
【Attention九层塔】注意力机制的九重理解
看山是山——Attention是一种注意力机制
看山看石——数学上看,Attention是一种广泛应用的加权平均
看山看峰——自然语言处理中,Attention is all you need
看山看水——BERT系列大规模无监督学习将Attention推到了新的高度
水转山回——计算机视觉中,Attention是有效的非局域信息融合技术
山高水深——计算机视觉中,Attention will be all you need
山水轮回——结构化数据中,Attention是辅助GNN的利器
山中有山——逻辑可解释性与Attention的关系
山水合一——Attention的多种变种及他们的内在关联
1. Attention是一种注意力机制
顾名思义,attention的本意是生物的注意力机制在人工智能中的应用。注意力机制有什么好处呢?简单地说,可以关注到完成目标场景中所需要的特征。比如说有一系列的特征  。可能目标场景仅仅需要
。可能目标场景仅仅需要  ,那么attention可以有效地“注意到”这两个特征,而忽略其他的特征。attention最早出现在了递归神经网络(RNN)中[1],作者Sukhbaatar举了这样的例子:
,那么attention可以有效地“注意到”这两个特征,而忽略其他的特征。attention最早出现在了递归神经网络(RNN)中[1],作者Sukhbaatar举了这样的例子:

上图中,如果我们需要结合(1)到(4)这四句话,根据问题Q回答出正确答案A。可以看到,Q与(3)没有直接的关联,但是我们需要从(3)中得到正确答案bedroom。一个比较自然地想法是,我们引导模型的注意力,从问题开始,从四句话中寻找线索,从而回答问题。

如上图所示,通过问题中的apple,我们转到了第四句话,然后注意力转移到第三句话,确定回答中的bedroom。
到这里,我们应该已经抓住了attention最早的理解,达到了第一层——看山是山。
现在我们的问题是,如何设计这样的模型,以达到这样的效果?
最早的实现是基于显式的存储器,把每一步的结果都存下来,“人工实现”注意力的转移。
还是上面的例子,

如上图所示,通过对存储器的处理,和对注意到的东西的更新,实现attention。这种方法比较简单,但是很hand-crafted,后来已经逐渐废弃了,我们需要升级我们的认知,达到比较抽象层次。
2. Attention是一种加权平均
Attention的经典定义,是来源于Attention is all you need这篇旷世奇作[2]。虽然前面一些工作也发现了类似的技术(如self-attention),但是这篇文章因为提出了“attention就是一切你想要的”这一大胆而逐渐被证实的论断,而享有了载入史册的至高荣耀。这一经典定义,就是下面的公式。

公式含义下面讲,先讲讲意义。这一公式,也基本上是近五年来,科研人员最早接触到的经典定义。这一公式在自然语言处理中的地位,即将接近牛顿定律在经典力学中的地位,已经成为了搭建复杂模型的基本公式。
这个公式看似复杂,但是理解了之后就会发现非常的简单和基本。先讲一下每个字母的含义。字面意思:Q表示query,表示的是K表示key,V表示value,  是K的维度。这时候就要有人问了,什么是query,什么是key,什么是value?因为这三个概念都是这篇文章引入的,所以说,这篇文章中的公式摆在Q的这个位置的东东就是query,摆在K这个位置的就叫key,摆在V这个位置的就是value。这就是最好的解读。换句话说,这个公式类似于牛顿定律,本身是可以起到定义式的作用的。
是K的维度。这时候就要有人问了,什么是query,什么是key,什么是value?因为这三个概念都是这篇文章引入的,所以说,这篇文章中的公式摆在Q的这个位置的东东就是query,摆在K这个位置的就叫key,摆在V这个位置的就是value。这就是最好的解读。换句话说,这个公式类似于牛顿定律,本身是可以起到定义式的作用的。
为了便于大家理解,我在这里举几个例子解释一下这三个概念。
1、 【搜索领域】在bilibili找视频,key就是bilibili数据库中的关键字序列(比如宅舞、鬼畜、马保国等),query就是你输入的关键字序列,比如马保国、鬼畜,value就是你找到的视频序列。
2、【推荐系统】在淘宝买东西,key就是淘宝数据库中所有的商品信息,query就是你最近关注到的商品信息,比如高跟鞋、紧身裤,value就是推送给你的商品信息。
上面两个例子比较的具体,我们往往在人工智能运用中,key,query,value都是隐变量特征。因此,他们的含义往往不那么显然,我们需要把握的是这种计算结构。
回到公式本身,这个公式本质上就是表示按照关系矩阵进行加权平均。关系矩阵就是  ,而softmax就是把关系矩阵归一化到概率分布,然后按照这个概率分布对V进行重新采样,最终得到新的attention的结果。
,而softmax就是把关系矩阵归一化到概率分布,然后按照这个概率分布对V进行重新采样,最终得到新的attention的结果。
下图展示了在NLP中的Attention的具体含义。我们现在考虑一个单词it的特征,那么它的特征将根据别的单词的特征加权得到,比如说可能the animal跟it的关系比较近(因为it指代the animal),所以它们的权值很高,这种权值将影响下一层it的特征。更多有趣的内容请参看 The Annotated Transformer[3]和illustrate self-attention[4]。

看到这里,大概能明白attention的基础模块,就达到了第二层,看山看石。
3. 自然语言处理中,Attention is all you need。
Attention is all you need这篇文章的重要性不只是提出了attention这一概念,更重要的是提出了Transformer这一完全基于attention的结构。完全基于attention意味着不用递归recurrent,也不用卷积convolution,而完全使用attention。下图是attention与recurrent,convolution的计算量对比。

可以看到,attention比recurrent相比,需要的序列操作变成了O(1),尽管每层的复杂性变大了。这是一个典型的计算机内牺牲空间换时间的想法,由于计算结构的改进(如加约束、共享权重)和硬件的提升,这点空间并不算什么。
convolution也是典型的不需要序列操作的模型,但是其问题在于它是依赖于2D的结构(所以天然适合图像),同时它的计算量仍然是正比于输入的边长的对数的,也就是Ologk(n)。但是attention的好处是最理想情况下可以把计算量降低到O(1)。也就是说,在这里我们其实已经能够看到,attention比convolution确实有更强的潜力。
Transformer的模型放在下面,基本就是attention模块的简单堆叠。由于已经有很多文章讲解其结构,本文在这里就不展开说明了。它在机器翻译等领域上,吊打了其他的模型,展示了其强大的潜力。明白了Transformer,就已经初步摸到了attention的强大,进入了看山看峰的境界。

4. 看山看水——BERT系列大规模无监督学习将Attention推到了新的高度。
BERT[5]的推出,将attention推到了一个全新的层次。BERT创造性地提出在大规模数据集上无监督预训练加目标数据集微调(fine-tune)的方式,采用统一的模型解决大量的不同问题。BERT的效果非常好,在11个自然语言处理的任务上,都取得了非凡的提升。GLUE上提升了7.7%,MultiNLI提升了4.6%,SQuAD v2.0提升了5.1%。
BERT的做法其实非常简单,本质就是大规模预训练。利用大规模数据学习得到其中的语义信息,再把这种语义信息运用到小规模数据集上。BERT的贡献主要是:1)提出了一种双向预训练的方式。(2)证明了可以用一种统一的模型来解决不同的任务,而不用为不同的任务设计不同的网络。(3)在11个自然语言处理任务上取得了提升。
(2)和(3)不需要过多解释。这里解释一下(1)。之前的OpenAI GPT传承了attention is all you need,采用的是单向的attention(下图右),也就是说输出内容只能attention到之前的内容,但是BERT(下图左)采用的是双向的attention。BERT这种简单的设计,使得他大幅度超过了GPT。这也是AI届一个典型的小设计导致大不同的例子。
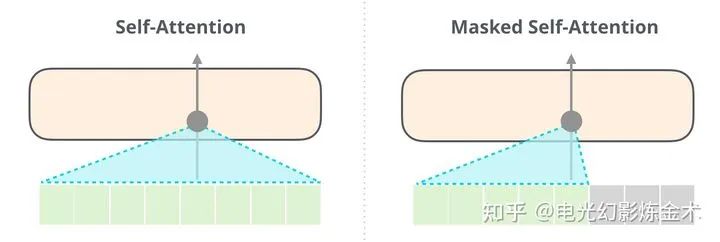
BERT提出了几个简单的无监督的预训练方式。第一个是Mask LM,就是挡住一句话的一部分,去预测另外一部分。第二个是Next Sentence Prediction (NSP) ,就是预测下一句话是什么。这种简单的预训练使得BERT抓住了一些基本的语义信息和逻辑关系,帮助BERT在下流任务取得了非凡的成就。
理解了BERT是如何一统NLP江湖的,就进入了看山看水的新境界。
5. 水转山回——计算机视觉中,Attention是有效的非局域信息融合技术。
Attention机制对于计算机视觉能不能起到帮助作用呢?回到我们最初的定义,attention本身是一个加权,加权也就意味着可以融合不同的信息。CNN本身有一个缺陷,每次操作只能关注到卷积核附近的信息(local information),不能融合远处的信息(non-local information)。而attention可以把远处的信息也帮忙加权融合进来,起一个辅助作用。基于这个idea的网络,叫做non-local neural networks[6] 。

这篇提出的non-local操作和attention非常像,假设有  和
和  两个点的图像特征,可以计算得到新的特征
两个点的图像特征,可以计算得到新的特征  为:
为:

公式里的  为归一化项,函数f和g可以灵活选择(注意之前讲的attention其实是f和g选了特例的结果)。在论文中,f取得是高斯关系函数,g取得是线性函数。提出的non-local模块被加到了CNN基线方法中,在多个数据集上取得了SOTA结果。
为归一化项,函数f和g可以灵活选择(注意之前讲的attention其实是f和g选了特例的结果)。在论文中,f取得是高斯关系函数,g取得是线性函数。提出的non-local模块被加到了CNN基线方法中,在多个数据集上取得了SOTA结果。
之后还有一些文献提出了其他把CNN和attention结合的方法[7],都取得了提升效果。看到了这里,也对attention有了新的层次的理解。
6. 山高水深——计算机视觉中,Attention will be all you need。
在NLP中transformer已经一统江湖,那么在计算机视觉中,transformer是否能够一统江湖呢?这个想法本身是non-trivial的,因为语言是序列化的一维信息,而图像天然是二维信息。CNN本身是天然适应图像这样的二维信息的,但transformer适应的是语言这种是一维信息。上一层已经讲了,有很多工作考虑把CNN和attention加以结合,那么能否设计纯transformer的网络做视觉的任务呢?
最近越来越多的文章表明,Transformer能够很好地适应图像数据,有望在视觉届也取得统治地位。
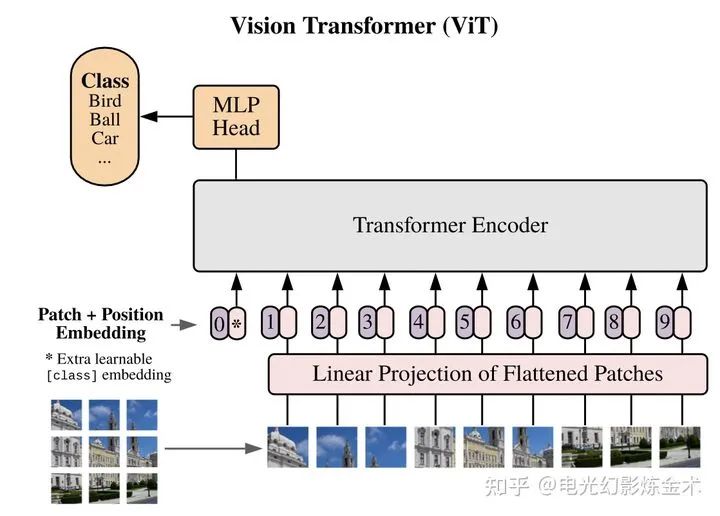
第一篇的应用到的视觉Transformer来自Google,叫Vision Transformer[8]。这篇的名字也很有趣,an image is worth 16x16 words,即一幅图值得16X16个单词。这篇文章的核心想法,就是把一幅图变成16x16的文字,然后再输入Transformer进行编码,之后再用简单的小网络进行下有任务的学习,如下图所示。
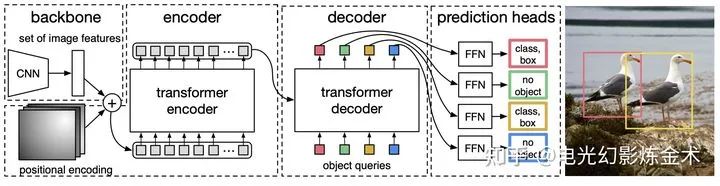
Vision transformer主要是把transformer用于图像分类的任务,那么能不能把transformer用于目标检测呢?Facebook提出的模型DETR(detection transformer)给出了肯定的回答[9]。DETR的模型架构也非常简单,如下图所示,输入是一系列提取的图片特征,经过两个transformer,输出一系列object的特征,然后再通过前向网络将物体特征回归到bbox和cls。更详细的介绍可以参看
@陀飞轮
的文章:

在计算机视觉的其他领域,Transformer也在绽放新的活力。目前Transformer替代CNN已经成为一个必然的趋势,也就是说,Attention is all you need将在计算机视觉也成立。看到这里,你将会发现attention山高水深,非常玄妙。
7. 山水轮回——结构化数据中,Attention是辅助GNN的利器。
前面几层我们已经看到,attention在一维数据(比如语言)和二位数据(比如图像)都能有很好的应用,那么对于高维数据(比如图数据),能否有出色的表现呢?
最早地将attention用于图结构的经典文章是Graph Attention Networks(GAT,哦对了这个不能叫做GAN)[10]。图神经网络解决的基本问题是,给定图的结构和节点的特征,如何获取一个图的特征表示,来在下游任务(比如节点分类)中取得好的结果。那么爬到第七层的读者们应该可以想到,attention可以很好的用在这种关系建模上。
GAN的网络结构也并不复杂,即便数学公式有一点点多。直接看下面的图。

每两个节点之间先做一次attention获取一组权重,比如图中的  表示1和2之间的权重。然后再用这组权重做一个加权平均,再使用leakyRelu做一个激活。最后把多个head的做一个平均或者联结即可。
表示1和2之间的权重。然后再用这组权重做一个加权平均,再使用leakyRelu做一个激活。最后把多个head的做一个平均或者联结即可。
看懂了原来GAT其实就是attention的一个不难的应用,就进入了第七层,山水轮回。
8.山中有山——逻辑可解释性与Attention的关系
尽管我们已经发现attention非常有用,如何深入理解attention,是一个研究界未解决的问题。甚至进一步说,什么叫做深入理解,都是一个全新的问题。大家想想看,CNN是什么时候提出来的?LeNet也就是98年。CNN我们还没理解的非常好,attention对于我们来说更新了。
我认为,attention是可以有比CNN更好的理解的。为什么?简单一句话,attention这种加权的分析,天然就具有可视化的属性。而可视化是我们理解高维空间的利器。
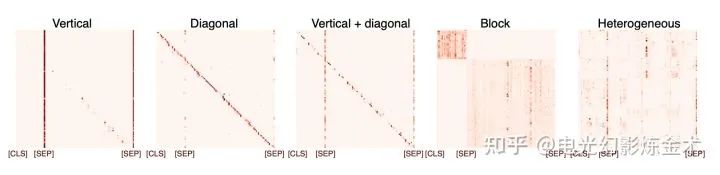
给两个例子,第一个例子是NLP中的BERT,分析论文显示[11],学习到的特征有非常强的结构性特征。
还有一个FACEBOOK最近的的工作DINO[12],下图图右是无监督训练得到的attention map。是不是非常的震惊?

到目前为止,读者已经到了新的境界,山中有山。
9.山水合一——Attention的多种变种及他们的内在关联
就跟CNN可以搭建起非常厉害的检测模型或者更高级的模型一样,attention的最厉害的地方,是它可以作为基本模块搭建起非常复杂的(用来灌水的)模型。
这里简单列举一些attention的变种[13]。首先是全局attention和部分attention。
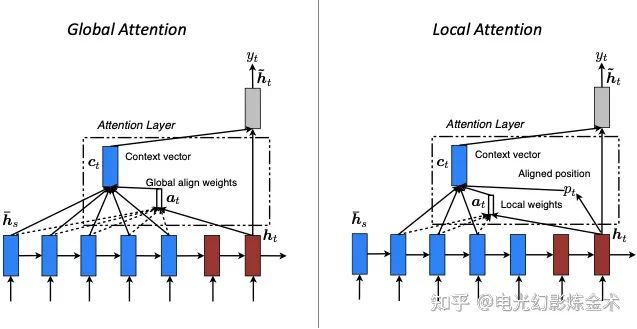
全局attention就是上面讲的,部分attention主要是还允许某些特征在做attention之前先做融合,再进一步attention。最近爆火的swin transformer就可以看作是把这个变种发扬光大了。
接下来是hard attention和soft attention。

之前我们讲的基本都是soft attention。但是站到采样的角度来讲,我们可以考虑hard attention,把概率当成一个分布,然后再进行多项式采样。这个或许在强化学习里面,有启发性作用。
最近又有一堆觉得MLP也挺强的工作[14]。笔者认为,他们也是参考了attention的模式,采用了不同的结构达到同一种效果。当然,说不定attention最后会落到被MLP吊打的下场。
但是attention的理念,永远不会过时。attention作为最朴素也最强大的数据关系建模基本模块,必将成为每个AI人的基本功。
还有不会过时的是对数据的理解和分析能力。上面介绍了大量的模型,但是真正我们能够求解好某个特定的问题,还得来源于对问题结构的充分认知。这个话题有机会我们再慢慢讨论。
到这里已经到了第九层山水合一的境界。万象归春,所有的模型都只是促进我们对数据的深入认知而已。
双一流高校研究生团队创建 ↓
专注于计算机视觉原创并分享相关知识 ☞
整理不易,点赞三连!