[i] + weight
# Print the calculated shortest distances
for i in range(self.V):
print ("%d" %dist[i]) if dist[i] != float("Inf") else "Inf" ,
g = Graph(6)
g.addEdge(0, 1, 5)
g.addEdge(0, 2, 3)
g.addEdge(1, 3, 6)
g.addEdge(1, 2, 2)
g.addEdge(2, 4, 4)
g.addEdge(2, 5, 2)
g.addEdge(2, 3, 7)
g.addEdge(3, 4, -1)
g.addEdge(4, 5, -2)
# source = 1
s = 1
print ("Following are shortest distances from source %d " % s)
g.shortestPath(s)
# This code is contributed by Neelam Yadav
DAG的应用
鉴于DAG的一般性,具有广泛的应用场景。
DAG 的存储结构用例
作为数据结构,DAG 在数据存储方面非常著名的使用场景就是Git。Git采用了Merkle Tree+ DAG作为一个组合的数据结构Merkle DAG,来实现了分布式的的版本控制。
IPFS 参考了Git的实现思想,同样使用了Merkle DAG 作为核心的数据结构,即后来称为IPLD, 在 IPFS 生态系统的“蜂腰”模型中处于腰的位置,如下图所示:
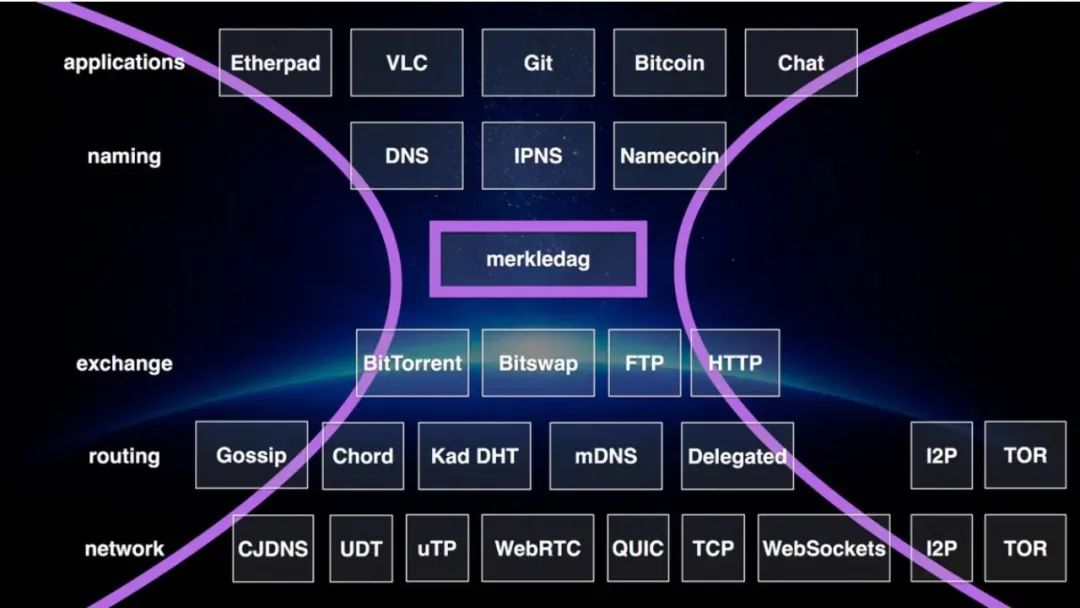
Merkle Tree通常也被称作Hash Tree,顾名思义,就是存储hash值的一棵树。在Merkle Tree 的基础上,Merkle DAG是一个有向无环图,可以简单的理解成一棵树,且没有Merkle Tree那样严格的限制(例如平衡树),其特点是:
父节点的哈希值由子节点的哈希值决定,即父节点的哈希值是由子节点的哈希值拼接得来的字符串哈希而成。
父节点中包含指向子节点的信息。
Merkle DAG保留了Merkle Tree的精华部分,即任何一个下层节点改动,都将导致上层节点的哈希值变动,最终的根节点的哈希值也变动。在IPFS网络中,存储文件时,首先会将文件切片,切割成256KB大小的文件。之后循环调用(MerkleDAG.Add)方法构建文件MerkleDAG。文件hash值创建流程如下:
将切片之后的文件进行sha-256运算
将运算结果选取0~31位
将选取结果根据base58编码,运算结果前追加Qm 即为最后结果作为文件的46位hash值。
在IPFS中,使用DAGService维护MerkleDAG,为MerkleDAG提供删除和增加的权限。其中的Merkle DAG为多叉树结构,最多为174叉树。
通过Merkle DAG, IPFS能够轻松确保和验证P2P格式的计算机之间共享数据的完整性,这使得它们对系统非常有用。
DAG 的因果关系用例
以探讨影响因素或者控制偏倚为目的回归模型,要求自变量和因变量往往存在着因果关系,所以自变量筛选首先需要考虑自变量能否纳入到模型,严格挑选自变量进入模型。
DAG可以说是回归分析的灵魂所在,是最高指导方针。基于DAG构建因果关系网络,从而找到合适进入模型的自变量。箭头发出对象为因,箭头指向为果。所有变量因果关系通过方向线形成的单向网络,即DAG。

例如,贝叶斯网络是表示多个概率事件的关联网络。顶点表示事件,后续事件的发生可能性则可以通过其在有向无环图的前驱节点的发生概率计算出来。
动态规划的DAG 实现
什么是动态规划呢?问题可以分解成若干相互联系的阶段,在每一个阶段都要做出决策,全部过程的决策是一个决策序列。要使整个活动的总体效果达到最优的问题,称为多阶段决策问题。动态规划就是解决多阶段决策最优化问题的一种思想方法。
将所给问题的过程,按时间或空间特征分解成若干相互联系的阶段,以便按次序去求每阶段的解。各阶段开始时的客观条件叫做状态。当各段的状态取定以后,就可以做出不同的决定,从而确定下一阶段的状态,这种决定称为决策。具体地,动态规划的递推需要一个线性或者树形的顺序,对于DAG,可以将节点按照拓扑顺序来进行线性化。具体地,对于当前的节点v,在拓扑序列中向前查找,可能找到一些可以到达该顶点的其他节点,然后利用 dist[v] = min{dist[u] + w[u][v] | u 可以到达v}来进行动态规划的递推。
基于DAG 调度用例
在有相互依赖的调度系统中,DAG 有着非常典型的应用。这里以Spark 为例进行说明。
在Spark中的每一个操作生成一个RDD,RDD之间形成一条边,最后这些RDD和他们之间的边组成一个有向无环图,这个就是DAG。
Spark中的RDD依赖关系分为两种:窄依赖(Narrow Dependencies)与宽依赖(Wide Dependencies,源码中称为Shuffle Dependencies)会根据宽依赖窄依赖来划分具体的Stage,而依赖有2个作用:
用来解决数据容错的高效性;
其二用来划分stage。
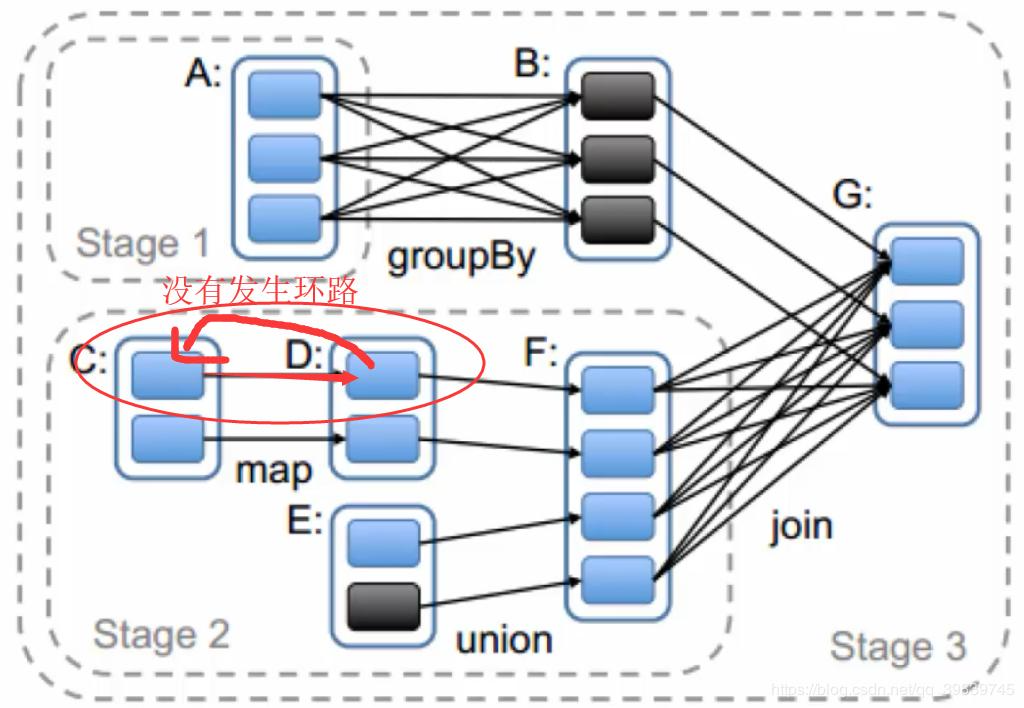
原始的RDD通过一系列的转换就形成了DAG,有了可计算的DAG,Spark内核下一步的任务就是根据DAG图将计算划分成任务集,也就是Stage,这样可以将任务提交到计算节点进行真正的计算。Spark计算的中间结果默认是保存在内存中的,Spark在划分Stage的时候会充分考虑在分布式计算中可流水线计算的部分来提高计算的效率,而在这个过程中Spark根据RDD之间依赖关系的不同将DAG划分成不同的Stage。对于窄依赖,partition的转换处理在一个Stage中完成计算。对于宽依赖,由于有Shuffle的存在,只能在parent RDD处理完成后,才能开始接下来的计算,因此宽依赖是划分Stage的依据。
Spark 执行时的处理流程如下:
1)用户代码定义RDD的有向无环图
RDD上的操作会创建新的RDD,并引用它们的父节点,这样就创建了一个图。
2)行动操作把有向无环图强制转译为执行计划
当调用RDD的一个行动操作时,这个RDD就必须被计算出来。这也要求计算出该RDD的父节点。Spark调度器提交一个作业来计算出所有必要的RDD。这个作业会包含一个或多个步骤,每个步骤其实也就是一波并行执行的计算任务。一个步骤对应有向五环图中的一个或多个RDD,一个步骤对应多个RDD是因为发生了流水线执行。
3)任务于集群中调度并执行
步骤是按顺序处理的,任务则独立的启动来计算出RDD的一部分。一旦作业的最后一个步骤结束,一个行动操作也就执行完了。
DAG 的区块链用例
最早在区块链中引入DAG概念作为共识算法是在2013年,bitcointalik.org由ID为avivz78的以色列希伯来大学学者提出,也就是GHOST协议,作为比特币的交易处理能力扩容解决方案;Vitalik在以太坊紫皮书描述的POS共识协议Casper,也是基于GHOST POW协议的POS变种。
后来,有人提出用DAG的拓扑结构来存储区块,解决区块链的效率问题。区块链只有一条单链,打包出块无法并发执行。如果改变区块的链式存储结构,变成DAG的网状拓扑就可以实现并发写入。在区块打包时间不变的情况下,网络中可以并行打包N个区块,网络中的交易效率就提升了N倍。
那个时候,DAG跟区块链的结合依旧停留在类似侧链的解决思路,交易打包可以并行在不同的分支链条进行,达到提升性能的目的。此时,DAG还是区块的概念。

2015年9月,Sergio Demian Lerner发表了 《DagCoin: a cryptocurrency without blocks》一文,提出了DAG-Chain的概念,首次把DAG网络从区块打包这样粗粒度提升到了基于交易层面。DagCoin的思路,让每一笔交易都直接参与维护全网的交易顺序。交易发起后,直接广播全网,这样省去了打包交易出块的时间。也就是说,交易发起后直接广播网络确认,理论上效率得到了质的飞跃。
进一步,DAG演变成了完全抛弃区块链的一种解决方案。2016年7月,基于IOTA横空出世,随后ByteBall也登场了,IOTA和Byteball是头一次DAG网络的真正技术实现,此时,号称无块之链、独树一帜的DAG链家族雏形基本形成。
从某种程度上说,DAG可能是面向未来的新一代区块链,从单链进化到树状和网状、从区块粒度细化到交易粒度、从单点跃迁到并发写入,这是区块链从容量到速度的一次革新。
一句话小结
有向无环图有许多科学的和计算的应用,从生物学到社会学再到我们所熟悉的计算机领域,而且,DAG的原理并不复杂,关键在于把目标问题抽象为DAG,进而使用DAG的相关特性来解决问题。
【参考资料与关联阅读】
https://www.lwlwq.com/post-dag.html
https://zhuanlan.zhihu.com/p/275992858
https://www.jianshu.com/p/84cdab3030cb
https://en.wikipedia.org/wiki/Directedacyclicgraph
https://www.cnblogs.com/gtarcoder/p/4900516.html
https://www.geeksforgeeks.org/shortest-path-for-directed-acyclic-graphs/