
好快好强 | GPU端精度最高、速度最快的Backbone模型担当GENet

标题&作者团队
【Happy导语】该文是阿里巴巴提出了一种GPU端高效&高精度网路架构设计新方案。不同于之前的MobileNet、EfficientNet以及RegNet等网络采用相同的模块构建整个网络,该文对不同阶段的模块进行分析并得出这样的结论:在网络的low-level阶段采用BasicBlock,而在high-level阶段采用Bottleneck/InvertedResidualBlock可以最大化的利用GPU并得到更快的推理速度与模型精度(精度高达81.3%且速度超快)。Happy建议对网络架构有兴趣的朋友可以仔细看一下原文,文末附论文下载链接。
Abstract
在工业界大多算法均是基于GPU进行推理,这就要求AI算法不仅应当具有高识别率,同时还要具有更低的推理延迟。尽管已有诸多研究尝试优化深度模型的架构以进行更有效的推理,然而它们并未充分利用现代GPU的架构进行快速推理,从而导致了次优性能。
为解决上述问题,作者在大量实验研究的基础上提出了一种GPU端高效网络设计的通用范式,该设计范式促使作者仅需要采用简单而轻量的NAS方法即可得到高效且高精度的GPU端网络架构。基于所设计的网络架构设计范式,作者提出了一类GPU端高效的网络,称之为GENet。
作者在多个GPU平台与推理引擎下对所得到的网络进行了充分的评估,所提方法不仅在ImageNet上取得了不低于81.3%的top1精度,而且在GPU端比EfficientNet快6.4倍。与此同时,所提方法同样优于其他效率高于EfficientNet的SOTA方法。
该文的主要贡献有如下:
-
提出一种新颖的GPU端高效网络架构设计空间;
-
基于所设计网络架构范式,提出一种轻量而高效LLR-NAS(Local-Linear Regression NAS)方法进行GPU端高效网络架构搜索;
-
所得到的GENet不仅具有媲美EfficientNet的高精度,而且具有更快的推理速度。
Network Design Space
在这部分内容中,我们将主要介绍一下如何一步步得到所提网络架构设计空间。首先介绍一下主流网络中常用的三种基本模块,然后对其推理速度进行了分析,最后基于实验分析得出网络架构设计空间范式。
Basic Block and MasterNet Backbone
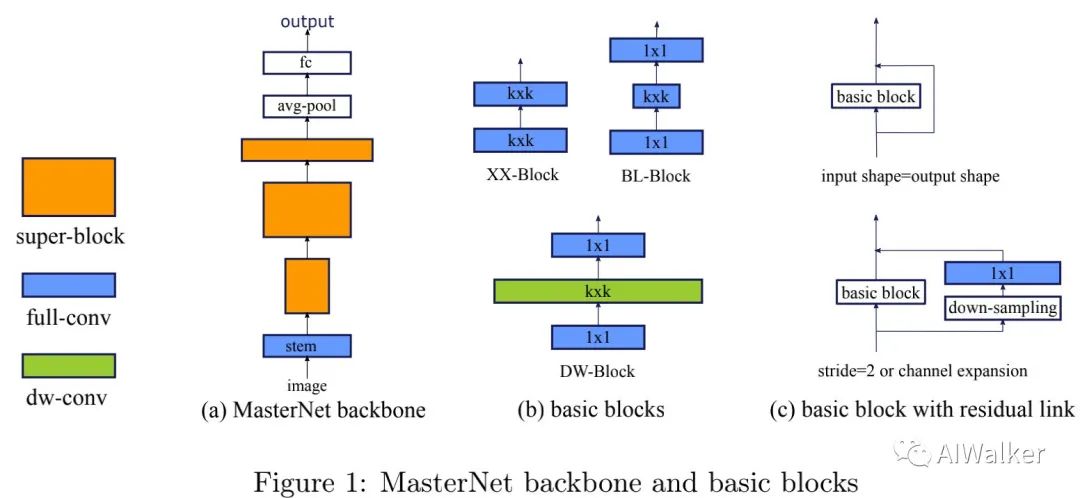
image-20200627164927617
上图a给出了目前网络架构设计中的主流架构(ResNet、ResNeSt、EfficientNet、RegNet、MobileNet等等均采用了类似的架构体系)形态,这也是该文的架构形态。
作者将该架构形态称之为MasterNet,它的每个阶段称之为Super-Block,每个Super-Block由同类型的多个BasicBlock构成,每个BasicBlock由深度、宽度以及stride等参数进行描述。一般而言,Super-Block的第一个模块采用stride=2进行特征下采样,后续模块采用stride=1的模式。而MasterNet的第一层是一个stride=2的stem模块;MasterNet的最后为GAPHead模块(它包含一个全局均值池化与一个全连接层,用于分类)。现有研究已经证实:上述网络架构形态足以得到GPU端的高性能低延迟的网络架构。而不同网络架构的关键区别在于BasicBlock的差异。而这也是本文的关注重点。
在BasicBlock方面,作者考虑了三种类型的模块(见上图b),分别如下:
-
XX-Block(ResNet18、ResNet34中的基本模块);
-
BL-Block(ResNet50、ResNet101中的基本模块);
-
DW-Block(MobileNetv2的基本模块)。
上图c则给出了上述模块嵌入到残差模块中的示意图以及stride=2时的模块示意图。
GPU Inference Latency
作者对上述三个模块在GPU端的推理速度进行可控实验分析,所有耗时实验均重复30次,剔除10最低与最高后进行平均统计。作者在NVIDIA V100硬件平台下采用FP16精度和
分辨率进行实验。不同角度的实验分析如下。
-
BatchSize。下图a给出l不同BatchSize下ResNet50、ResNet152、MobileNetV2、EfficientNet-B0的推理延迟。从图中可以看到:推理延迟并非常数,会随BatchSize而变化,这是因为大的BatchSize允许GPU进行并行计算从而更高效。因此,在进行推理延迟对比时必须制定BatchSize,在该文中作者默认设置BatchSize=64。事实上,这种推理耗时更符合实际需求,我们一般评价一个模型的速度看到是其吞吐量(一块GPU倍充分利用时每秒钟能处理多少张图片),而非一个样例的一次推理。
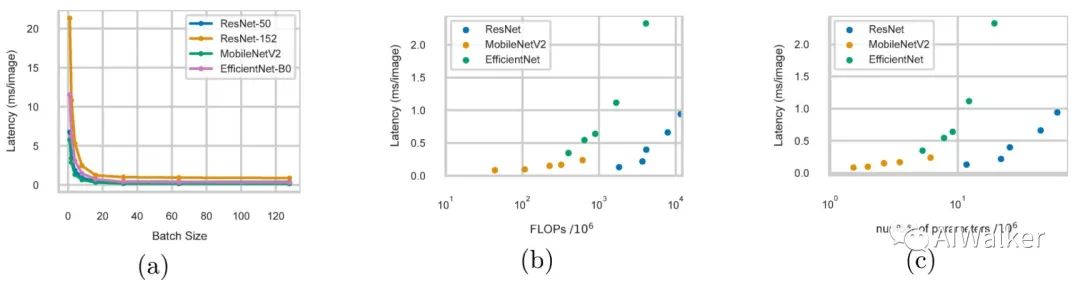
image-20200627171050232
-
FLOPs & Model Size。FLOPs是一种“流行”的用来评价模型效率的准则。但是“FLOPs低不等于效率高”,上图也说明了这一点。尽管EfficientNet号称具有非常低的FLOPs,但它的推理速度反而慢。同时,推理速度也不与模型参数量存在线性关系。这一点其实在ShuffleNetV2、RegNet、OFANet等方法中均有阐述,感兴趣的可以去看一下相关论文。
-
BasicBlocks。这里将对前面所提到的三种模块进行分析研究。在实验设计中,基于XX-Block的网络包含5个XX-Block,而BL-Block与DW-Block的网络则包含10个模块。推理速度见下图,从图中可以看到:(1)DW-Block的推理速度要快于BB-Block;(2)当r=1时,BL-Block的推理速度要比XX-Block更慢(这个很正常,两个r=1的BL-Block明显比XX-Block大)。仅仅从上图a和b出发,可能采用BL-Block或者DW-Block更为合理(这也是ResNet与EfficientNet的设计范式)。
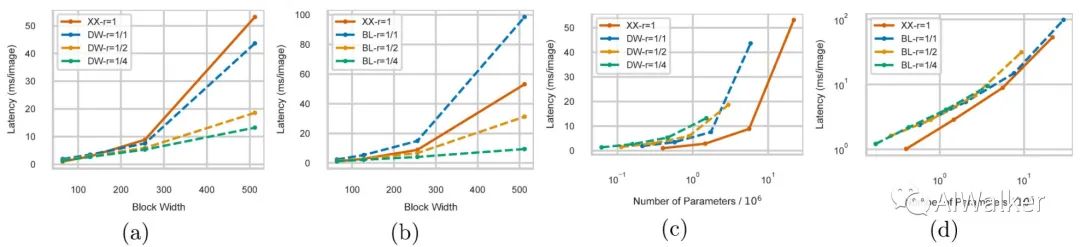
image-20200627172032376
-
Model Capacity。作者认为除了上述分析外,还有另外一个维度需要考虑,那就是Model Capacity,它将影响模型的拟合能力。关于Model Capacity的一个简单度量准则是模型参数量。实验分析见上图c和d,从中可以看到:在相同Model Capacity下,XX-Block事实上非常高效。从某种角度来讲,BL-Block与DW-Block是XX-Block的低秩近似。但BL-Block与DW-Block接近满秩近似时,相应模块实际上是低效的。也就是说:BL/DW-Block是否比XX-Block更高效依赖于网络的特定层是否倾向于低秩架构。
Intrinsic Rank of Convolutional Layers
受启发于上述分析,作者尝试对不同阶段的卷积进行分析。主要针对ResNet18和ResNet34两个网络进行了分析,因ResNet50等更深网路采用的BL-Block故而被排出在外。第三个网络是作者手动设计的网络,称之为ProfilingNet132.三个网络均在ImageNet数据集上训练360epoch。
下图给出了不同阶段最后一个卷积核的奇异值分布,注:奇异值进行了归一化处理。从图中可以看出:high-level的奇异值衰减的更快,这也就意味着:应当在网络的low-level阶段采用XX-Block,而在网络的high-level阶段采用BL/DW-Block以最大化GPU推理效率。
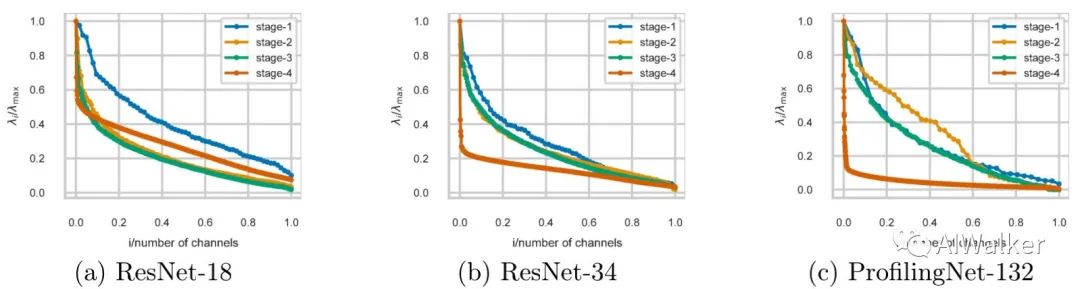
image-20200627173905240
GPU-Efficient Networks
前述实验给出了本文的核心:GPU端高效网络设计范式。作者基于该先验信息设计GPU端高效网络。作者首先采用手动方式设计MasterNet,然后将其作为LLR-NAS的初始网络并进行优化。
Design MasterNet
为得到一个好的初始化架构,作者设计了20个网络。所有网络均具有0.34ms推理延迟(注:BatchSize=64,这也是ResNet50、EfficientNet的推理延迟)。作者在ImageNet上分别对这20个网络训练120epoch。对于BL-Block,作者固定
;对于DW-Block,作者固定
。实验结果见下表,注:这里仅提供了4个最佳。
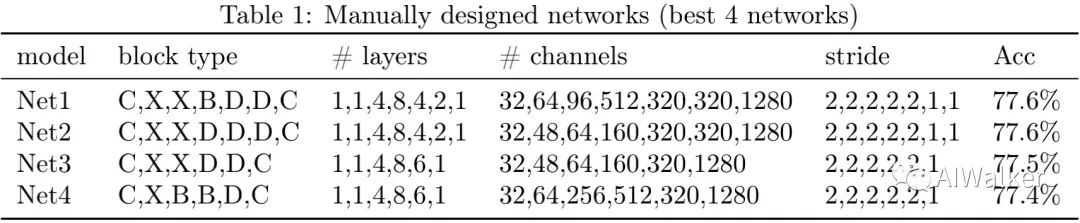
image-20200627183806295
注:上表第一列表示网络ID,第二列表示模块类型(C表示常规卷、X表示XX-Block,B表示BL-Block,D表示DW-Block),第三列表示不同阶段的模块数,第四列表示不同阶段的通道数,第五列表示不同阶段的stride信息,最后一列表示模型的精度。表中结果验证了前述分析结论,最佳的模型均为low-level阶段采用XX-Block,在high-level采用BL/DW-Block。
作者选用Net1作为初始MasterNet,需要注意的是MasterNet的参数配置对应并不大,因为后面作者将采用NAS进行最终模型的搜索。当然Net2与Net3也是MasterNet的不错选择。
Local Linear Regression NAS
作者提出采用NAS方式搜索MasterNet的结构,所用的NAS称之为LLR-NAS。假设MasterNet包含M的Super-Block
,每个Super-Block
可以参数化为
(
分别表示深度、通道数以及模块类型),除了模块类型外,作者将不同核尺寸和
参数的模块视作不同的模块类型。
LLR-NAS的流程如下:
-
Distillation:对于
,采用随机模块
进行初始化,微调直至收敛并得到对应网络的验证精度
。重复该步骤直到每个类型的
包含N个微调精度
。
-
Regression:假设
表示MasterNet的精度,采用最小二乘进行回归估计伪梯度
,。基于该伪梯度,我们就可以预测网络结构在不同参数
下的精度。
-
Selection:随机生成大量结构
并采用上述伪梯度计算其精度,最后选择具有最佳推理速度的模型。
与此同时,作者在不同分辨率输入下采用上述伪梯度进行最佳网络架构搜索,所选择的架构在对应分辨率下进行训练,最终选择训练后具有最佳精度的模型作为对应分辨率下的最优模型。注:作者分别设置延迟耗时为0.34/0.2/0.1三种约束得到了GENet-Large/GENet-normal/GENet-light。
Experiment
在该部分内容中,作者对比了ResNet、EfficientNet、MnasNet、MobileNetV2、DNANet、DFNet、OFANet以及RegNet等网络架构。
在ImageNet数据集上对比了模型精度,在LLR-NAS阶段,随机从训练集中采样50000样本作为验证集。每个SuperBlock以0.01学习率,BatchSize=256微调30epoch,卷积核尺寸可调空间
,输入分辨率可调空间
,参数r的可调空间分别为
(对应BL-Block)和
(对应DW-Block),LLR-NAS阶段在24V100GPU上训练60小时。而最终的模型训练480epoch,同时采用了标签平滑、mixup、random-erase、AutoAugment等训练技巧。
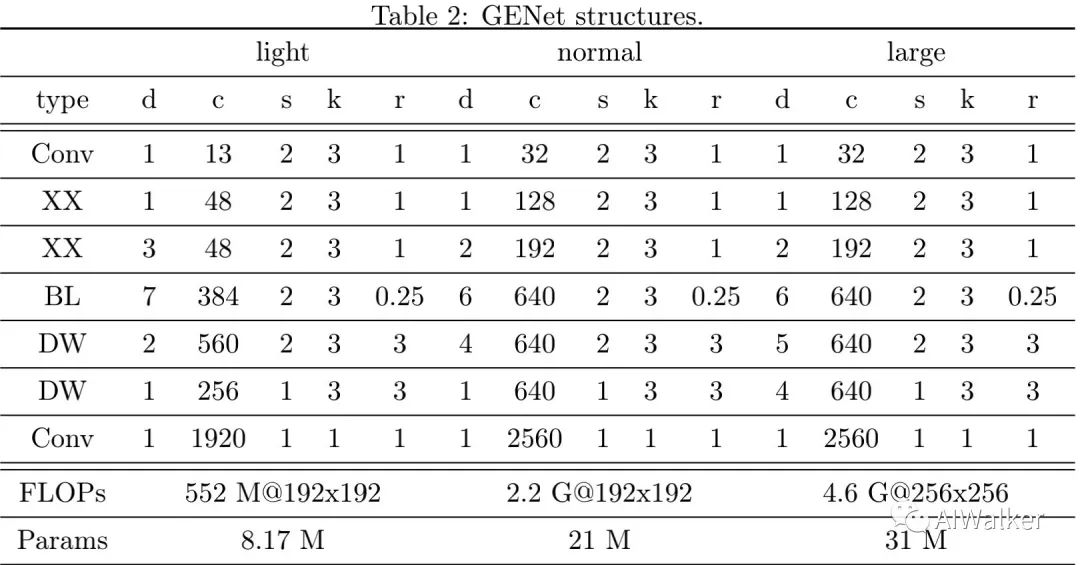
image-20200627201534335
上表给出了GENet在不同约束下的网络架构配置信息,可以看到其中的DW-Block搜索的参数
,这与EfficientNet中的
完全不同。对比GENet的三种不同配置,可以看到:GENet-large网络提升high-level阶段的深度而降低了low-level阶段的深度。最后两行还给出了不同配置模型的FLOPs与分辨率输入。
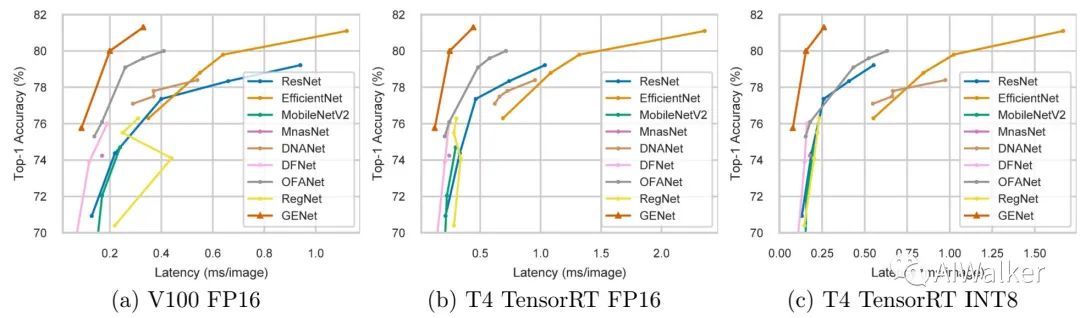
image-20200627202133729
为评估所得到的网络在GPU端的推理速度,作者考虑了三种配置:(1) NVIDIA V100-FP16(大多论文中常用配置);(2) NVIDIA T4-FP16+TensorRT(推理端评测);(3) NVIDIA T4-INT8+TensorRT(推理端评测,采用TensorRT内置量化工具进行INT8量化)。不同模型的精度与耗时见上图,可以看到:GENet以明显优势优于其他网络。在相同推理速度下,GENet-large以5.0%的指标优于EfficientNet-B0,达到了81.3%的精度且比EfficientNet-B3更快。尽管GENet是针对V100而优化得到的,但它对于T4GPU同样高效,这侧面表明了GENet跨GPU平台的迁移性能。
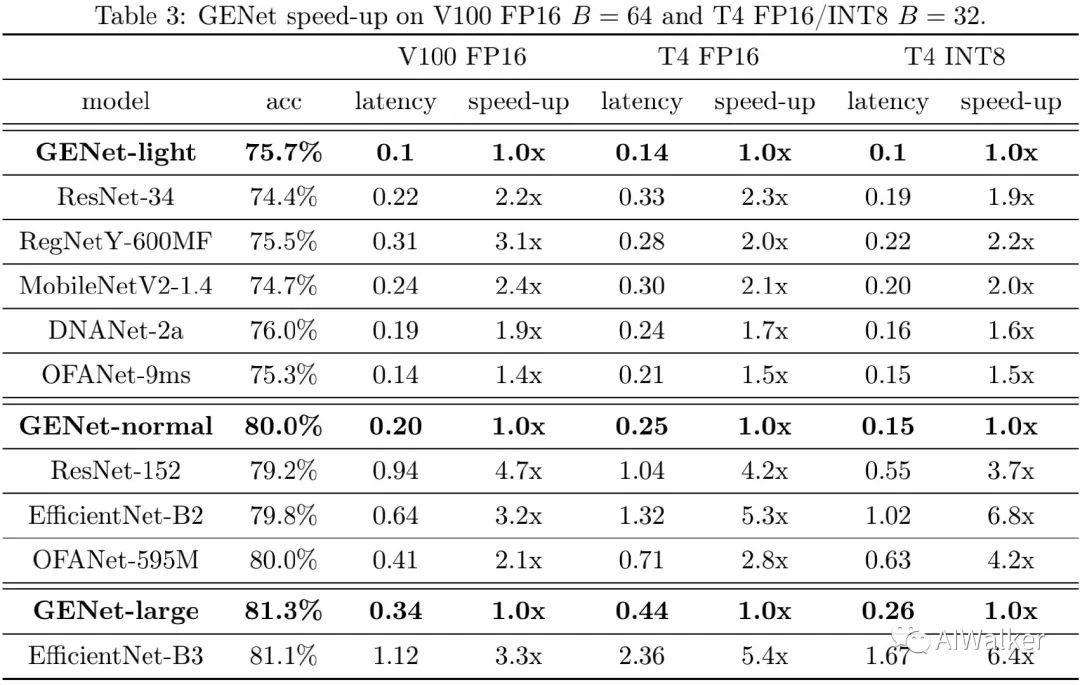
image-20200627202757734
上表给出了不同网络在相似精度下的推理延迟对比,可以看到:(1) 更高精度时,GENet的优势更明显。(2) 除了EfficientNet-B3与GENet-large外,其他网络均无法达到超过81%的指标。(3) 在T4+TensorRT+INT8配置(工业界常见配置)下,GENet-large以6.4倍的速度快于EfficientNet-B3,GENet-normal以6.8倍速度快于EfficientNet-B2,以4.2倍速度u快于OFANet。不同硬件下的精度与速度对比见下面三个图。
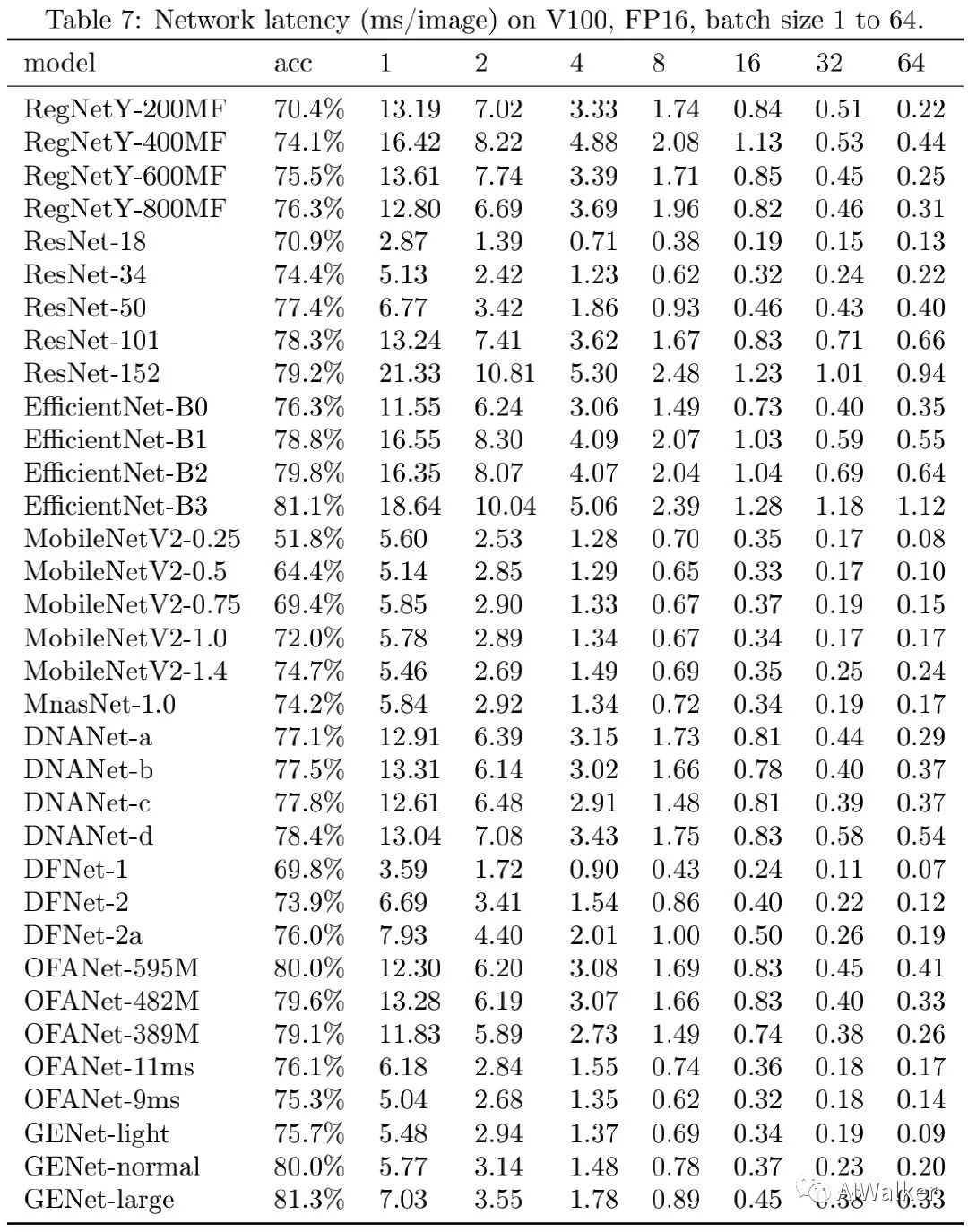
image-20200627203803401
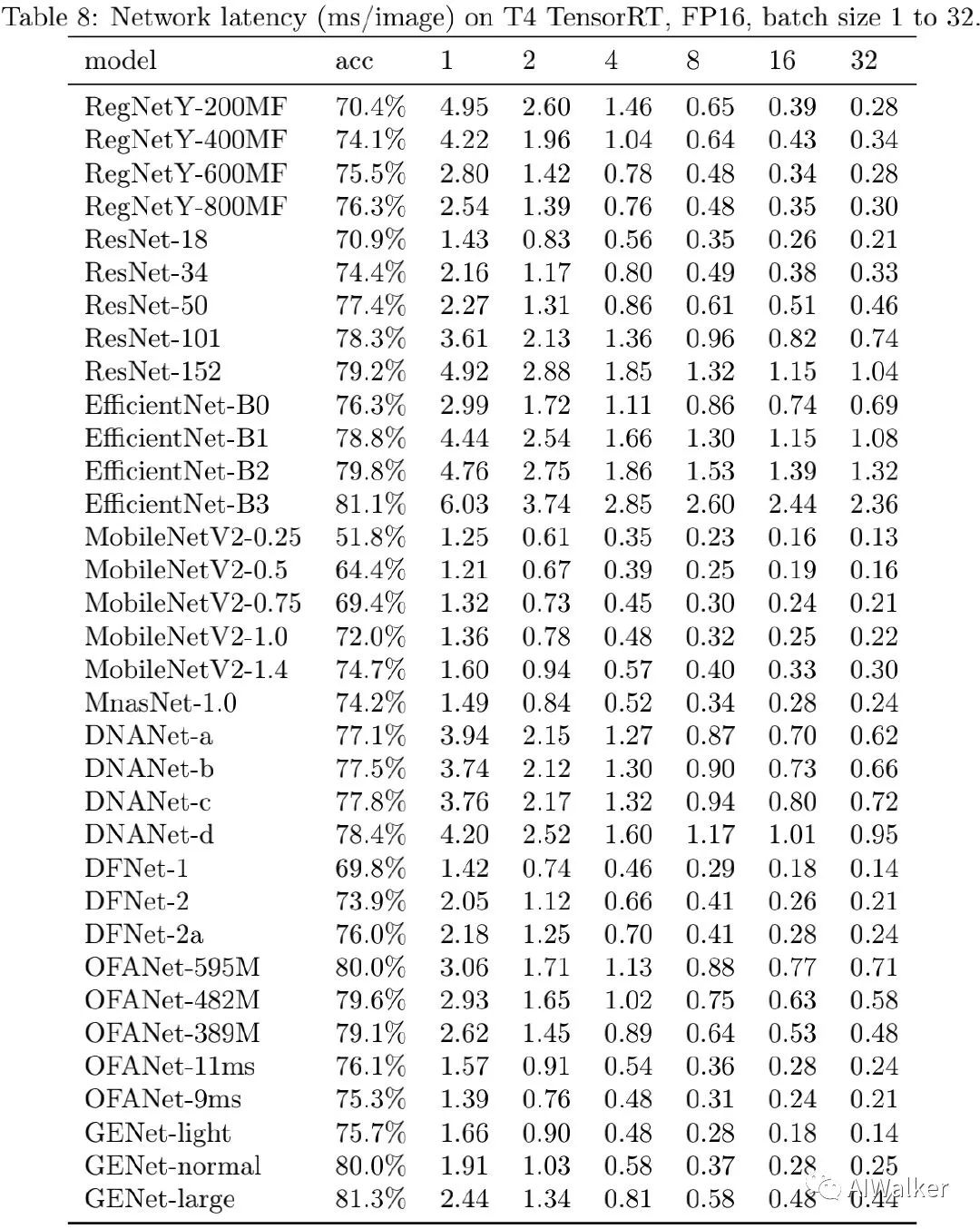
image-20200627203746044
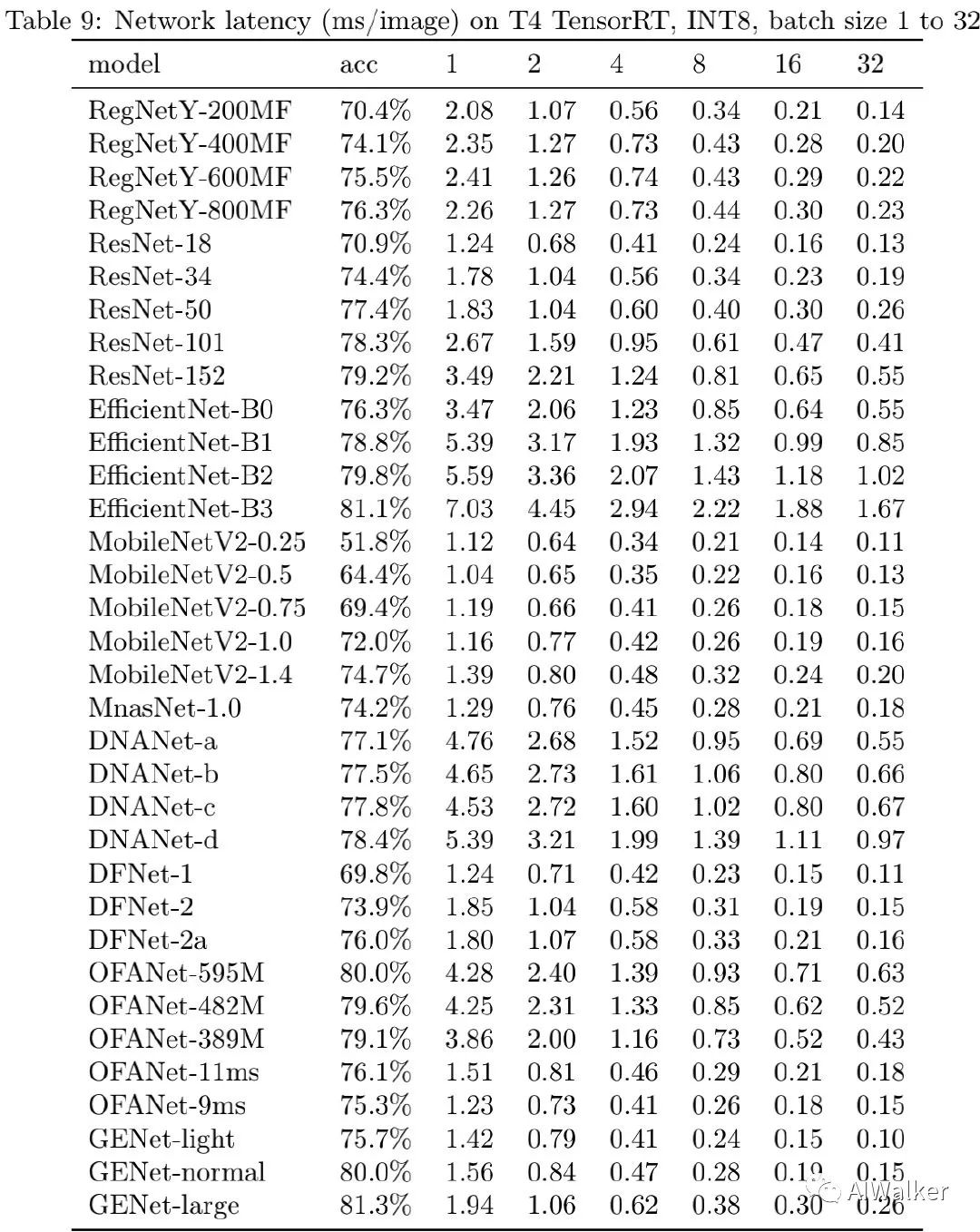
image-20200627203730296
Conclusion
阿里巴巴的研究员提出了一类针对GPU的高效网络架构设计空间,结合该设计空间于半自动NAS技术得到了GPU端高效网络GENet。GENet倾向于在low-level阶段使用全卷积,而在high-level阶段使用深度分离卷积或者Bottleneck结构。
最后作者通过实验证实了所提网络架构设计空间的优异性能,在具有高精度的同时还具有高推理速度,你说气人不人。