
注意力机制研究现状综述(Attention mechanism)
点击上方“机器学习与生成对抗网络”,关注星标
获取有趣、好玩的前沿干货!
知乎作者:好好先生 侵删
https://zhuanlan.zhihu.com/p/361893386
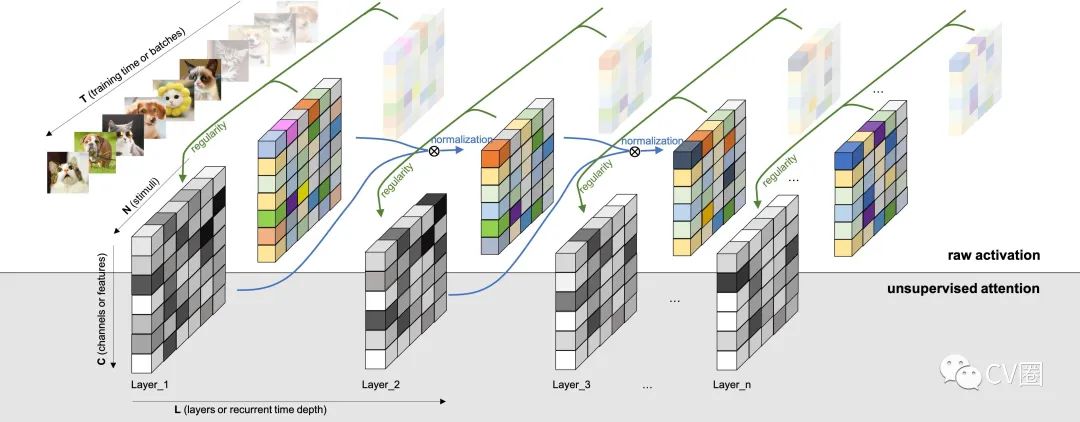

1 背景知识
2 注意力机制的原理与分类
2.1 注意力机制原理
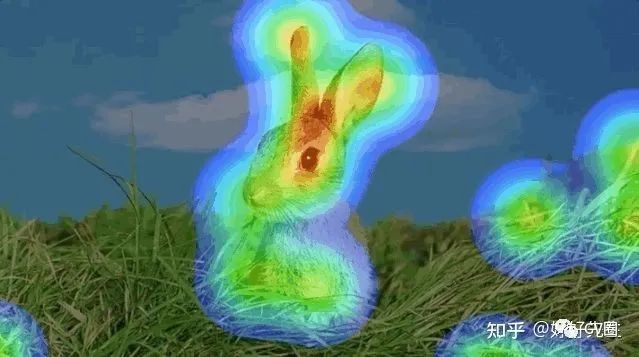
2.2 注意力机制分类
软注意力机制。可分为基于输入项的软注意力(Item-wise Soft Attention)和基于位置的软注意力(Location-wise Soft Attention)
强注意力机制。可分为基于输入项的强注意力(Item-wise Hard Attention)和基于位置的强注意力(Location-wise Hard Attention)。
自注意力机制。是注意力机制的变体,其减少了对外部信息的依赖,更擅长捕捉数据或特征的内部相关性。自注意力机制在文本中的应用,主要是通过计算单词间的互相影响,来解决长距离依赖问题。
3 软注意力机制(soft-attention)
3.1 具有视觉注意的神经图像字幕生成
Show, Attend and Tell: Neural Image Caption Generation with Visual Attention Edit
主要思想:受机器翻译和目标检测领域最新工作的启发,文章引入了一种基于注意力的模型,该模型可自动学习以描述图像的内容。文章描述了如何使用标准反向传播技术以确定性的方式并通过最大化变分下界随机地训练该模型。 文章还通过可视化展示了模型如何能够自动学习将注视固定在显着对象上,同时在输出序列中生成相应的单词。文章通过三个基准数据集的最新性能验证了注意力的使用:Flickr8k,Flickr30k和MS COCO。
论文地址:https://arxiv.org/pdf/1502.03044v3.pdf
代码地址:https://github.com/sgrvinod/a-PyTorch-Tutorial-to-Image-Captioning
3.2 使用视觉注意的动作识别
Action Recognition using Visual Attention
主要思想:针对视频中的动作识别任务,文章提出了一种基于软注意力的模型。文章使用具有长短期记忆(LSTM)单元的多层递归神经网络(RNN),它们在空间和时间上都很深。 文章的模型学会了选择性地专注于视频帧的各个部分,并在瞥了一眼之后对视频进行了分类。该模型从本质上了解框架中的哪些部分与手头任务相关,并对其赋予更高的重要性。文章在UCF-11(YouTube动作),HMDB-51和Hollywood2数据集上评估了该模型,并分析了该模型如何根据场景和所执行的动作来集中注意力。
论文地址:https://arxiv.org/pdf/1511.04119v3.pdf
代码地址:https://github.com/kracwarlock/action-recognition-visual-attention
3.3 利用时间结构描述视频
Describing Videos by Exploiting Temporal Structure
主要思想:在使用递归神经网络(RNN)进行图像描述方面的最新进展激发了对其在视频描述中的应用的探索。但是,尽管图像是静态的,但处理视频需要对它们的动态时间结构进行建模,然后将这些信息正确地集成到自然语言描述中。 在这种情况下,提出了一种成功考虑视频的本地和全局时间结构以产生描述的方法。首先,文章的方法结合了短时态动力学的时空3-D卷积神经网络(3-D CNN)表示。对3-D CNN表示进行视频动作识别任务方面的训练,以生成适合于人类动作和行为的表示。其次,文章提出了一种时间注意机制,该机制可以超越本地时间建模,并学习在给定生成文本的RNN的情况下自动选择最相关的时间段。
论文地址:https://arxiv.org/pdf/1502.08029v5.pdf
代码地址:https://github.com/yaoli/arctic-capgen-vid
3.4 用于改善超声扫描平面检测
Attention-Gated Networks for Improving Ultrasound Scan Plane Detection
主要思想:在这项工作中,将注意门控网络应用于实时自动扫描平面检测以进行胎儿超声筛查。胎儿超声中的扫描平面检测是一个具有挑战性的问题,因为图像质量差,导致临床医生和自动算法的解释性差。 为了解决这个问题,文章建议结合自门控软注意力机制。软注意力机制会生成一个端到端可训练的门控信号,从而使网络能够将对预测有用的本地信息关联起来。所提出的注意力机制是通用的,可以轻松地合并到任何现有的分类体系结构中,而只需要几个附加参数。文章表明,当基础网络具有高容量时,合并的注意力机制可以在提高整体性能的同时提供有效的对象定位。当基本网络的容量较低时,该方法将大大优于基准方法,并大大减少了误报率。
论文地址:https://arxiv.org/pdf/1804.05338v1.pdf
代码地址:https://github.com/ozan-oktay/Attention-Gated-Networks
3.5 使用软注意力机制的自适应物理信息神经网络
主要思想:提出了一种从根本上新的方法来自适应地训练PINN,其中的适应权重是完全可训练的,因此神经网络可以自己了解解决方案的哪些区域是困难的并被迫专注于解决方案的区域,这让人联想到软计算机视觉中使用的乘法蒙版注意机制。这些自适应PINN的基本思想是在相应的损失较高的地方使权重增加,这是通过训练网络以同时最小化损失和最大权重(即在成本表面找到鞍点)来实现的。文章显示,这在形式上等效于使用基于惩罚的方法来解决PDE约束的优化问题,尽管在某种意义上单调非递减惩罚系数是可训练的。在使用Allen-Cahn刚性PDE进行的数值实验中,自适应PINN在L2误差方面的表现优于其他最新的PINN算法,同时使用的训练次数更少。附录包含Burger's和Helmholtz PDE的其他结果,这些结果证实了Allen-Cahn实验中观察到的趋势。在成本表面找到鞍点。文章显示,这在形式上等效于使用基于惩罚的方法来解决PDE约束的优化问题,尽管在某种意义上单调非递减惩罚系数是可训练的。在使用Allen-Cahn刚性PDE进行的数值实验中,自适应PINN在L2误差方面的表现优于其他最新的PINN算法,同时使用的训练次数更少。附录包含Burger's和Helmholtz PDE的其他结果,这些结果证实了Allen-Cahn实验中观察到的趋势。在成本表面找到鞍点。文章显示,这在形式上等效于使用基于惩罚的方法来解决PDE约束的优化问题,尽管在某种意义上单调非递减惩罚系数是可训练的。在使用Allen-Cahn刚性PDE进行的数值实验中,自适应PINN在L2误差方面的表现优于其他最新的PINN算法,同时使用的训练次数更少。附录包含Burger's和Helmholtz PDE的其他结果,这些结果证实了Allen-Cahn实验中观察到的趋势。在使用Allen-Cahn刚性PDE进行的数值实验中,自适应PINN在L2误差方面的表现优于其他最新的PINN算法,同时使用的训练次数更少。附录包含Burger's和Helmholtz PDE的其他结果,这些结果证实了Allen-Cahn实验中观察到的趋势。在使用Allen-Cahn刚性PDE进行的数值实验中,自适应PINN在L2误差方面的表现优于其他最新的PINN算法,同时使用的训练次数更少。附录包含Burger's和Helmholtz PDE的其他结果,这些结果证实了Allen-Cahn实验中观察到的趋势。
论文地址:https://arxiv.org/pdf/2009.04544v2.pdf
代码地址:https://github.com/levimcclenny/SA-PINNs
3.6 视觉注意的递归模型
Recurrent Models of Visual Attention
主要思想:将卷积神经网络应用于大图像在计算上是昂贵的,因为计算量与图像像素的数量成线性比例。文章提出了一种新颖的递归神经网络模型,该模型能够通过自适应选择区域或位置的序列并仅以高分辨率处理选定的区域,从而从图像或视频中提取信息。 像卷积神经网络一样,提出的模型具有内置的平移不变性程度,但是可以独立于输入图像大小来控制其执行的计算量。尽管模型是不可微的,但可以使用强化学习方法来学习特定于任务的策略,从而对其进行训练。文章在几个图像分类任务上评估文章的模型,其中模型在杂乱图像上的表现明显优于卷积神经网络基线,而在动态视觉控制问题上,模型学习该模型来学习跟踪简单对象,而没有明确的训练信号。
论文地址:https://arxiv.org/pdf/1406.6247v1.pdf
代码地址:https://github.com/kevinzakka/recurrent-visual-attention
4 强注意力机制(hard-attention)
4.1 基于注意力从街景图像中提取结构化信息
Attention-based Extraction of Structured Information from Street View Imagery
主要思想:文章提出了一种基于CNN,RNN和新颖的注意力机制的神经网络模型,该模型在具有挑战性的法国街道名称标志(FSNS)数据集上实现了84.2%的准确性,大大优于之前的最新水平(Smith'16)。达到72.46%。此外,文章的新方法比以前的方法更简单,更通用。 为了证明文章模型的通用性,文章证明了它在源自Google街景的更具挑战性的数据集上也能很好地发挥作用,该数据集的目标是从店面中提取商户名称。最后,文章研究了使用不同深度的CNN特征提取器所导致的速度/精度折衷。令人惊讶的是,文章发现更深层次并不一定总是更好(就准确性和速度而言)。文章生成的模型简单,准确,快速,可以在各种具有挑战性的现实文本提取问题中大规模使用。
论文地址:https://arxiv.org/pdf/1704.03549v4.pdf
代码地址:https://github.com/tensorflow/models
4.2 字符级的非单调强注意力
Hard Non-Monotonic Attention for Character-Level Transduction
主要思想:字符级字符串到字符串的转换是各种NLP任务的重要组成部分。目标是将输入字符串映射到输出字符串,其中这些字符串的长度可能不同,并且具有取自不同字母的字符。 最近的方法已将序列到序列模型与注意机制一起使用,以了解模型在输出字符串的生成过程中应关注输入字符串的哪些部分。软注意力和硬单调注意力都已被使用,但是硬非单调注意力只被用于其他序列建模任务中,例如图像字幕,并且需要随机近似来计算梯度。在这项工作中,文章引入了一种精确的多项式时间算法来边缘化两个字符串之间非单调对齐的指数数量,这表明辛苦的注意力模型可以看作是经典IBM Model 1的神经重新参数化。
论文地址:https://arxiv.org/pdf/1808.10024v2.pdf
代码地址:https://github.com/shijie-wu/neural-transducer
4.2 提高视觉硬注意力模型的准确性
Saccader: Improving Accuracy of Hard Attention Models for Vision
主要思想:提出了一个新颖的硬注意力模型,文章称其为Saccader。Saccader的关键是预培训步骤,该步骤仅需要类标签,并为策略梯度优化提供了最初的关注位置。文章最好的模型缩小了与通用ImageNet基准的差距,从而实现了75% top-1和 91%前5名,而只关注不到三分之一的图片。
论文地址:https://arxiv.org/pdf/1908.07644v3.pdf
代码地址:https://github.com/google-research/google-research
4.3 艰巨的任务克服灾难性的遗忘
Overcoming catastrophic forgetting with hard attention to the task
主要思想:当神经网络在对后续任务进行训练后丢失了在先前任务中学习的信息时,就会发生灾难性的遗忘。对于具有顺序学习能力的人工智能系统来说,这个问题仍然是一个障碍。 在本文中,文章提出了一种基于任务的硬注意力机制,该机制可以保留先前任务的信息,而不会影响当前任务的学习。通过随机梯度下降可以同时针对每个任务学习硬性注意遮罩,并且可以利用以前的遮罩来调节这种学习。文章表明,所提出的机制可有效减少灾难性遗忘,将电流率降低45%至80%。文章还表明它对不同的超参数选择具有鲁棒性,并且它提供了许多监视功能。该方法具有控制学习知识的稳定性和紧凑性的可能性,文章认为这对于在线学习或网络压缩应用程序也很有吸引力。
论文地址:https://arxiv.org/pdf/1801.01423v3.pdf
代码地址:https://github.com/joansj/hat
5 自注意力机制(self-attention)
5.1 增强的自我注意网络
Reinforced Self-Attention Network: a Hybrid of Hard and Soft Attention for Sequence Modeling
主要思想:文章将软注意力和硬注意力整合到一个上下文融合模型中,即 "强化自我注意力(ReSA)",以达到相互促进的目的。在ReSA中,硬注意修剪了一个序列供软自注意处理,而软注意则反馈奖励信号以方便训练硬注意。为此,文章开发了一种名为 "强化序列采样(RSS) "的新型硬注意力,并行选择标记,并通过策略梯度进行训练。使用两个RSS模块,ReSA有效地提取每对选择的tokens之间的稀疏依赖关系。最后,文章提出了一个完全基于ReSA的无RNN/CNN的句子编码模型--"强化自注意力网络(ReSAN)"。它在斯坦福自然语言推理(SNLI)和涉及成分知识的句子(SICK)数据集上都达到了最领先的性能。
论文地址:https://arxiv.org/pdf/1801.10296v2.pdf
代码地址:https://github.com/taoshen58/DiSAN
5.2 注意就是您所需要的
Attention Is All You Need
主要思想:优势序列转导模型基于编码器-解码器配置中的复杂递归或卷积神经网络。表现最佳的模型还通过注意力机制连接编码器和解码器。 文章提出了一种新的简单网络体系结构,即Transformer,它完全基于注意力机制,完全消除了递归和卷积。在两个机器翻译任务上进行的实验表明,这些模型在质量上具有优势,同时具有更高的可并行性,并且所需的训练时间明显更少。文章的模型在WMT 2014英德翻译任务中达到了28.4 BLEU,比现有的最佳结果(包括合奏)提高了2 BLEU。在2014年WMT英语到法语翻译任务中,文章的模型在八个GPU上进行了3.5天的训练后,建立了新的单模型最新的BLEU分数41.8。
论文地址:https://arxiv.org/pdf/1706.03762v5.pdf
代码地址:https://github.com/tensorflow/tensor2tensor
5.3 抽象句摘要的神经注意模型
A Neural Attention Model for Abstractive Sentence Summarization
主要思想:基于文本提取的摘要本质上受到限制,但是事实证明,生成样式的抽象方法难以构建。在这项工作中,文章提出了一种完全由数据驱动的抽象句子摘要方法。 文章的方法利用了基于自注意力的模型,该模型生成以输入句子为条件的摘要的每个单词。尽管该模型在结构上很简单,但是可以轻松地对其进行端到端培训,并可以扩展为大量的培训数据。该模型显示了DUC-2004共享任务的性能显着提高(与几个强基准相比)。
论文地址:https://arxiv.org/pdf/1509.00685v2.pdf
代码地址:https://github.com/toru34/rushemnlp2015
5.4 通过共同学习对齐和翻译的神经机器翻译
Neural Machine Translation by Jointly Learning to Align and Translate
主要思想:神经机器翻译是最近提出的机器翻译方法。与传统的统计机器翻译不同,神经机器翻译的目的是构建可以联合调整以最大化翻译性能的单个神经网络。 最近提出的用于神经机器翻译的模型通常属于编码器-解码器家族,并且由将源句子编码为固定长度向量的编码器组成,解码器根据该固定长度向量生成翻译。在本文中,文章推测使用固定长度向量是提高此基本编码器-解码器体系结构性能的瓶颈,并建议通过允许模型自动(软)搜索对象的部分来扩展此范围。与预测目标单词相关的源句子,而不必明确地将这些部分形成为一个困难的部分。
论文地址:https://arxiv.org/pdf/1409.0473v7.pdf
代码地址:https://github.com/graykode/nlp-tutorial
5.5 具有相对位置表示的自我注意
Self-Attention with Relative Position Representations
主要思想:Vaswani等人介绍的Transformer完全依赖于注意力机制。(2017)取得了机器翻译的最新成果。与递归和卷积神经网络相反,它没有在其结构中显式地建模相对或绝对位置信息。 相反,它需要在其输入中添加绝对位置的表示。在这项工作中,文章提出了一种替代方法,扩展了自我注意机制以有效考虑相对位置或序列元素之间距离的表示。在WMT 2014英语到德语和英语到法语的翻译任务中,这种方法分别比绝对位置表示法改进了1.3 BLEU和0.3 BLEU。值得注意的是,文章观察到将相对位置和绝对位置表示相结合并不能进一步提高翻译质量。文章描述了文章方法的有效实现,并将其转换为关系感知的自我注意机制的实例,该机制可以推广到任意图标记的输入
论文地址:https://arxiv.org/pdf/1803.02155v2.pdf
代码地址:https://github.com/tensorflow/tensor2tensor
5.6 结构化的自注意力句子嵌入
A Structured Self-attentive Sentence Embedding
主要思想:本文提出了一种通过引入自我注意来提取可解释句子嵌入的新模型。代替使用向量,文章使用二维矩阵表示嵌入,矩阵的每一行都位于句子的不同部分。 文章还为该模型提出了一种自注意力机制和一个特殊的正则化术语。作为副作用,嵌入带有一种直观的方式,可以直观地看到句子的哪些特定部分被编码到嵌入中。文章在3个不同的任务上评估文章的模型:作者概况分析,情感分类和文本蕴涵。结果表明,在所有这3个任务中,与其他句子嵌入方法相比,文章的模型产生了显着的性能提升。
论文地址:https://arxiv.org/pdf/1703.03130v1.pdf
代码地址:https://github.com/facebookresearch/pytext
猜您喜欢:
CVPR 2021 | GAN的说话人驱动、3D人脸论文汇总
附下载 |《TensorFlow 2.0 深度学习算法实战》
附下载 | 超100篇!CVPR 2020最全GAN论文梳理汇总!