
清华南开发布attention 7年全回顾:注意力机制还有7大问题要研究!
2014年的RAM模型拉开了attention的序幕,距今发展已有7年,无数的研究成果涌现出来。最近清华大学、南开大学的研究人员共同写就一篇关于注意力机制的综述,将attention分为四类,还指出7大问题还悬而未决!
神经网络中注意力(attention)机制可谓是如日中天,在各类神经网络模型中都有它的身影,尤其是Transformer更是以self-attention为核心。
受到人类注意力的启发,将注意力机制引入计算机视觉模型后可以模拟人类视觉系统,能够将输入图像特征的权重进行动态调整。
注意力机制在图像分类、目标检测、语义分割、视频理解、图像生成、三维视觉、多模态任务和自监督学习等许多视觉任务中都取得了很大的成功。
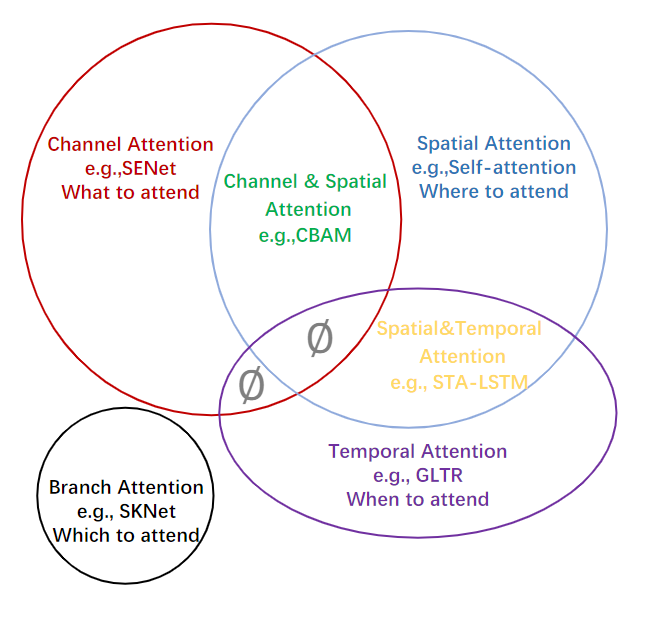
来自清华大学、南开大学、卡迪夫大学的研究人员共同写了一篇survey,对计算机视觉中的各种注意力机制进行了全面的回顾,并根据这些机制的方法进行分类,如通道注意力(channel attention)、空间注意力(spatial attention)、时序注意力(temporal attention)和分支注意力(branch attention)。论文中涉及到的代码已经开源。

文章的通讯作者胡事民是清华大学计算机系教授,可视媒体研究中心主任。2002年获得国家杰出青年基金资助,2006年-2015年担任国家重大基础研究(973)计划项目 首席科学家,2007年入选教育部长江学者特聘教授,现为国家自然科学基金委创新群体项目学术带头人。
主要从事计算机图形学、虚拟现实、智能信息处理和系统软件等方面的教学与研究工作。曾担任PG、SGP、CVM、VR、EG、SIGGRAPH ASIA等多个国际重要会议的程序委员会主席和委员,曾经和现任IEEE、Elsevier、Springer等多个期刊的主编、副主编和编委。

将模型的注意力转移到图像中最重要的区域,并且忽视无关部分的方法称为注意力机制。人类的视觉系统使用注意力来帮助高效、有效地分析和理解复杂场景,这反过来又激励了研究人员将注意力机制引入计算机视觉系统,以提高模型的性能。
在视觉系统中,注意力机制可以被视为一个动态的选择过程,根据输入图像的重要性,通过自适应加权来实现。
在过去的十年里,注意力机制在计算机视觉中发挥了越来越重要的作用。研究进展可大致分为四个阶段。
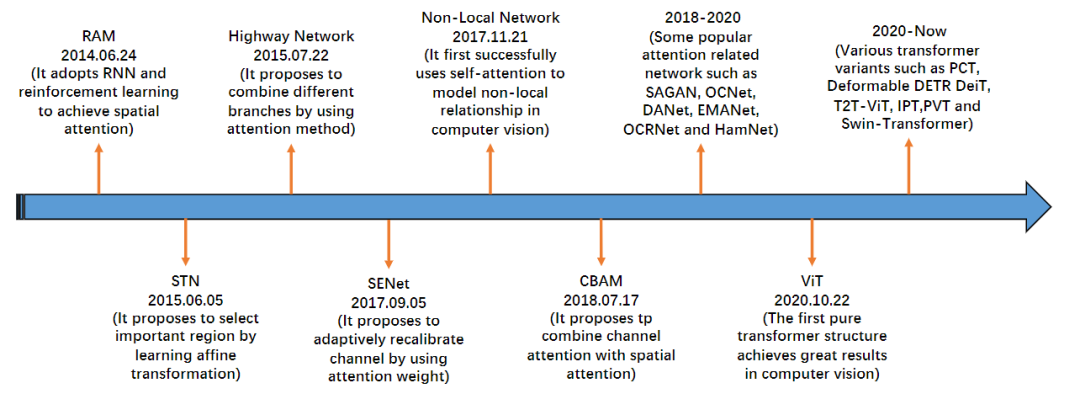
第一阶段从RAM开始,开创了将深度神经网络与注意力机制相结合的工作。它能够循环预测重要区域,并通过策略梯度以端到端的方式更新整个网络。后来,各种相关论文都采用了类似的策略在视觉中使用注意力。在这一阶段,递归神经网络(RNN)是注意力机制的必要工具。
在第二阶段,Jaderberg提出了STN,引入了一个子网来预测用于选择输入中重要区域的仿射转化,明确预测判别输入特性是第二阶段的主要特征;DCNS也是其中代表性的网络。
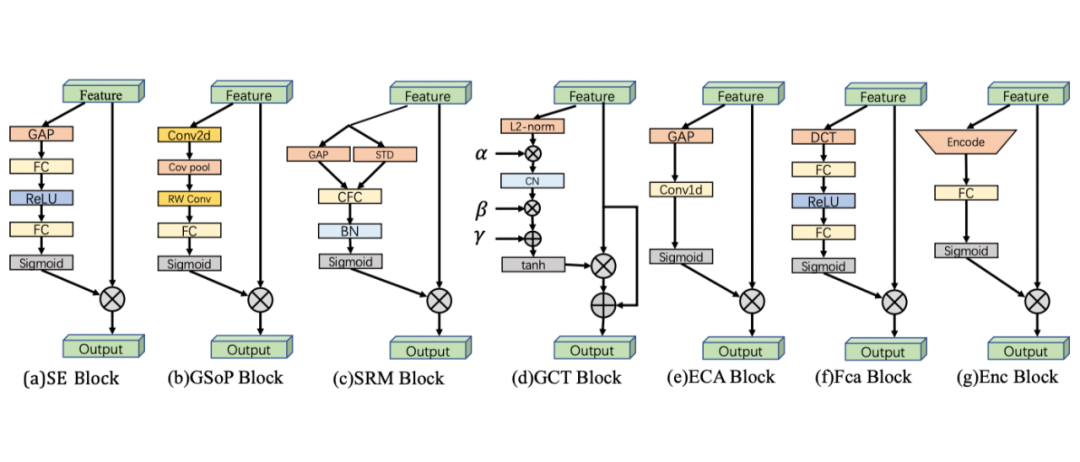
在第三阶段,SENet 提出了一种隐式自适应预测潜在关键特征的信道注意力网络。CBAM和ECANET是本阶段的代表性工作。
最后一个阶段是自注意力的时代。自我关注最早出现在Attention Is All You Need 那篇论文中,并迅速在自然语言处理领域取得了显著的性能提升,随后有研究人员将自注意力引入计算机视觉领域,并提出了一种在视频理解和目标检测方面取得巨大成功的新型non-local 网络。Emanet、CCNet、Hamnet和Stand-Alone网络这些工作提高了模型的速度、结果质量和通用性。
研究人员在文中还指出了未来注意力机制的六个可能研究方向:
1. 注意力的必要和充分条件
常见的注意力公式是必要条件,但并非充要条件。例如,GoogleNet符合这个公式,但并不属于注意力机制。但目前研究领域还没人关注注意力机制的充要条件,所以这个研究方向还有待探索,也能够帮助我们对注意力机制的理解。
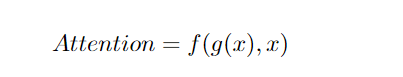
2. 通用的注意力块(general attention block)
目前的研究工作都需要为每项不同的任务设计一个特别的注意力机制,这也要求研究人员在探索潜在的注意力方法方面需要耗费相当大的功夫。例如channel attention 是图像分类的一个很好的选择,而spatial attention则很适合于语义分割、目标检测等密集的预测任务。channel attention主要关注于重点是什么(what to pay attention to),而spatial attention的关注重点是哪里(where to pay attention)。
根据这一观察结果,是否可以有一个利用所有类型注意机制的一般性attention block?例如,软选择机制(branch attention)可以根据所执行的特定任务在channel attention、spatial attention和temporal attention之间进行选择。
3. 特性和可解释性(Characterisation and interpretability)
注意力机制是由人类视觉系统驱动的,是朝着建立一个可预测的计算机视觉系统的目标迈出的一步。通常通过绘制注意力图可以来理解基于注意力的模型,但这只能给人一种直观的感觉,而非准确的理解。
但在安全性相关或对安全性很重视的应用领域,如医疗诊断和自动驾驶系统,往往有更严格的要求。在这些领域需要更好地描述工作方法,包括故障模式。发展具有特征性(charaterisable)和可解释性的注意力模型可以使它们适用更广泛的应用领域。

4. 稀疏激活(sparse activation)
可视化一些注意力图(attention map)后可以得到一些和ViT 一致的结论,即注意力机制可能会产生稀疏激活。这种现象带来一个启示是,稀疏激活可以在深度神经网络中实现更强的性能。但值得注意的是,稀疏激活与人类认知相似,这也许能够激励我们探索哪种架构更可以模拟人类视觉系统。
5. 基于注意力的预训练模型
大规模的基于注意力的预训练模型在自然语言处理方面取得了巨大的成功。而最近如MoCoV3、DINO、BEiT和MAE已经证明基于注意力的模型也非常适合视觉任务。由于它们能够适应不同的输入,基于注意的模型可以处理不可见的物体,并且很自然地适合将预先训练的权重转移到各种任务中。所以应进一步探索预训练模型和注意力模型的结合:训练方法、模型结构、训练前任务和数据规模都值得研究。
6. 优化(Optimization)
SGD和Adam非常适合优化卷积神经网络。对于ViT,AdamW的运行效果更好。最近有研究人员通过使用一种新的优化器,即锐度感知最小化器(sharpness-aware minimizer, SAM),显著改进了ViT。显然,注意力网络和卷积神经网络是不同的模型;不同的优化方法对不同的模型可能效果更好。注意力模型的新优化方法可能是一个值得研究的领域。
7. 部署(Deployment)
卷积神经网络具有简单、统一的结构,易于部署在各种硬件设备上。然而,在边缘器件上部署复杂多样的基于注意力的模型是一个难题。但实验表明,基于注意力的模型比卷积神经网络提供了更好的结果,因此值得尝试找到简单、高效和有效的基于注意力的模型,使得这些模型可以广泛部署于各种设备上。
参考资料:
https://arxiv.org/abs/2111.07624
