
YOLO v4:物体检测的最佳速度和精度
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

您只需看一次(YOLO)是快速、准确的单阶段目标检测器。最近发布的YOLO v4与其他目标检测器相比,显示出非常好的结果。
1 介绍
当今大多数精确模型都需要使用许多GPU进行大mini-batch的训练,使用单GPU训练实际上会使训练变得缓慢且不切实际。YOLO v4目标检测器可以在具有较小mini-batch批处理大小的单GPU上进行训练,使得使用单1080 Ti或2080 Ti GPU训练出超快速和精确的目标检测器成为可能。
YOLO v4在MS COCO数据集上实现了实时检测的最优表现,在Tesla V100上以65 FPS运行,AP达到43.5%。为了获得这些结果,YOLO v4结合了一些功能,例如加权残差连接(WRC)、跨阶段部分连接(CSP)、交叉小批量标准化(CmBN)、自对抗训练(SAT)和Mish激活,Mosaic数据增强,DropBlock正则化和CIoU损失。稍后将讨论这些功能。

将YOLOv3的AP和FPS分别提高10%和12%[5](浅蓝色区域的模型被视为实时目标检测器)
可以看出,EfficientDet D4-D3比YOLO v4具有更好的AP,但是它们在V100 GPU上的运行速度低于30 FPS。另一方面,YOLO能以更高的速度(> 60 FPS)和非常好的精度运行。
2.目标检测器一般架构
尽管YOLO是单阶段目标检测器,但也有两阶段目标检测器,如R-CNN、Fast R-CNN和Faster R-CNN,它们准确但速度慢。我们将专注于单阶段目标检测器,让我们来看看单阶段目标检测器的主要组件:
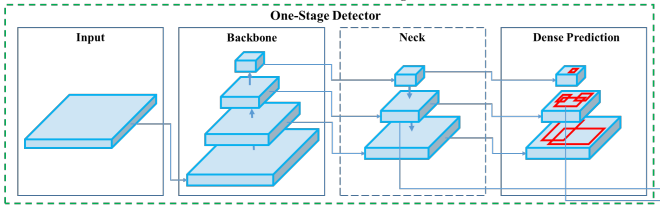
2.1 骨干
骨干网络,如ResNet、DenseNet、VGG等,被用作特征提取器,它们在图像分类数据集(如ImageNet)上进行了预训练,然后在检测数据集上进行了微调。事实证明,这些骨干网络随着层数的加深能产生具有更高语义的不同级别的特征,对之后的目标检测发挥很大作用。
2.2 颈部
颈部在骨干和头部之间的额外层,用于提取骨干网络不同阶段的不同特征图,如FPN [1]、PANet[2]、Bi-FPN[3]。YOLO v3使用FPN从主干中提取不同比例的特征。
什么是特征金字塔网络(FPN)?
通过自上而下的路径和横向连接来增强标准卷积网络,因此该网络可以有效地从单分辨率输入图像构造出丰富的多尺度特征金字塔[4]。
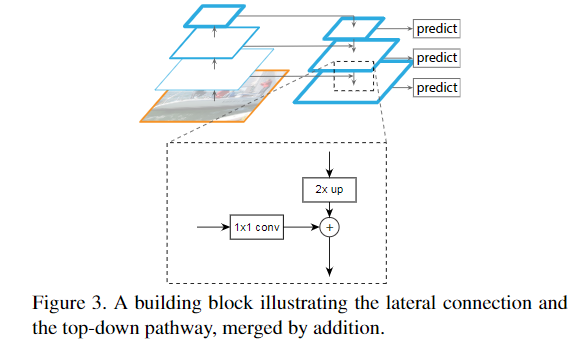
特征金字塔[1]网络用于目标检测
(1)每个横向连接将特征图从下至上的路径合并到自上而下的路径,从而生成不同的金字塔层,在合并特征图之前,对先前的金字塔层进行2倍上采样,使两个特征图具有相同的空间分辨率大小。
(2)然后将分类/回归网络(头部)应用于金字塔的每个层,以帮助检测不同大小的目标。特征金字塔可以应用于不同的骨干模型,例如最初的FPN[1]论文使用ResNets,还有许多以不同方式集成FPN的模块,例如SFAM[7]、ASFF[9]和Bi-FPN[3]。
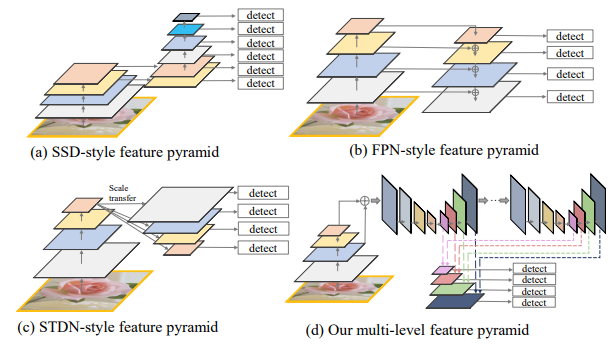
四种类型的特征金字塔。
图像(a)显示了如何在Single Shot Detector体系结构(SSD)中从主干中提取特征,上图还展示了其他三种不同类型的金字塔网络,它们背后的思想与它们的目的相同:缓解目标实例之间比例变化引起的问题[3]。
2.3 头部
实际负责执行边界框检测(分类和回归)的网络。
输出(取决于实现方式):1)4个值描述了预测的边界框(x,y,h,w);2)k类的概率+ 1(背景额外一个)。
像YOLO一样,基于anchor的目标探测器也将头部应用于每个anchor box,其他流行的基于anchor的单阶段检测器包括:Single Shot Detector[6]和RetinaNet[4]。
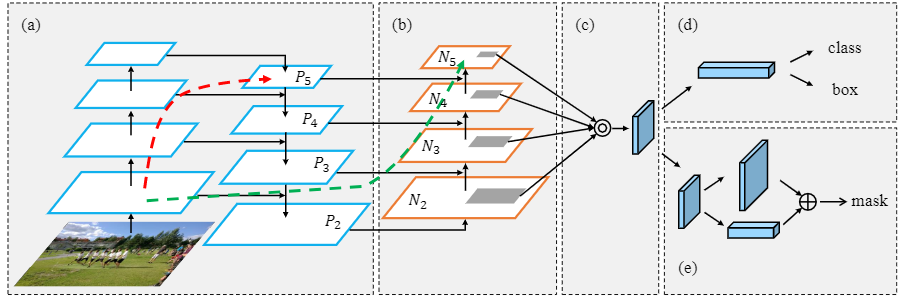
下图结合了上述三个模块:
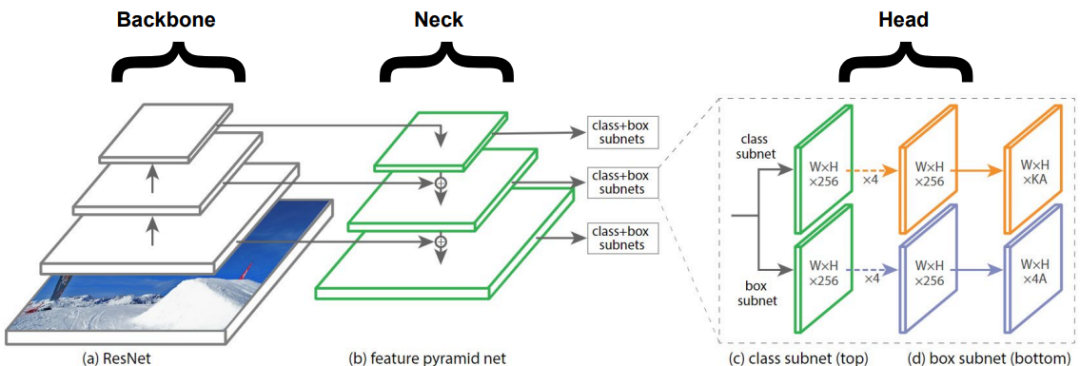
3.BoF&BoS
YOLO v4论文的作者[5]区分了用于提高目标检测器精度的两类方法,分析了这两种类别中的不同方法,以实现具有良好准确性的快速运行的神经网络,这两个类别是:
3.1 Bag of freebies(BOF)
定义:仅改变训练策略或仅增加训练成本[5],使目标检测器获得更准确性而又不增加推理成本。
(1)数据增强:可以提高模型的泛化能力。可以进行光度畸变如:调整亮度、饱和度、对比度和噪点,或者对图像进行几何变形,例如图像旋转、裁剪等。这些技术都是BoF的明显示例,有助于提升检测器的准确性。
几何变形示例(对于对象检测任务,边界框也应用相同的转换)
其他有趣的技术可以增强图像:1)CutOut[8]可以在训练过程中随机掩盖输入的正方形区域,可以提高CNN的鲁棒性和性能。2)类似地随机擦除[10]选择图像中的矩形区域并使用随机值擦除其像素。

用于目标检测的随机擦除示例
(2)避免过度拟合的正则化技术:如DropOut、DropConnect和DropBlock [13]。最后一个实际上在CNN中表现出非常好的结果,并用于YOLO v4主干中。

来自DropBlock论文
(3)回归网络的损失函数:传统的做法是应用均方误差对坐标进行回归,如本文所述将这些点视为独立变量,但未考虑对象本身的完整性。
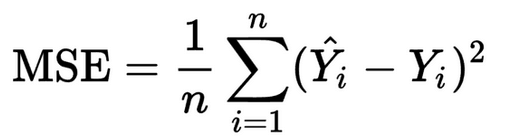
IoU [12]损失:考虑了预测边界框(BBox)和真实边界框的面积。
GIoU[11]损失:除了考虑覆盖区域之外,还考虑了对象的形状、方向、重叠区域和中心点之间的距离和宽高比。YOLO v4使用CIoU损失作为边界框的损失,主要是因为与上述提到的其他损失相比,它导致更快的收敛和更好的性能。
(注意:可能引起混乱的一件事是,尽管许多模型将MSE用于BBox回归损失,但它们使用IoU作为度量标准,而不是如上所述的损失函数。)下图比较了具有不同IoU损耗的相同模型:
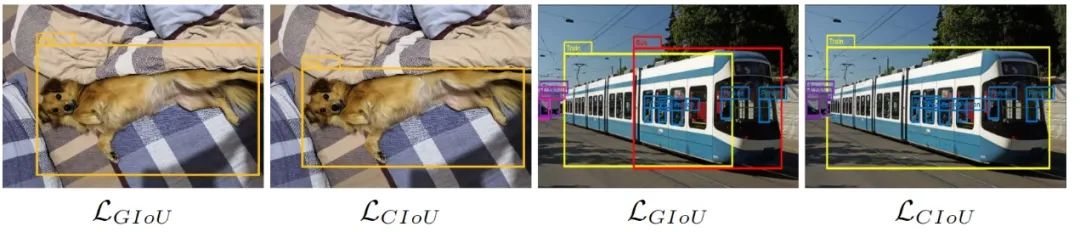
损失比较
上述检测来自Faster R-CNN(Ren等人,2015),该数据在相同的MS COCO数据集上训练,并带有GIoU和CIoU损失。可以注意到CIoU的性能要优于GIoU。
3.2 Bag of specials(BOS)
定义:仅会增加少量推理成本,但可以显著提升目标检测器准确性的插件模块和后处理方法[5]。此类模块/方法通常包括:引入注意力机制(SE模块与SAM模块)、扩大模型的感受野范围并增强特征集成能力等。
(1)引入注意力机制:主要是channel-wise注意力(如挤压与激励模块SE)和point-wise注意力(如空间注意力模块SAM)。YOLO v4选择了空间注意力模块SAM,但与该模块的最初发布版本不完全相同,请注意以下几点:
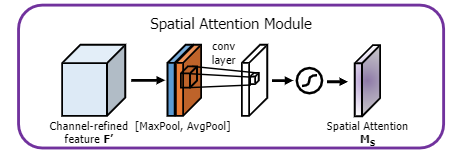
原始空间注意模块[16]
原始SAM:给定一个特征图F',沿通道执行平均池化和最大池化操作,并将它们串联起来,然后应用卷积层(包含S型激活函数)生成注意力图(Ms),并将其应用于原始F'。

YOLO v4修改的空间注意模块,来源[5]
YOLO v4修改的SAM:不应用最大池化和平均池化,而是F'通过卷积层(包含S型激活函数)得到的结果与原始特征图(F')相乘。
(2)改善感受野:常用模块是SPP,ASPP和RFB(YOLO v4使用SPP)。早先讨论过的特征金字塔(如SFAM[7],ASFF[9]和Bi-FPN[3])也属于BoS。
(3)激活函数:自ReLU问世以来,它已经有很多变体,如LReLU、PReLU和ReLU6。ReLU6和hard-Swish之类的激活函数是专门为压缩网络设计(用于嵌入式设备),如Google Coral Edge TPU。YOLO v4 在主干中使用了很多Mish [14]激活函数:
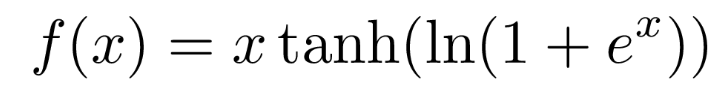
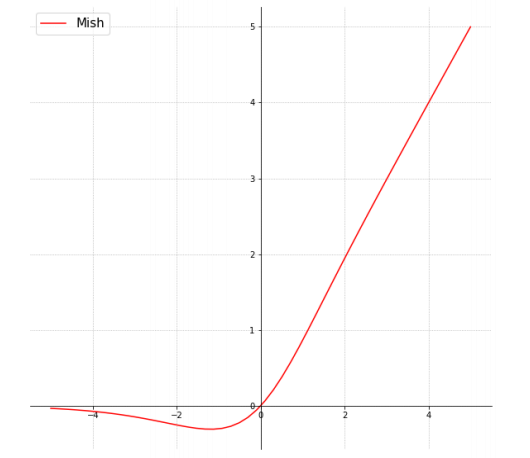
来源[14 ]
事实证明该激活函数显示出非常好的结果。如与使用Swish或ReLU激活函数的Squeeze Excite网络(CIFAR-100数据集)Mish激活函数分别使得测试精度提升0.494%、1.671%[14]。
其他一些图形化的激活函数参考:https://www.desmos.com/calculator/rhx5tl8ygi
4.YOLO v4设计
已经讨论了用于提高模型精度和目标检测器不同部分(骨干、颈部、头部)的方法。现在我们讨论一下YOLO中使用的新内容。
(1)骨干:CSPDarknet53用作GPU版本的特征提取网络。对于VPU(视觉处理单元),他们考虑使用EfficientNet-lite — MixNet — GhostNet或MobileNetV3。我们重点介绍GPU版本。
下表显示了适用于GPU版本的不同候选的主干

来源[5]
某些主干与检测相比更适合分类。对于检测CSPDarknet53优于CSPResNext50,对于图像分类,CSPResNext50优于CSPDarknet53。如本文所述用于目标检测的骨干模型需要更大的输入网络大小(以便对小目标也能进行更好的检测)、更多的层(得到更大的感受野)。
(2)颈部:使用空间金字塔池(SPP)和路径聚合网络(PAN)。
路径聚合网络(PAN):与原始PAN不同,修改后的版本用concat代替addition操作,如下图
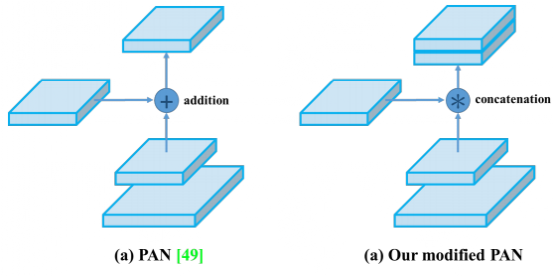
来源[5]
最初PAN将N4的尺寸减小到与P5相同的空间尺寸后,将这种缩小的N4与P5 相加,在所有Pi+ 1和Ni上重复此操作。在YOLO v4中,不是将Pi+1 和Ni加起来,而是concatenate连接起来(如上图所示)。
路径聚合网络(PAN)源[2]
空间金字塔池(SPP):它使用不同的核大小k = {5,9,13}、same填充在19 * 19 * 512的特征图上执行最大池化,然后将四个对应的特征图连接起来形成19 * 19 * 2048的特征图,这增加了颈部的感受野,在推理时间可以忽略不计的情况下提高了模型准确性。
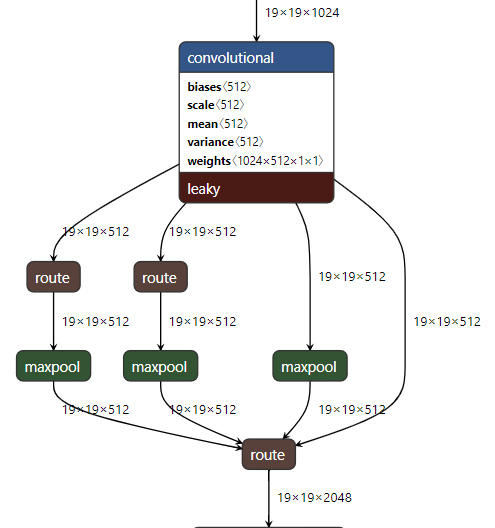
在yolov4.cfg中观察到的SPP
如果您想可视化显示 yolo中使用的不同层(如上图所示),建议使用https://github.com/lutzroeder/netron(可以使用Web /桌面版本),然后使用它打开yolov4.cfg。
(3)头部:用法与YOLO v3相同。
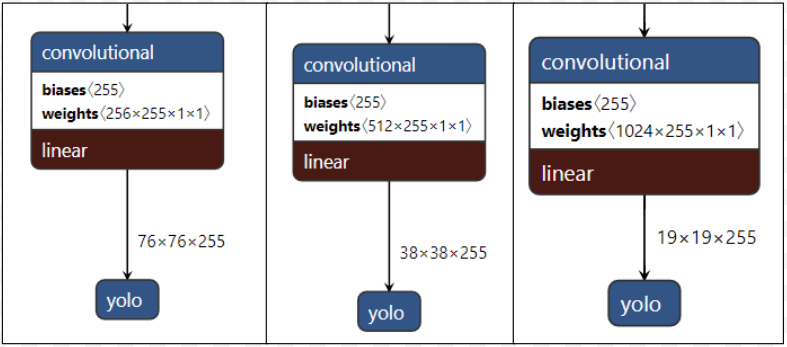
应用在不同尺度的YOLO头部
头部应用在网络的不同尺度特征图,用于检测大小不同的物体通道数为255,因为(80个类别 + 1个对象 + 4个坐标)* 3个锚点。
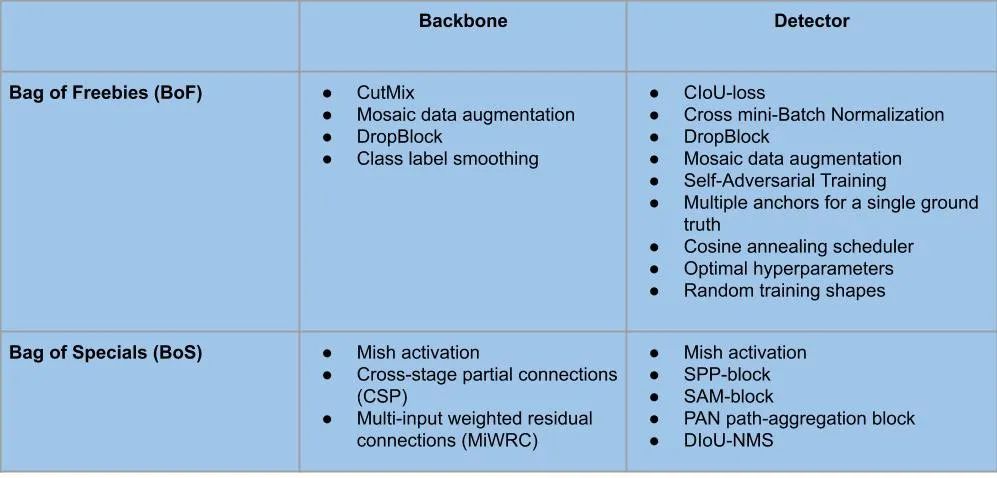
5. BoF&BoS使用总结
骨干和YOLO v4检测器中使用的BoF和BoS的不同模块/方法可以总结如下:
6. 其他改进
(1)使用“Mosaic”的数据增强新方法:将训练数据集的4张图像合并为1张图像:批量归一化从每层的4张不同的图像计算激活统计信息[5],因此极大地减少了选择大型mini-batch批量进行训练的需求。

来自[5]的Mosaic数据增强

示例:用于车牌检测的Mosaic增强
(2)使用自对抗训练(SAT):该训练分为两个阶段,第一阶段:神经网络更改原始图像,而不是网络权重,以这种方式神经网络对其自身执行对抗攻击,从而改变原始图像以产生对图像上没有所需物体的欺骗。第二阶段:训练神经网络以正常方式检测此修改图像上的对象。[5]
7. Colab Demo
我制作了一个Colab,您可以在自己的视频中测试YOLO v4及其微型版本,它使用了在MS COCO上训练的模型。地址为:https://colab.research.google.com/drive/1PuI9bYeM8O1OA82pI12oGopRJJrLWfs9?usp=sharing
8. 结论
更多详细信息参考https://arxiv.org/abs/2004.10934。如果您想在自己的数据集上进行训练,请查看官方仓库https://github.com/AlexeyAB/darknet。
YOLO v4达到了用于实时目标检测的最新结果(AP为43.5%),并且能够在V100 GPU上以65 FPS的速度运行。如果您想降低精度但要提高FPS,请在官方仓库中查看新的Yolo v4 Tiny版本https://github.com/AlexeyAB/darknet。
参考
[1] Feature Pyramid Networks for Object Detection
[2] Path Aggregation Network for Instance Segmentation
[3] EfficientDet: Scalable and Efficient Object Detection
[4] Focal Loss for Dense Object Detection
[5] YOLOv4: Optimal Speed and Accuracy of Object Detection
[6] Single Shot MultiBox Detector (SSD)
[7] A Single-Shot Object Detector based on Multi-Level Feature Pyramid Network
[8] Improved Regularization of Convolutional Neural Networks with Cutout
[9] Learning Spatial Fusion for Single-Shot Object Detection
[10] Random Erasing Data Augmentation
[11] Generalized Intersection over Union: A Metric and A Loss for Bounding Box Regression
[12] UnitBox: An Advanced Object Detection Network
[13] DropBlock: A regularization method for convolutional networks
[14] Mish: A Self Regularized Non-Monotonic Neural Activation Function
[15] Squeeze-and-Excitation Networks
[16] CBAM: Convolutional Block Attention Module
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~